

Introduction
Recsys
추천시스템은 넓은 의미의 검색 랭킹 시스템으로 볼 수도 있다. 입력은 User와 Context의 정보가 되고, 출력은 클릭이나 구매를 할 것 같은 Item 리스트라고 생각할 수 있다. 검색 랭킹 시스템을 만들 때 어려운 점은 Memorization, Generalization을 둘 다 잘해야 한다는 것인데, 추천시스템도 같은 문제를 풀어야 한다.
Memorization
Memorization은 빈번하게 같이 등장했던 Item, Feature에 대해서 기억해 두었다가, 그 관계가 나타났을 때 정보를 사용하는 것이다. 말 그대로 데이터를 외우므로, Memorization을 기반으로 한 추천은 User와 Context 정보에 직접적으로 관련 있는 추천을 한다. Logistic Regression과 같은 Linear 모델이 Memorization을 하기 위해 사용된다.
Generalization
Generalization은 등장했던 Item과 Feature의 관계를 이용해, 다른 관계를 모델링한다. 데이터에 등장하지 않았던 관계를 찾기도 한다. Generalization을 기반으로한 추천은 비교적 다양한 종류의 Item을 추천한다. FM, NeuralNet과 같은 Embedding 모델이 Generalization을 하기 위해 사용된다.
Pros and Cons
현업에선 대규모의 Online 추천, 랭킹 시스템을 구축하기 위해, 가볍고 해석하기 쉬운 Logistic Regression을 주로 사용한다.(2016년 시점) Logistic Regression은 Memorization류 모델이므로 Generalization을 하기 위해 Feature Interaction을 데이터에 녹여주어야 한다. 이를 위해 관계있는 Feature Pair들을 Cross-Product해 추가해 주는데, 이 과정이 수작업이라는 한계가 있다. Training Data에서 등장하지 않은 Feature Interaction에 대해서는 학습을 아예 할 수 없다는 점 또한 한계다.
Embedding 모델은 각 Item과 Feature를 Dense하게 Embedding하는 과정을 통해 일반화된 Feature간의 관계를 학습할 수 있다. 그러나 Query-Item Matrix가 Sparse 하다면 (Item이 너무 다양하거나, 니치한 Item) 학습 자체가 잘 되지 않아, 연관성이 적은 Item을 추천해주는 Over-Generalize가 발생하는 한계가 있다.
Wide & Deep
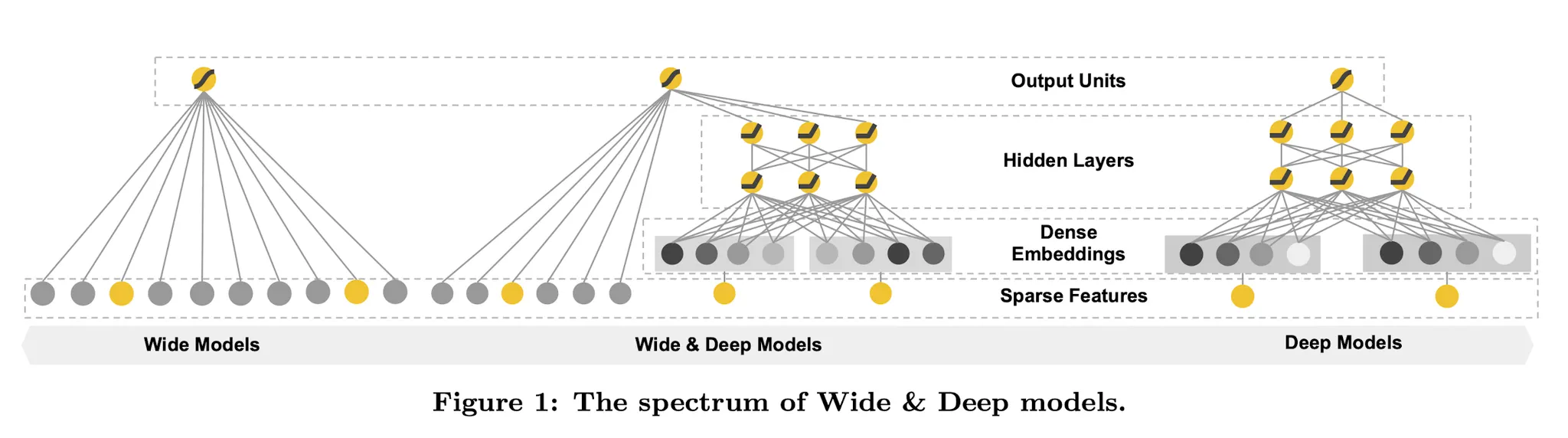
The Wide Component
Wide Componet는 위와 같은 일반적인 Linear Form이다. 는 Raw Feature와 Cross Product된 Feature를 포함한다. 특히 Binary Feature에 대하여 Cross-Product를 수행하면 AND 조건과 같이 작동하는데, Feature Intertaction을 포착하고 비선형성을 늘리는데 도움이 된다.
