
Abstract
BEiT는 Masked Image Modeling Task로 Pre-Train되는 ViT이다. (BETR에서 영감을 받았다)
1.
원본 이미지를 Visual Token으로 토큰화한다.
2.
특정 이미지 Patch를 Masking한 다음에 Backbone Transformer에 넣는다.
3.
Masked Image로 부터 Origin Visual Token을 복구하도록 학습시킨다.
4.
Pretrained Encoder에 Task Layer를 추가해서 DownStream Taks를 수행한다.
5.
이 방법으로 Image Classification & Semantic Segmentation에서 SOTA급 성능을 보였다.
Introduction
Vision Transformer
1.
Vision Transformer는 강력하지만 데이터가 더 많이든다.
2.
데이터가 부족할 땐, Self-Supervised Pre-Train이 확실한 방법이다.
3.
관련 연구가 최근까지 이루어졌다.
BERT
1.
BERT는 NLP에서 큰 성공을 거둔 모델이다.
2.
특정 Token들을 랜덤하게 Mask하고 모델이 복구하는 방식으로 Pre-Train한다.
3.
그러나 이미지 데이터를 BERT처럼 모델링하는건 쉽지 않은 일이다.
4.
이미지는 Input의 최소 단위(Patch)에 대한 Vocab이 없어 Classification으로 모델링 할 수 없다.
5.
따라서 Regression으로 모델링 해야 하는데, Pixel 단위 Regression은 Capacity의 낭비가 크다.
BEiT
1.
BEiT의 목표는 상술한 Pre-Train Task Issue를 극복하는 것이다.
2.
BERT에서 영감을 받은 Pre-Train Task인 MIM(Masked Image Modeling)을 사용한다.
3.
MIM는 Image를 Patch, Visual Token 두 가지 버전으로 사용한다.
4.
Patch는 Input Image를 Grid로 나눈 것이고, Visual Token은 Discrete VAE를 통해 얻어진 것이다.
5.
Pre-Train은 Patch들 중 일부를 Mask해 Raw Pixel대신 Token으로 복구하는 식으로 이루어진다.
Contribution
1.
ViT를 Self-Supervised로 Pre-Traing하는 방법인 MIM을 제안했으며, VAE도 이론적으로 설명했다.
2.
BEiT로 DownStram Taks(Classification, Segmentation) Fine Tuning을 수행했다.
3.
BEiT의 Self-Attention이 Annotation없이도 영역과 경계를 나누는것을 보였다.
Conclusion
