
Abstract
1.
CV Task에서 CNN은 믿고쓰는 모델이다. 최근엔 ViT같은 Attention 모델도 인기가 많다.
2.
두 Layer 다 충분히 좋지만, 사실은 저 둘도 반드시 필요하진 않다는걸 MLP-Mixer를 통해 보인다.
3.
MLP-Mixer는 Patch와 Channel을 Mix하는 두 가지 MLP로만 이루어져 있는 모델이다.
4.
큰 Dataset과 Regularization Scheme이면 Image Classification BenchMark에서 SOTA급이다.
Introduction
MLP-Mixer
1.
MLP-Mixer(이하 Mixer)는 Conv도, Self-Attention도 없는 간단한 모델이다.
2.
Mixer는 MLP를 Spatial, Channel에 대해 반복적으로 적용하는 모델이다.
3.
모델이 행렬곱, Reshape, Transpose, Non-Linearity로만 이루어져 있다.
Simple but, Strong
1.
이런 간단한 구조임에도 Accuracy/Cost Trade-off 관점에서 아주 강력한 모델이다
2.
ImageNet Top-1 87.94% 달성했으며 10M Images, Regulazation과 함께면 강력한 성능을 보인다.
3.
다만 ViT와 같이 Specialized CNN보단 조금은 약한 성능을 보인다.
Conclusion
MLP-Mixer는 간단하지만, 강력한 성능을 보인다. 이는 Train, Inference에 드는 Resource와 Accuracy간 Trade-Off 관계를 생각했을때 굉장한 이점이 있다. 이 연구가 다양한 주제거리를 남겼음을 믿는다. 예를 들어, Pracital Side에서 보면 Layer의 종류 (CNN, Transformer..)에 따라 모델이 학습하는 Feature의 차이에 대해 연구해볼 수도 있다. Theroetical Side에서 보면 이런 Feature에 숨겨진 Inductive Bias와 그들의 역할에 대해 연구해볼 수 있다.
Summary
Deep Vision Architecture
Deep Vision Architecture는 3가지 방법으로 Feature를 섞는다. (1) 주어진 공간 위치의 Feature를 섞거나, (2) 다른 공간과의 Feature를 섞거나, (3) 앞의 2개를 동시에 하거나.
1.
CNN
a.
Conv나 Pooling()으로 (2)다른 공간과의 Feature를 섞는다.
b.
Conv로 (1)주어진 공간 위치의 Feature를 섞는다
c.
큰 Kernel은 (3)앞의 2개를 동시에 한다.
2.
Attention-Based
a.
Self-Attention이 (3)2개를 동시에 한다.
b.
MLP-Block이 (1)주어진 공간 위치의 Feature를 섞는다.
3.
Mixer
a.
Mixer의 기본 아이디어는 (1), (2)를 명확히 분리하는 것이다.
b.
Channel-Mixing이 Per-Location으로 (1)주어진 공간 위치의 Feature를 섞는다.
c.
Token-Mixing이 Cross-Location으로 (2)다른 공간과의 Feature를 섞는다.
Mixer Architecture

1.
Patch Partition & Projection
a.
Input을 개의 겹치지 않는 Patch로 만들고, 각각을 dimension으로 Projection한다.
b.
이때 모든 Patch는 동일한 Projection Matrix를 통해 Projection된다. (Dense)
c.
의 결과물을 얻는다.
2.
Mixer Layer
a.
동일한 Size의 여러 Layer로 이루어져 있으며, 각 Layer는 2개의 MLP Block을 갖고 있다.
b.
첫 Block은 Token-Mixing MLP이며, 차원에 대해 →매핑을한다.
c.
뒷 Block은 Channel-Mixing MLP이며, 차원에 대해 →매핑을한다.
d.
이때 MLP의 가중치는 각 입력에 대해 공유된다 (모든 Token이나 Channel에 동일한 가중치를 사용)
3.
MLP Block
a.
2개의 Fully Connected Layer로 이루어져 있다.
b.
Mixing하는 차원수는 튜닝이 가능하며 FC Layer의 가중치는 그때의 입력에 대해 공유된다.
c.
Channel-Mixing에서 Sharing하는건 Locality, Position-Invariance를 떠올리면 자연스럽다.
d.
Token-Mixing에 대해 공유하는건 덜 흔한일이긴 한데, Depth-Wise Conv와 유사하다.
4.
Parameter Tying
a.
입력에 대해 가중치를 공유하는것을 말한다.
b.
