
2020.10.06

0. Abstract
Transformer가 NLP에선 표준이 되었는데, Vision에서는 아직도 활용이 제한적이다.
Attention은 CNN과 결합하거나, CNN 구조의 특정 componets를 대체하는 식으로 활용 되어왔다.
Image patch를 seq로 처리하는 Transformer(ViT)가 CNN 없이도, 분류문제에서 탁월함을 보여주려 한다.
1. Introduction
NLP
Transformer와 같은 Self-Attention Based 모델이 가장 선호하는 선택지가 되었다.
큰 Text corpus를 Pre-Train하고 작은 Task로 Fine-Tuning하는 방법이 지배적인 접근법이 되었다.
Transformer의 효율과 확장성 덕에 Model과 Dataset이 커져도 성능 상승이 수렴할 기미를 보이지 않는다.
Vision
CNN을 Self-Attention과 이용하려는 많은 연구들이 있었지만, 실용적이지 못했다.
아직도 CNN이 지배적이고, ResNets가 여전히 SOTA를 달성하고 있다.
ViT
최대한 적은 수정을 거쳐 표준 Transformer를 이미지에 이용하려고 많은 실험을 했다.
결국 이미지를 Patch들로 분리해서 Linear Embedding해 Sequence로 활용했다.
Train ViT
중간 크기의 Dataset(ImageNet)에서 강력한 Regularzation없이는 동체급 ResNet보다 낮은 성능을 보인다.
이는 데이터의 양이 Inductive Bias를 배우기에 불충분해, 일반화에 실패했기 때문으로 보인다.
하지만 대형 크기의 DataSet(JFT-300M)에서는 다르다.
대형 Dataset에서 ViT를 PreTrain 하고 적은 데이터로 Fine-Tuning하면 훌륭한 성능을 보인다.
(실제로 JFT-300M으로 Pre-Trained된 Transformer가 다양한 Benchmark에서 SOTA를 깼다.)
2. Related Work
Transformer
Self Attention to Image
CNN with Self-Attention
Global Self-Attention to Full sized Images
Lager Scales than standard ImageNet
3. Method
3.1 Vision Transformer(ViT)
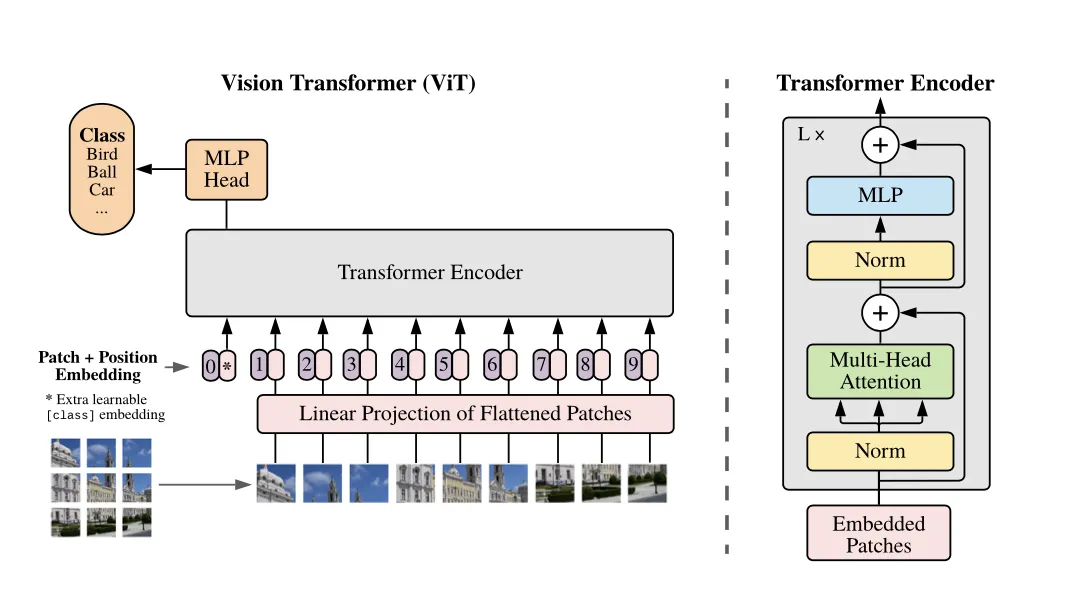
A. Patch
표준 Transformer는 Embedded Token 1D Sequence()를 입력받는다.