Classification과 Segmentation에서 강력한 ViT Self-Supervised Framework BEiT 를 만들었다. BERT Style(Masked) Pre-Train이 ViT에서도 잘 작동한다는것을 보여주었으며, Human Annotation 없이도 의미에 따라 영역을 나누는 방법을 배울수 있음을 확인했다. 다음 관점에서 후속 연구가 이루어질 수 있으리라 기대한다. (1)BERT 처럼 BEiT도 Data, Model Size를 키운다. (2)Text, Image를 Multi-modal로 학습시킨다
Figures
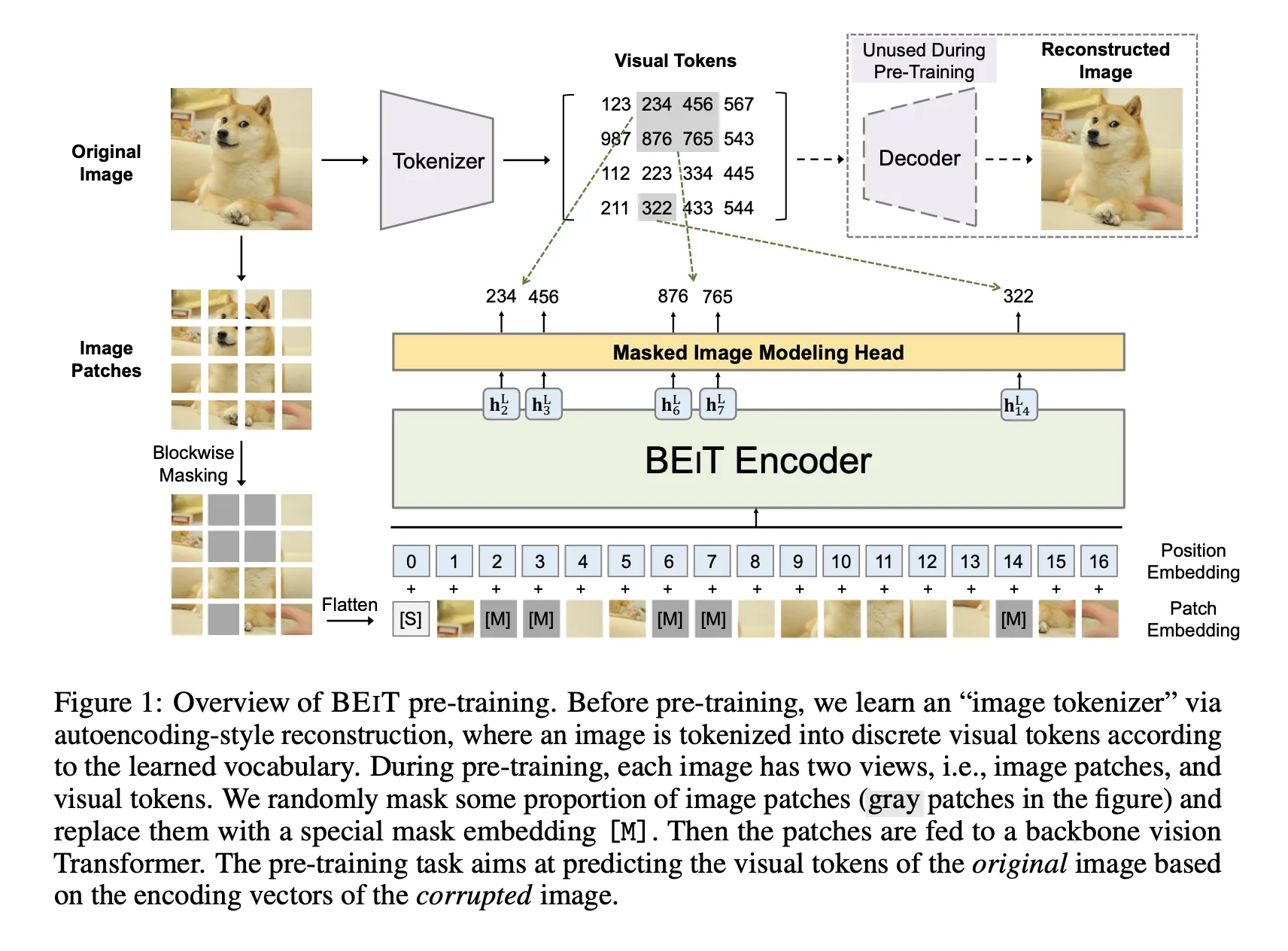
Summary
1. Methods

Image Representation
BEiT 에서 이미지는 2가지 방법으로 표현된다. 1) Image Patch(Input) , 2) Visual Token(Output)
Image Patch
1.
일반적인 ViT 방법론처럼 해상도로 나누고 Linear Embedding을 적용한다.
2.
BEiT 원본에선 224x224 Image를 P=16으로 나눠 14x14 Grid로 Patch를 만들었다.
Visual Token
•
NLP처럼, 이미지를 Discrete한 Token의 시퀀스로 표현한다.
•
Raw Pixel에서 Image Tokenizer로 Visual Token을 얻는다.
•
→ 로 변환된다.
Tokenizer(dVAE)
1.
Tokenizer는 dVAE로 학습되며 Tokenizer, Decoder 두 개의 모듈로 이루어져 있다.
2.
Tokenizer 는 이미지 를 Visual Code Book에 따라 token 로 변환시킨다.
3.
Decoder 는 Token 를 받아 를 Reconsturt하는 방법을 배운다.
4.
Token이 Discrete해서 미분이 불가능하므로 Gumbel-Sotfmax Relaxation을 이용했다.
5.
(당연하지만) Token 갯수는 Patch와 같은 갯수로 맞췄다
6.
Vocab Size는 8192로 설정했으며, DALL-E의 Tokenizer를 바로 사용했다.
Backbone Network : Image Transformer
1.
ViT처럼 Standard Transformer를 Backbone으로 사용했다.
2.
Special Token [S] 를 Sequence 맨 앞에 넣어주었다.
3.
Positional Embedding은 표준 1D 방법을 사용했다.
Pre-Training BEiT : MIM(Masked Image Modeling)
What is this?
1.
MIM는 BEiT를 Pre-Train을 하기위한 Task이다.
2.
Image Patches의 일부(약 40%)를 랜덤하게 Mask하고 대응되는 Token idx를 복구하도록 학습시킨다.
