

UberEats
•
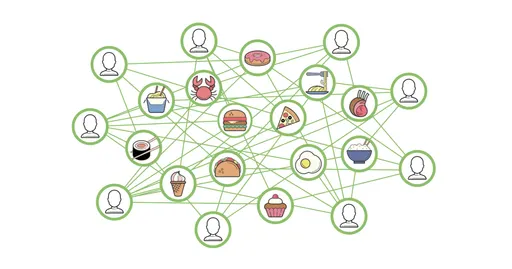
(2019.12 기준) 36개국 5000개 이상의 도시에 320,000개의 레스토랑을 연결해주고 있음
•
최근 Graph의 강력함에 영감을 받아 유저가 관심 가질만한 음식을 추천하는 Graph Model을 구축함
•
이를 통해 플랫폼에서 음식 및 레스토랑 추천 품질을 개선했음
GNN
•
연결되어있는 Node간 확률이 최대가 되고, 끊어져있는 Node간 확률이 최소화 되도록 GNN 학습함
•
Neighbor Sample을 수행하면 아무리 큰 그래프라도 Computation Cost가 커지지 않아서 확장 가능
•
Node의 기본 Feature과 연결관계가 주어지면 새로운 Node에 대해서도 Representation을 뽑을 수 있음
•
이를 통해 대규모의 & 새롭게 추가되는 사용자와 음식에 대해 추천이 가능함
Recommendation in UberEats
•
메인 피드에선 과거 주문 기록 등을 이용해 추천 시스템이 레스토랑과 메뉴 캐러셀을 취향에 맞게 추천해줌
•
추천 시스템은 (1) Candidate Generation, (2) Personalized Ranking 두 파트로 이루어져 있음