우리는 2D 이미지를 입력으로 사용하기 위해서 다음과 같은 과정을 거쳤다.
Notation
1.
2D 이미지를 N개의 2D Patch로 쪼갠다.
(2D Image : ) → (2D Patch : )
2.
각 2D Patch를 Flatten한 뒤 이어붙여 1D Sequence로 만든다.
(1D Sequence :
B. Class Token
BERT의 [CLS] 처럼, 학습가능한 Patch Sequence의 Embedding인 [class] 를 사용한다.
BERT의 [CLS] Token 이란 ?
C. Position Embedding
일반적인 1D Position Embedding을 사용했다. 다양한 2D Position Embedding도 실험해 봤는데 유의한 성능 향상을 보이지 못했다.
D. Encoder
일반적인 Transformer의 Encoder와 같이, Multi-Head Self-Attention(MSA)와 MLP로 이루어져 있다.
MLP는 2-Layer GELU를 한 Block으로 설정했다.
모든 Block 앞에는 LayerNorm(LN)이 있고, 뒷 부분엔 Residual Connection이 붙어있다.
Notation Summary
E. Inductive Bias ( ️)
️)
ViT는 CNN대비 Image에 대한 Inductive Bias가 적다. CNN의 경우 Locality, 2D Neighborhood, Translation Equivariance가 모델 전체에 심어져있다. ViT는 MLP Layer만 Locality가 존재하며, 2D Neighborhood는 초반 Patch 작업 외에는 주어지는 부분이 없다.
F. Hybrid Architecture
이미지를 Patch로 쪼개는 방법 말고도, CNN Backbone의 Feature Map을 사용하는 방법도 있다. 이 때에는 Backbone의 2D FeatureMap을 Patch로 나눈 뒤, Transformer 차원으로 Projection해서 사용한다.
3.2 Fine-Tuning and Higher Resolution
ViT를 큰 Dataset을 통해 학습시키고, 작은 Task에 맞게 Fine-Tune을 진행했다.
1.
Fine-Tune할 땐 Prediction Head를 없애고, Zero-Initialized된 의 Feedforward를 넣었다.
2.
Pre-Train할 때보다 높은 Resolution으로 Fine-Tune하면 종종 좋은 결과를 보였다.
3.
높은 Resolution에 대해 Patch Size는 그대로 두면서 Seq-len 만 늘리면 효율적 연산을 할 수 있다.
4.
즉 ViT는 Resoultion을 Seq-len으로 조절 가능하다.
•
이때 Pre-Trained Position Embedding은 원래의 의미를 잃게 된다.
•
이를 보완하기 위해 2D Interpolation을 Embedding에 적용한다.
(2D Neighborhood가 ViT에 들어가는 유일한 순간이다.)
4. Experiments
4.1 Set-up
A. Datasets
Pre-Train : ImageNet, ImageNet-21k, JFT
BenchMark(Transfer) : ImageNet, CIFAR, Oxford-IIIT Pets, Oxford Flowers-102