3.
Mask되면, Learnable Embedding 으로 대체되어 Transformer로 들어간다.
4.
Transformer를 거치고 나면 Masked Patch에 대해 Softmax를 한다.
5.
대응되는 Token idx와의 Log-Likelihood를 극대화시키는게 학습 목표이다.
Blockwise Masking
1.
BEiT Random하게 Mask할 Patch를 고르지않고 에선 Blockwise Masking이라는 방법을 쓴다.
(여기서 Block은 이미지 영역(Block)을 의미한다)
2.
각 Block에 들어갈 Patch의 최소 갯수를 16개로 두고, Block의 가로,세로 비율이 무작위로 설정된다.
3.
위의 두 단계를 Masked-Patch의 비율이 40%가 될때까지 반복한다.
Inspiration
1.
MIM은 NLP에서 많은 영감을 얻었고, Blockwise는 BERT-Like 모델에서 광범위하게 사용되고 있다.
2.
이 두 방법을 직접 Pixel Level에 사용하면 여러 문제가 생기는데 BEiT 는 그 문제 해결에 집중했다.
From the Perspective of VAE
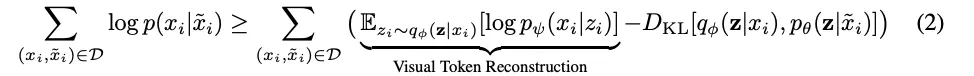
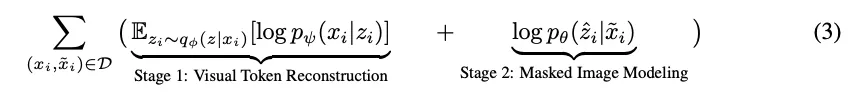
1.
BEiT의 Pre-Train 과정은 VAE를 Train하는것으로 볼 수 있다.
2.
수식 (2) : [ : Image, : Masked Image, : Token] 으로 Notation한 ELBO의 수식이다.
3.
BEiT는 2-Stage Procedure를 거치는데
(1) Reconstruction Loss를 먼저 줄이고 (2) Tokenizer와 Decoder를 고정하고 를 학습시킨다.
4.
수식 (3) : Tokenize와 Decoder는 가져왔으므로 Stage2 Term이 BEiT의 Pre-Train Objective다.
BEiT Pre-Train Step
1.
공평한 비교를 위해 ViT-B의 구조를 따랐으며 Tokenizer는 DALL-E 것을 가져왔다.
2.
Dataset은 ImageNet-1K, Aug는 Random Size Crop, Horizontal Flip, Color Jitterring을 사용했다.
3.
224x224 ⇒ 14x14 Patch로 나눴으며 40%의 Patch를 Mask했고, 0.1 Stochastic Depth를 사용했다.
4.
Batch size 2000, Epoch 800, Adam()를 사용했으며 lr = 1.5e-3,
10 Epoch WarmUp, Cosine Decay를 사용했다.
5.
V100 16개로 5일 걸렸다.
Fine-Tuning BEIT on Downstream Vision Task
Classification : Average Pooling + Linear + Softmax Layer를 추가했다.
Semantic Segmentation : SERT-PUP의 Task Layer를 가져왔다.
Intermediate Fine-Tuning :
Self-Supervised Train을 마치고 DataRich Dataset(여기선 ImageNet-1K)로 라벨과 함께 추가 훈련하는 것이다. BERT Fine-Tuning에서 일반적인 관행이며 BEiT도 이를 따른다.
Experiment
Classification
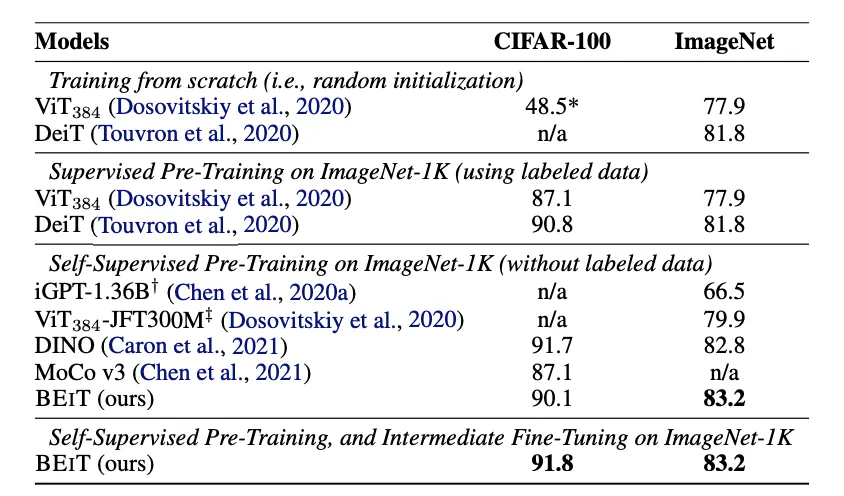
Small Datset & Small Resolution : ImageNet & CIFAR
공정한 비교를 위해 BEiT도 DeiT에서 사용하는 Hyper-Parameter를 사용했다.
