
예상독자
•
효율적인 HyperParamter Tuning 방법을 찾고 있음
•
Sklearn을 사용해보았음
•
ML Model에 대한 기초적인 지식이 있음
Introduction
 HyperParameter
HyperParameter
머신러닝 모델은 크게 Parameter와 HyperParameter로 이루어져있다. 일반적으로 Parameter는 학습 과정에 데이터에 의해 자동으로 결정되며, 연구자가 조정할 수 없는 값을 의미한다. NeuralNet의 Weight & Bias가 여기에 속한다.
HyperParameter는 사전에 연구자가 미리 지정해 놓는 값으로, 일반적으로 모델 구조나 학습 프로세스에 영향을 미쳐 학습을 통해 결정할 수 없는 값이 이에 속한다. NeuralNet의 Hidden Layer Node 갯수, Learning Rate등이 이에 속한다.
Tuning
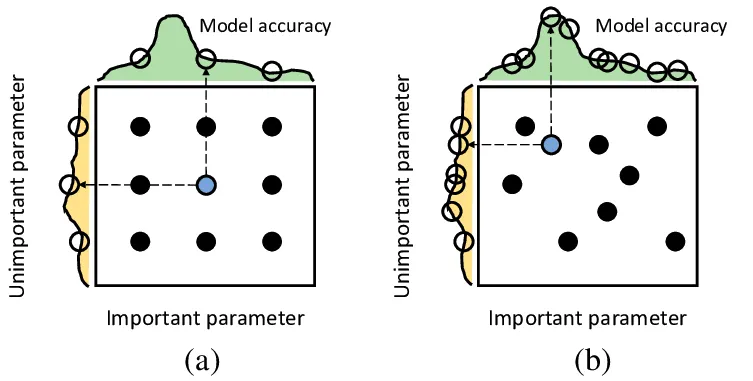
(a): Grid (b) Random
출처 : A Kernel Design Approach to Improve Kernel Subspace Identification(2020)
상술했듯이 HyperParameter는 학습을 통해 결정하기 어렵고, 연구자가 지정해야하는 값들이다. 그러나 Parameter만큼 HyperParameter도 모델의 성능에 큰 영향을 끼친다. 이러한 HyperParameter를 최적화하는 작업을 Tuning이라고 부른다.
가장 간단한 Tuning은 직접 HyperParameter를 고르면서 수정해나가는 방법이다. 당연하게도 경험이나 직관에 의존한 수작업은 최적의 결과를 보장하지도 않고, 오래걸리고, 수고스럽다. 이를 해결하기 위해 사전에 정의한 HyperParmeter 공간에서 자동으로 파라미터를 선택하면서(Search) Tuning하는 방법도 있다. 대표적인 대표적인 Search 방법으로는 Grid Search와 Random Search가 있다.
Grid Search는 Search Space에서 가능한 모든 경우의 수에 대해 성능을 확인해보는 방식이다. Search Space를 잘 정의할 경우 최적해를 잘 찾아낼 수 있지만, Search Space와 Step을 잘못 설정하면 위 그림과같이 아예 최적해를 못 찾을 수도 있고, Space에서 정의된 모든 경우의 수를 탐색하기에 시간이 오래걸린다. Random Search는 Grid 대신 Search Space내에서 랜덤하게 HyperParameter를 Sampling해 성능을 확인해보는 방식이다. 일반적으로 Grid Search 보다 효율적이지만, 최적해를 찾지 못할 수 있다.
Optuna
다양한 Framework가 Grid, Random Search를 포함해 다양한 HyperParameter Optimiziation 기능을 제공한다. Optuna는 그 중 하나로(1) 효율적인 Tuning을 위한 SOTA Algorithm을 제공하며, (2) Python 문법과 쉽게 통합가능하고 (3) 쉽게 Parallelization할 수 있다는 장점이있다. Tensorflow, Pytorch, Sklearn을 포함한 다양한 ML Framework와 쉽게 같이 사용할 수 있다. 시각화를 위한 함수도 내장되어 있다.
Concepts
Study & Trial
Optuna는 Study와 Trial이라는 개념을 이용해 Tuning 과정을 정의한다. Study는 Objective Function을 최적화 하려는 세션을 자체를 의미하며, 수 많은 Trial의 집합으로 이루어져있다.