The Deep Component
Deep Component는 위와같은 일반적인 Feed-Forward Network Form이다. Categorical Feature에 대해 Sparse한 One-Hot Encoding 대신 Dense한 Embedding을 적용한다. 여기서 는 Activation Function으로 Relu를 사용한다.
Joint Training of Wide & Deep Model
Wide Part는 Deep Part를 가중합을 통해 합쳐진다. Wide Part는 L1 Regularization, Deep Part는 AdaGrad를 이용해 훈련하며, Y가 Binary일때 기본 Form은 위와 같지만 Data와 Task에 맞게 적절히 수정하여 사용한다.
Wide & Deep in Real World
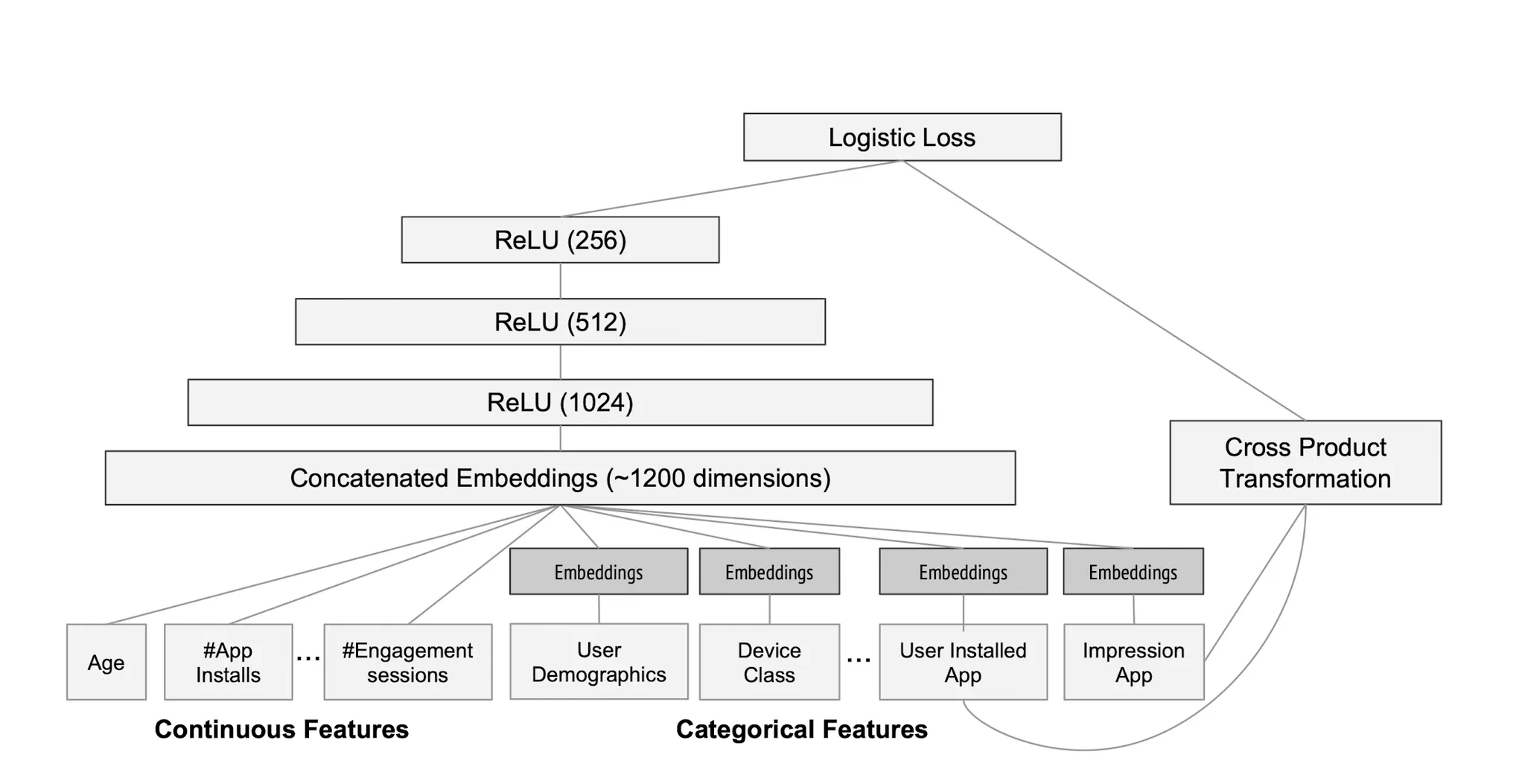
Implementation
Google은 실제로 Wide & Deep을 App 추천에 적용했으며 디테일한 Procedure는 아래와 같다.
1.
Installed App과 Imperssion App을 Cross-Product해 Wide Part로 사용한다.
2.
Categorical Feature는 32차원으로 Embedding한다.
3.
Embedding과 Continuous Feature를 Concat한다 (약 1200+ 차원)