•
Candidate Generation은 메뉴와 레스토랑이 계속 증가하므로 확장성 있는 구조로 만들어야 함
•
Personalized Ranking은 유저가 상호작용하는 맥락(요일,시간,위치)를 바탕으로 순위를 매김
GNN in UberEats
Graph System
•
2개의 Bipartite Graph를 이용해 UberEats의 상호작용을 표현함
•
첫 번째는 유저와 메뉴(Dish)간의 Bipartite Graph로 Edge는 메뉴를 주문한 횟수를 표현함
•
두 번째는 유저와 레스토랑간의 Bipartite Graph로 Edge는 레스토랑에 주문한 횟수를 표현함
•
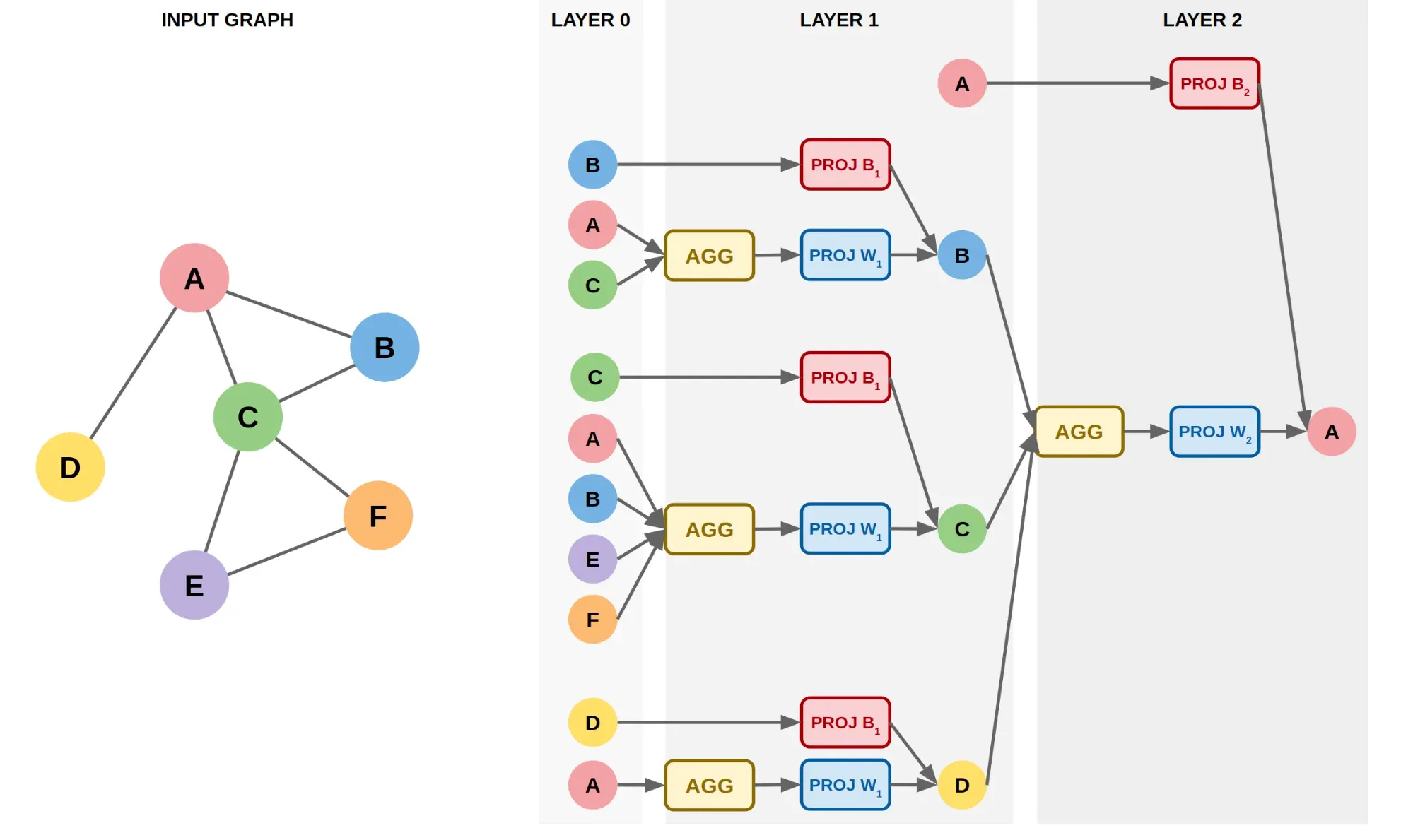
GNN 모델로는 확장성 때문에, 이웃을 Sampling하는 방법인 GraphSAGE를 사용했음
GraphSAGE
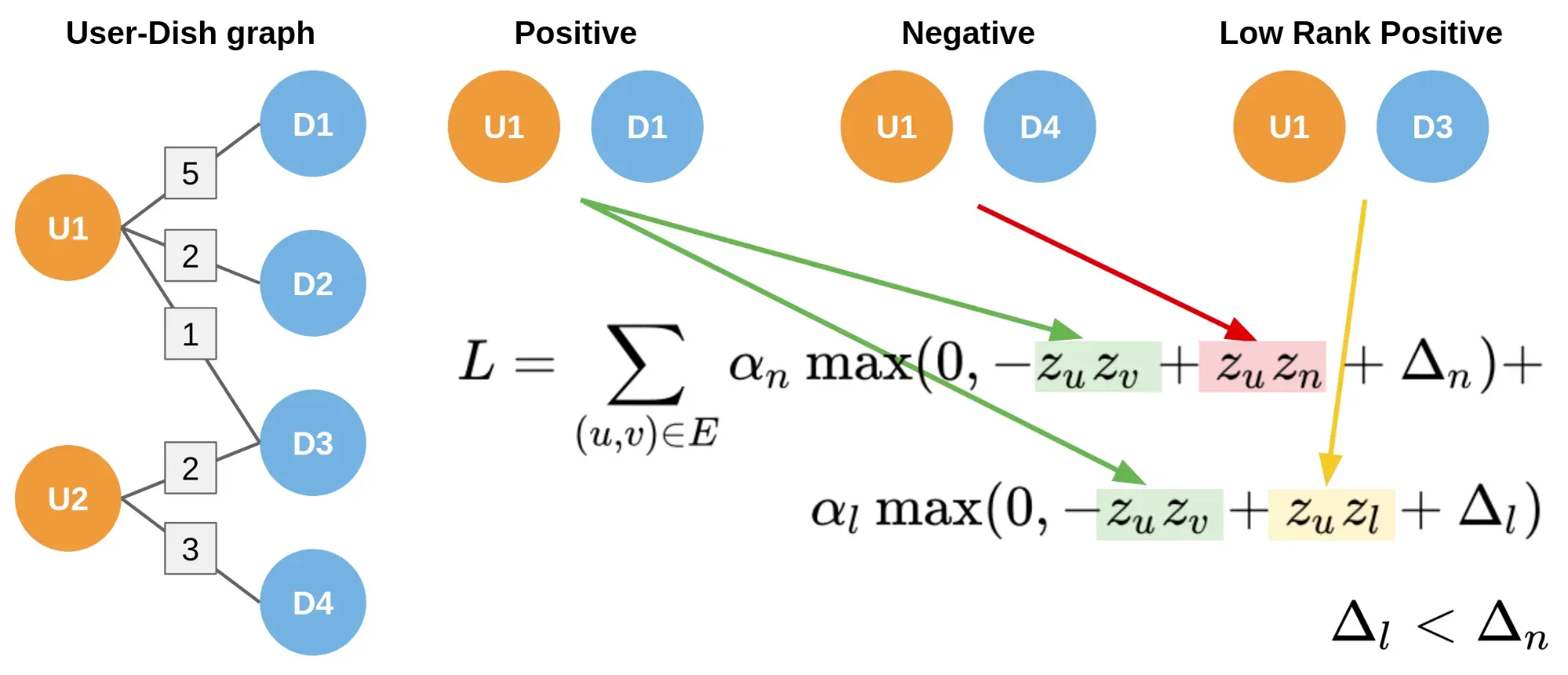
•
Node의 Feature를 Projection해 Type별로 같은 차원을 갖도록 함
•
Edge의 연결 강도에 따른 가중치를 부여해주고 싶어서 새로운 컴포넌트을 도입함
•
일반적인 Margin Loss는 Edge에 강도에 따른 가중치를 주기 어려워서 Low-Rank Positive을 이용함