이를 통해 메모리를 절약할 수 있으며, 놀랍게도 이 방법을 사용해도 경험적으로 성능의 차이가 없다.
c.
구현할때 Dense를 사용하면 당연하게 이렇게 구현된다.
5.
나머지 Feature
a.
Skip-Connection, LayerNorm등의 표준 테크닉을 사용했다.
b.
Positional Embedding을 안쓰는데, Token-Mixing MLP가 이미 순서에 민감하기 때문이다.
c.
Classfication Head도 Global Average Pooling과 Linear Classifier의 표준 구조를 사용한다.
Experiment
목표는 SOTA를 만드는 것이아니라, MLP-Based 모델이 최신의 Convolution & Attention Based 모델 대비 경쟁력이 있다는걸 보여주는 것이며 3가지 주요 관심사 (1)Downstream Task Accuracy (2)Pre-train cost (3)Test-time throughput를 중심으로 실험한다.

Downstream Tasks
1.
2012ImageNet(1.3M Train, 1k classes) + original valid label, ReaL Label
2.
CIFAR-10/100(50k examples, 10/100 classes)
3.
Oxford-IIIT Pets & Oxford Flowers-102
4.
VTAB-1k
Pre-training : 2021ImageNet, ImageNet-21k, JFT-300M
Main Results

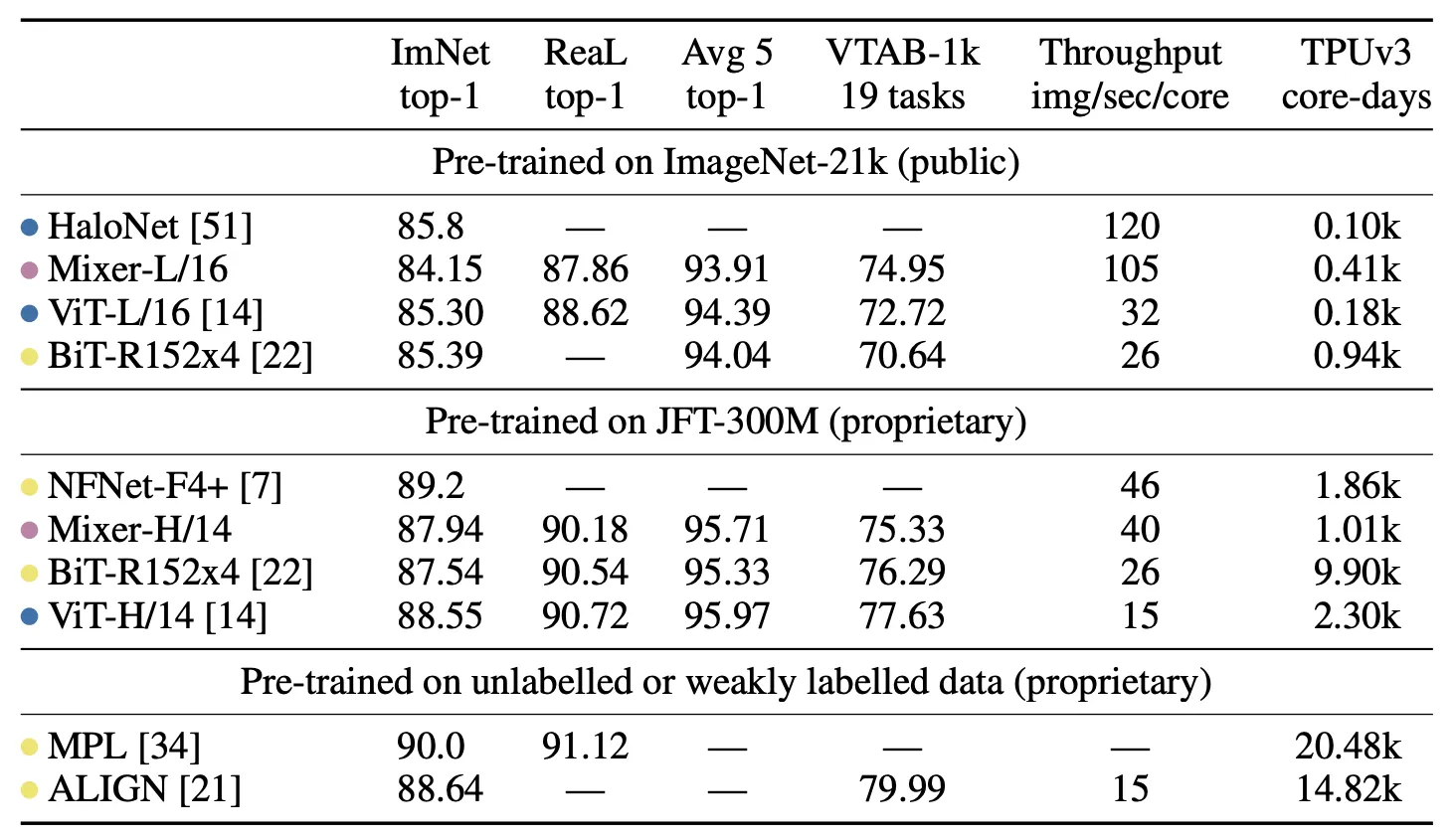
Purple = MLP Based, Yellow = Convolution Based, Blue = Attention Based
1.