1.
CIFAR : 작은 데이터셋에서 ViT는 제대로 작동하지 않는데, BEiT는 훌륭하다.
2.
ImageNet : Comparision대비 Rich-Resource없이도 강력한 성능을 보인다.
3.
vs Self-Supervised :
iGPT는 1.36B개의 파라미터를 썼음에도 BEiT가 압도해버린다.
ViT-JFT300M은 훨씬 큰 Corpus(300M vs 1.3M)를 썼음에도 BEiT가 압도해버린다.
4.
vs SOTA :
DINO, Moco v3가 Self-Supervised의 SOTA인데 BEiT가 ImageNet 에서 압도한다.
Intermediate Fine-Tuning을 하면 Dataset 상관없이 강력하다.
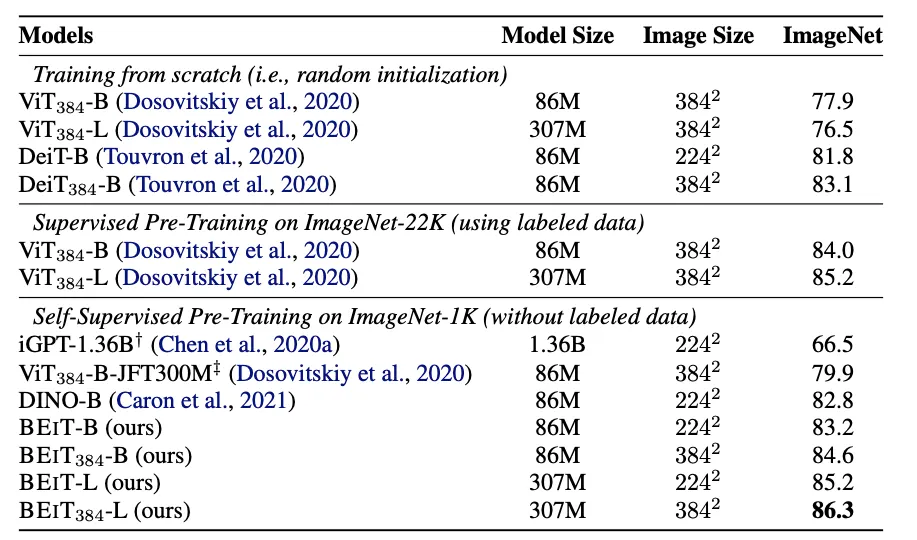
Bigger Dataset & Bigger Resolution
224 Resolution에 대해 Fine-Tuning을 마치고, 384 Resolution에 대해 10 Epoch더 학습시킨 결과다.
1.
Patch-Size : Resolution이 늘어나면 Patch-Size는 그대로 두고 Sequence 길이를 늘린다.
2.
BEiT : ImageNet에서 Accuracy가 1% 증가했다. ViT+ImageNet-22k를 압도했다.
3.
BEiT-L : ViT-L처럼 모델 Scale을 키웠다. 모델의 크기가 커질수록 BEiT의 성능 향상폭이 절대적으로
+ ViT와 비교해서도 늘어나는데, 이는 큰 모델에 대해 Self-Supervised가 도움이 되는 것을 보여준다.