+ VTAB : 19개의 Classification Task Dataset, Task당 1000개정도의 적은 이미지를 갖고 있으며
(1) 위와같은 일반적인 Task, (2) 의료, 위성 사진과같은 Specific Task
(3) 기하학적 이해가 필요한 Strudctured Task로 구성되어있음
B. Model Variants
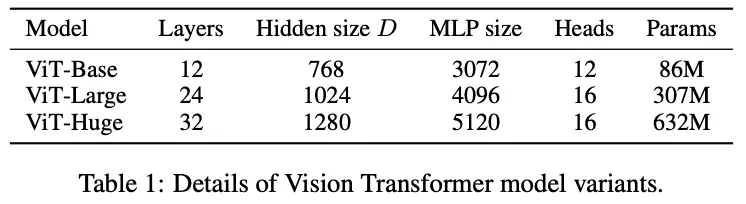
C. Training Details
Pre-Train
Optimizer : Adam(=0.9, =0.999)
Batch-Size : 4096
Weight Decay : 0.1
Lr-Scheduler : Linear Warmup & Decay
Transfer
Optimizer : SGD with Momentum
Batch-Size : 512
Metrics
Few-Shot, Fine-Tuning Accuracy
4.2 Comparision to SOTA
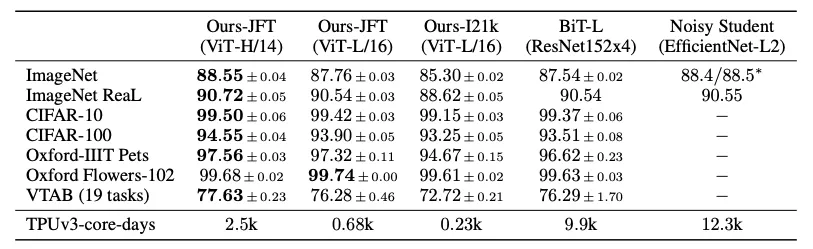
모든 Task에서 ViT가 BiT(같은 Dataset으로 Pre-Train)보다 우위, Cost도 적게 듦
성능-Cost Trade off 생각해봐도 Pre-Train 시간 적게걸리는 ViT 매력적임
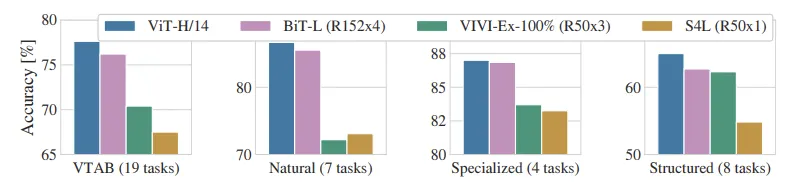
ViT가 Specialized에선 SOTA와 유사한 성능, 다른 Task에선 우위의 성능을 보임
A. Comparision
BiT(Big Transfer) : Supervised Transfer learning with Large ResNets
Noisy Student : Semi-Supervised learning with EfficientNet (ImagNet,JFT)
VIVI : ResNet : co-trained on ImageNet, Youtube
S4L : Supervised + Semi-Supervised learning on ImageNet
B. Pre-Training Data Requirements
[핵심 Insight]
(1) ViT가 CNNs 보다 Inductive Bias가 적다.
(2) 작은 Dataset에선 CNN의 Inductive Bias가 강력하며, ViT로 잘 배우지 못한다
(3) 큰 Dataset에선 ViT가 이미지로부터 그것들을 학습하며, CNN보다 강력해진다.
실험 내용
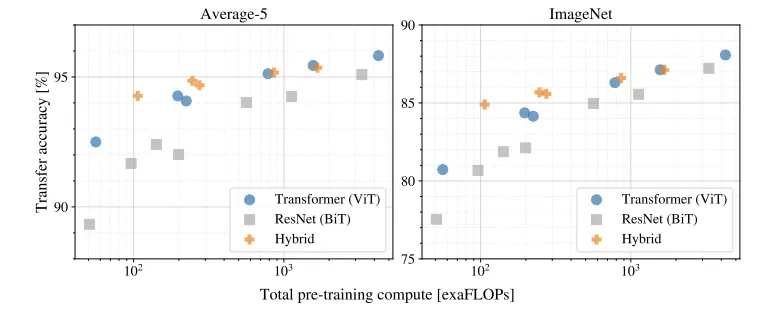
C. Scaling Study
JFT-300M으로 Pre-Train된 모델의 Transfer Performance을 비교했으며 3가지 패턴이 관측되었다.
1.
ViT는 [Performance-Cost] Trade off에서 ResNets을 압도한다.
2.
Hybrid는 Cost Budget이 작을때, ViT를 조금 능가하지만 큰 모델에선 차이가 없다.
3.
Scaling Study에서 시도한 Range안에서 ViT의 성능 향상은 수렴하지 않는것으로 보인다.
5. Conclusion
1.
ViT는 Image를 Patch의 Sequence로 보아 CV Task에 Transformer를 직접 적용했다.
2.
대규모 Dataset과 함께 사용하면 강력한 성능을 보이며, SOTA와 동등하거나 우위를 보인다.
3.
Pre-Trian Cost도 상대적으로 저렴하다.