ImageNet-21k : Mixer의 성능이 나쁘진 않지만, 다른 모델과 비교하면 부족하다. ViT처럼 Regularzation 없으면 오버피팅된다. 추가로 Mixer-B/16은 76.4%로 ResNet50과 유사한 성능을 보였다. 그러나 SOTA급 CNN/Hybrid에서 얻을수 있는 84.7(BoTNet) / 86.5(NFNet) 등에 비하면 많이 떨어진다.
2.
JFT-300M : 데이터셋이 커지면 Mixer의 성능이 급격히 상승한다. 동급의 성능을 내는 ViT, CNNs 모델대비 훨씬 가볍고 빠르다. 게다가 우리의 목적은 Mixer의 경쟁력있는 성능을 보는것이기에, Cost-Performance Trade off 관점에서 훌륭하다.
The Role of the Model Scale
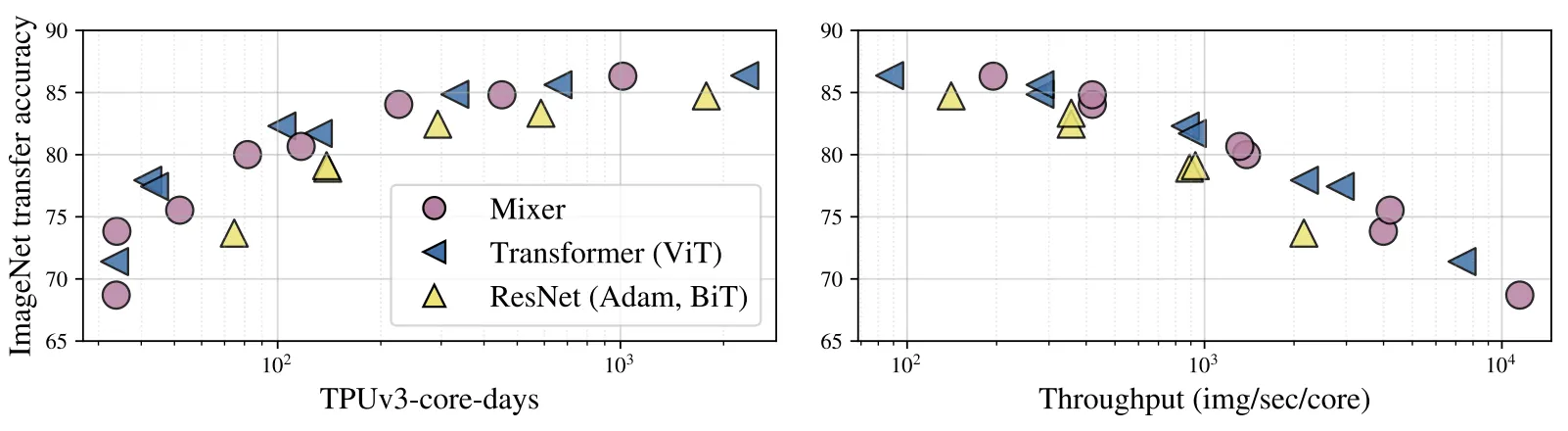

2가지 방법으로 Scaling했다 (1) Pre-Train의 Model Size 키우기, (2) Fine-Tuning의 Resolution 키우기.
전자는 Pre-train cost와 test-time throughput 모두 영향을 미치고, 후자는 throughput에만 영향을 미친다.
Scale이 작을땐 Mixer가 상대적으로 낮은 성능을 보이지만, Scale이 커짐에따라 SOTA급 성능에 가까워진다.
Invariance to Input Permutations
Mixer와 CNN간의 Inductive Bias 차이를 연구하기위해 Input Permutation에 대한 실험을 진행했다.