4.
3 FFN(Relu)를 거친 Embedding값(Deep)과 Cross-Product(Wide)를 합해서 Logit으로 사용한다.
5.
Logistic Loss를 구해 Optimize한다.
Experiment
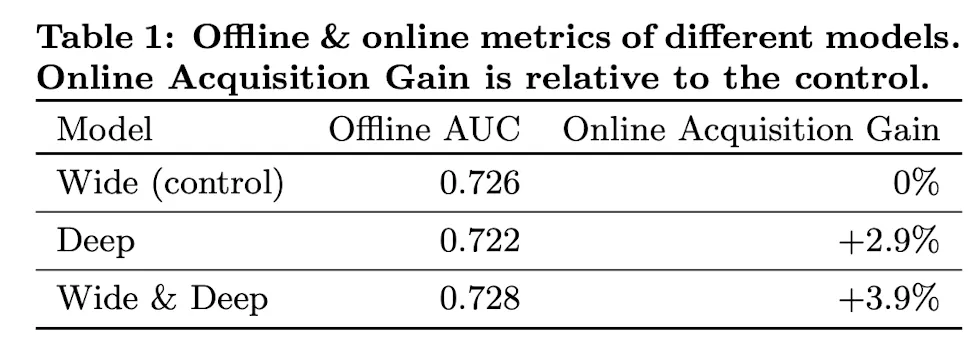
Offline Test에선 Wide & Deep이 근소한 우위를 보였지만, 3주간 진행한 Online A/B Test에선 3.9%의 통계적으로 유의한 Metric 증가를 보였다. Online Dataset의 경우가 일반적으로 훨씬 Dynamic하기 때문에 더 큰 성능 향상을 얻었으며, 이와 같은 환경에서 Memorization, Generalization을 동시에 추구하는 Wide & Deep 구조의 장점이 크게 드러난다.
Conclusion
Wide & Deep은 Memorization과 Generalization을 동시에 고려해 유의한 성능 향상을 보인 방법론이다. Wide Part에서 Cross-Product를 하려면 손수 Feature Engineering을 해주어야 하는 한계를 갖고 있으며 이후 이 부분을 보완한 DeepFM 방법론이 나온다.
NeuralNet의 장점과 한계를 명확히 알아내 Deep Part를 설계하고, 연구자의 Prior를 Cross-Product형태로 넣어주어 성능을 극대화 한 점이 흥미로운 논문이다.