Trial은 사전에 정의된 Parameter Space에서 HyperParameter를 Sampling한다. 각 HyperParameter에 따른 Objective Function 결과값을 비교해 최적의 HyperParameter를 찾아낸다.
Objective Function
Objective Funciton은 일반적으로 Loss나 Metric을 의미하며, HyperParameter에 따라 결과값이 변화한다.
Parameter Space
HyperParameter를 Sampling하는 공간(범위)을 Parameter Space 라고부른다. Optuna에선 Trial의 Method를 통해 지정해 줄 수 있다. HyperParameter Type(Category, Int, Float)에 따라 다른 Method를 제공하며, Python Code를 이용해 Conditional이나 Loop을 같이 사용할 수 있다.
Optimization Algorithm (Sampling, Pruning)
HyperParameter를 Tuning할 때 Space를 잘 지정해주는것도 중요하지만, Sampling을 어떻게 하느냐에 따라 결과가 크게 달라진다. OPTUNA는 일반적인 Grid, Random Sampler는 물론, Bayesian 기반 다양한 SOTA Sampler도 제공한다.(공식문서) Default는 TPE Sampler(Tree-structured Parzen Estimator)이다.
Pruning은 가망이 없는 Trial을 조기에 종료하는 전략이다.(Early Stopping의 자동화 버전) OPTUNA는 다양한 Pruner를 제공하고 있으며 Iterative Training안에서 작동시킬 수 있다.(공식문서)
Code Example
Tuning Pipeline1.
objective Function안에 모델 학습과정을 Wraping하고 Metric을 반환한다.
2.
trial object를 이용해 HyperParmater를 Suggest한다.(Sampling)
3.
study object를 만들고 Optimization을 실행한다.
import optuna
def objective(trial):
x = trial.suggest_float('x', -10, 10)
return (x - 2) ** 2
study = optuna.create_study()
study.optimize(objective, n_trials=100)
study.best_params # E.g. {'x': 2.002108042}
Python
복사
위의 코드는 -10~10 사이의 Float를 Parameter Space로 정의하고, (Paramter -2) **2이 최소가 되도록 Optimize하는 Toy 예시이다. objective 함수의 역할과 study를 optmizer하는 과정을 볼 수 있다.
Parameter SpaceParameter Space는 objective 함수안에서 입력된 trial의 method를 이용해 지정할 수 있다. Parameter의 특성에 맞게 suggest method를 고르면 된다. 대표적인 method를 소개하자면 다음과 같다.
1.
suggest_categorical(name, choices)
2.
suggest_float(name, low, high, *, step=None, log=False)
3.
suggest_int(name, low, high, step=1, log=False)
def objective(trial):
iris = sklearn.datasets.load_iris()
x, y = iris.data, iris.target
classifier_name = trial.suggest_categorical("classifier", ["SVC", "RandomForest"])
if classifier_name == "SVC":
svc_c = trial.suggest_float("svc_c", 1e-10, 1e10, log=True)
classifier_obj = sklearn.svm.SVC(C=svc_c, gamma="auto")
else:
rf_max_depth = trial.suggest_int("rf_max_depth", 2, 32, log=True)
classifier_obj = sklearn.ensemble.RandomForestClassifier(
max_depth=rf_max_depth, n_estimators=10
)
score = sklearn.model_selection.cross_val_score(classifier_obj, x, y, n_jobs=-1, cv=3)
accuracy = score.mean()
return accuracy
if __name__ == "__main__":
study = optuna.create_study(direction="maximize")
study.optimize(objective, n_trials=100)
print(study.best_trial)
Python
복사
위의 코드는 IRIS 데이터셋에 대해 Classification을 잘 수행하는 모델을 찾기 위해 Optuna를 사용하는 예시이다. 주의깊게 봐야할 부분은 categorical을 이용해 모델 종류까지 바꿔가며 Searching한 것과 , Parameter의 특성에 맞게 float int를 바꿔가며 Suggest하는 예시이다. float, int Suggest에 대하여 log를 true로 설정하면 Parameter Space를 Log Domain으로 변경해 작은 값의 Sampling 빈도를 높인다.