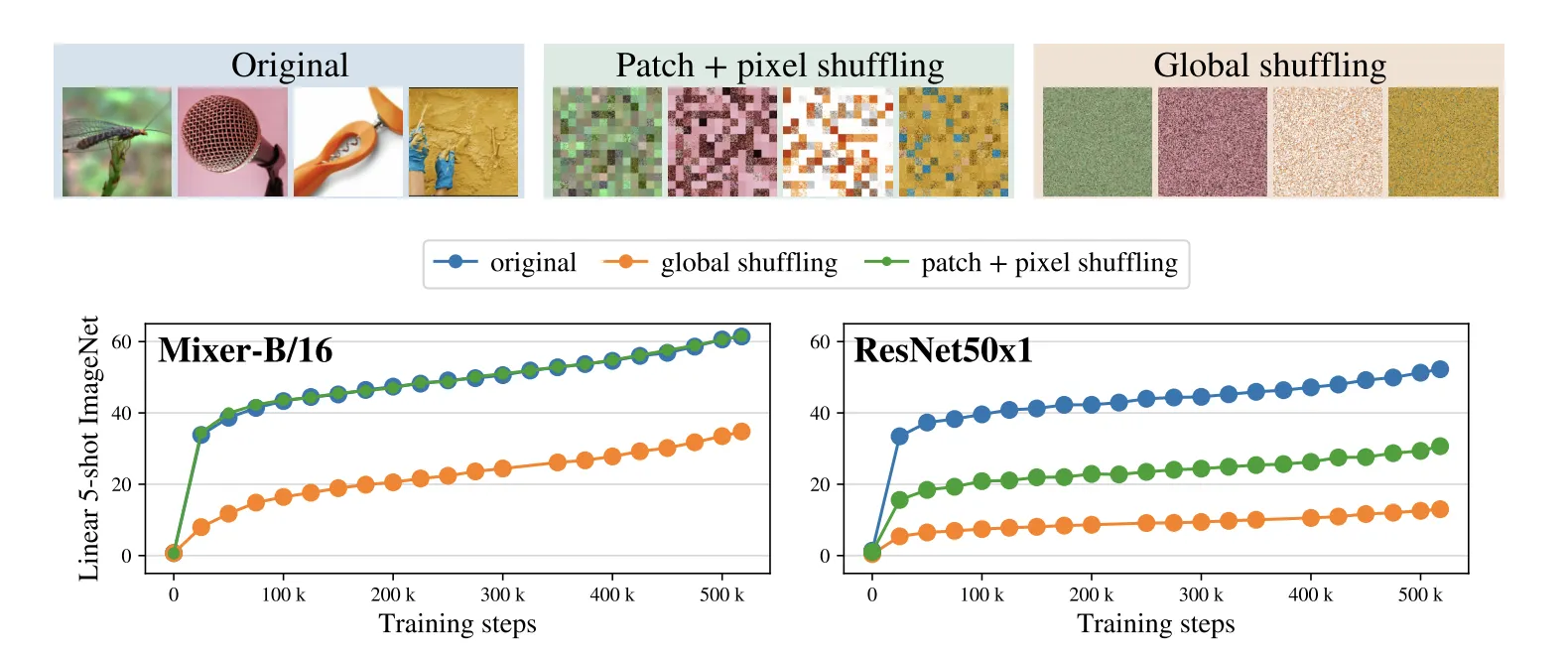
1.
Mixer는 예상대로 Original과 Patch + Pixel Shuffle의 결과가 완전히 동일하다.
2.
ResNet은 Image Order에 의존적인 Inductive Bias를 갖고있으므로 큰 성능 하락을 보인다.
3.
재밌는점은 Global하게 섞어버려도 Mixer의 하락폭이 ResNet의 하락폭보다 작다는 것이다.
다음 질문에 답해보세요.
What did the author(s) try to accomplish?
CNN이나 Self-Attention가 아닌 MLP-Only Architure로도 Vision Task를 잘 수행할 수 있다.
(데이터가 많으면)
What were the key elements of the approach?
Vision Architure에서 각 레이어가 (1) 주어진 공간 위치의 Feature를 섞거나, (2) 다른 공간과의 Feature를 섞는 동작을 통해 모델링 한다는 것을 알고 각각을 분리해 MLP가 수행할수 있도록 한 것
(Token-Mix, Channel-Mix)
What can you use yourself?
-
What other references do you want to follow?
Depthwise Conv, ConvMixer