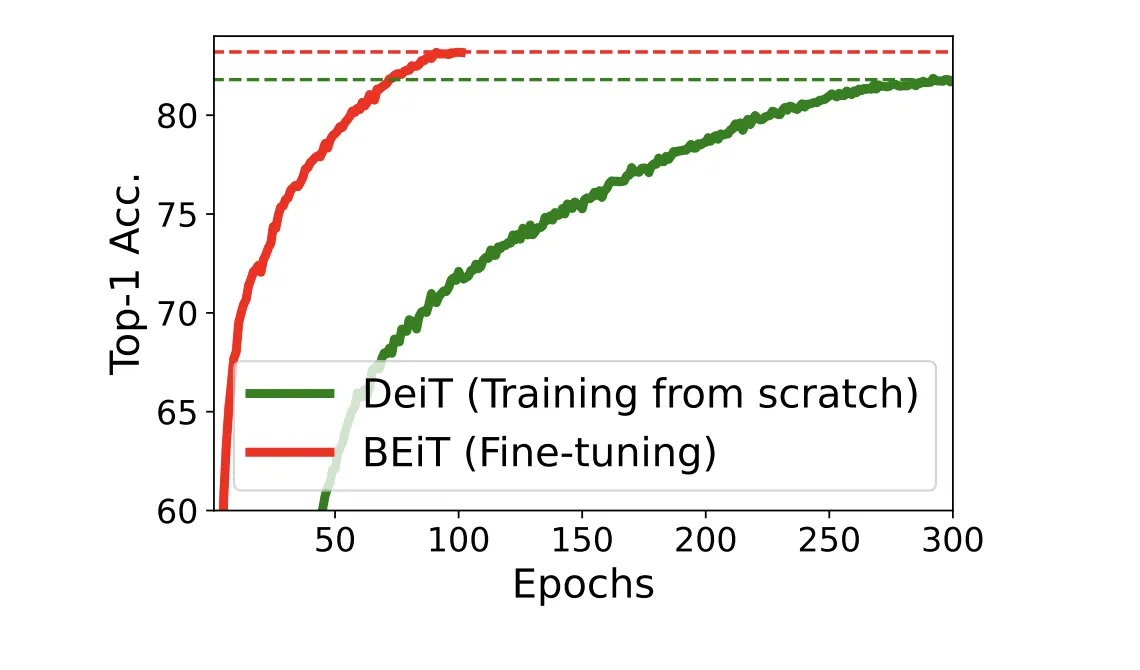
수렴또한 Fine-Tuning 방식이 Comparision(DEiT)에 비해 압도적으로 빠른 것을 볼 수 있다.
Ablation Study
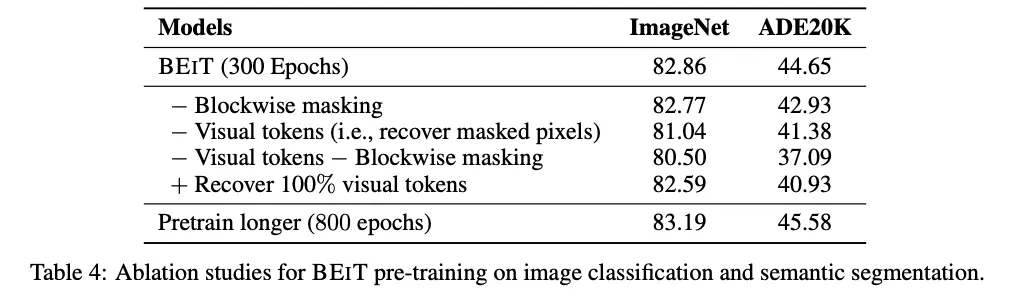
1.
Blockwise : Block → Random으로 바꿀 경우 Classificaiton, Segmentation 성능이 소폭 하락한다.
2.
Visual Token : Discrete → Regression으로 바꿀 경우 성능 하락폭이 크다.
3.
둘 다 제거 : Segmentation에서 심각하게 성능이 하락한다. Blockwise가 Pixel 에서도 유용하다
4.
Pre-Train Longer : Pre-Train을 더 오래하면 DownStream Task에서도 성능이 향상된다.
다음 질문에 답해보세요.
What did the author(s) try to accomplish?
•
NLP에서 Self-Supervised Pre-Train → Fine-Tune 의 한 획을 그은 BERT를 ViT에도 적용하려 했다.
What were the key elements of the approach?
1.
MLM Task에서 영감받은 MIM Task
2.
MIM Task에서 랜덤하게 Mask하는 대신 Block단위로 Mask하는것
3.
Pixel Level Recovery가 아니라, dVAE형식으로 Patch를 Tokenize해 Recover 한것
What can you use yourself?
•
BERT 처럼 일단 BEiT를 써보는 방식의 Backbone선택이 가능할지도 모르겠다.
What other references do you want to follow?
1.
dVAE와 ELBO는 몇번봐도 잘 모르겠음
2.
DALL-E가 어떤식으로 Tokenize한지 궁금함