PruningPruning은 Tuning 중, 가망이 없는 모델의 학습을 조기에 종료하는 것을 뜻한다. Iterative Fitting을 해 나가는 모델에 주로 사용된다. objective 함수 내부에서 작동시킬 수 있다.
import optuna
from optuna.trial import TrialState
import sklearn.datasets
import sklearn.linear_model
import sklearn.model_selection
def objective(trial):
iris = sklearn.datasets.load_iris()
classes = list(set(iris.target))
train_x, valid_x, train_y, valid_y = sklearn.model_selection.train_test_split(
iris.data, iris.target, test_size=0.25
)
alpha = trial.suggest_float("alpha", 1e-5, 1e-1, log=True)
clf = sklearn.linear_model.SGDClassifier(alpha=alpha)
for step in range(100):
clf.partial_fit(train_x, train_y, classes=classes)
# Report intermediate objective value.
intermediate_value = clf.score(valid_x, valid_y)
trial.report(intermediate_value, step)
# Handle pruning based on the intermediate value.
if trial.should_prune():
raise optuna.TrialPruned()
return clf.score(valid_x, valid_y)
if __name__ == "__main__":
study = optuna.create_study(direction="maximize")
study.optimize(objective, n_trials=100)
pruned_trials = study.get_trials(deepcopy=False, states=[TrialState.PRUNED])
complete_trials = study.get_trials(deepcopy=False, states=[TrialState.COMPLETE])
print("Study statistics: ")
print(" Number of finished trials: ", len(study.trials))
print(" Number of pruned trials: ", len(pruned_trials))
print(" Number of complete trials: ", len(complete_trials))
print("Best trial:")
trial = study.best_trial
print(" Value: ", trial.value)
print(" Params: ")
for key, value in trial.params.items():
print(" {}: {}".format(key, value))
Python
복사
위의 코드는 SGD + Linear Classification Model의 최적의 값을 찾기위해 Optuna를 사용한 예시이다. 각 Iter에서 학습이 끝나면 Iter의 횟수와 그때의 Metric을 report() Method를 이용해 trial에 전달한다. 이후 should_prune() Method를 호출해 Prune 여부를 알아낸 뒤, 해야한다면(is True) TrialPruned() Method를 호출해 Trial를 종료시킨다.
Visualizationfrom optuna.visualization import plot_optimization_history
plot_optimization_history(study)
Python
복사
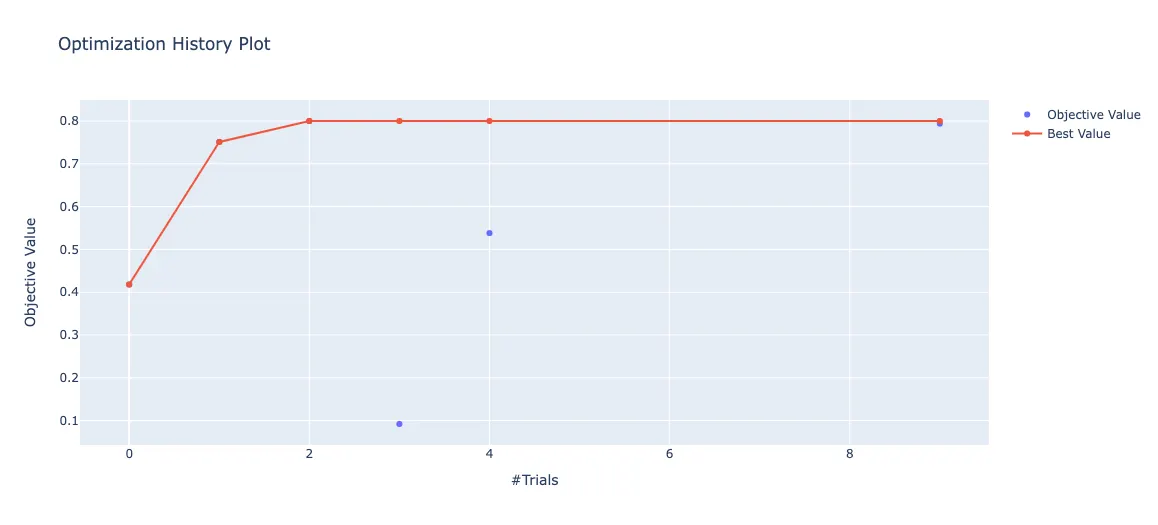
from optuna.visualization import plot_param_importances
plot_param_importances(study)
Python
복사
.png&blockId=338fb7a9-5315-43f7-baae-d4582506bc11)