•
Negative Sample 뿐만아니라, Row Rank인 Positive Sample에 대해서도 Loss를 발생시킴
•
Neighborhood Sampling, Aggregation 과정에서도 연결 강도에 따른 가중치를 이용했음
•
이렇게 학습된 GNN은 Embedding 모델의 역할을 하며 DownStream Task에 활용됨
Evaluation
•
Offline은 4개월동안의 데이터를 학습시키고, 이후 10일에 대하여 모델 성능을 테스트함
•
사용자와 해당 지역의 모든 요리&레스토랑간의 거리를 계산하고 그 안에 실제 주문한게 있는지 확인함
•
모든 지표(MPR, Precision@K, NDCG)에서 기존 모델보다 20% 이상의 성능 향상을 얻어낼 수 있었음
•
추가로 Ranker에 GNN Embedding을 Feature로 사용했더니 기존 모델 대비 AUC 12% 향상됨
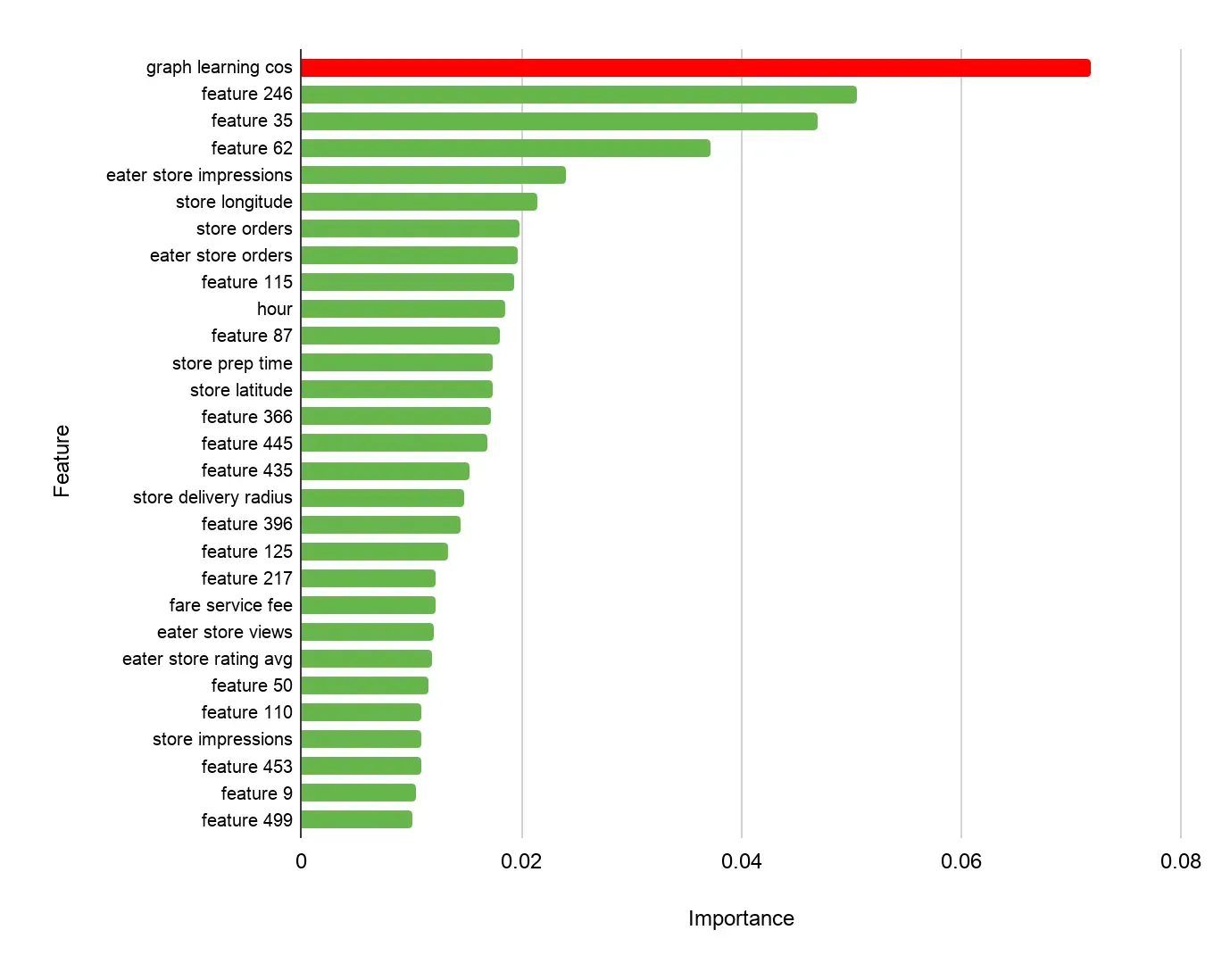
•
Ranker의 Feature Importance를 분석해보니 GNN Embedding이 지배적이었음
•
위의 결과를 바탕으로 GNN에 확신이 생겨 Online Test도 진행함
•
샌프란에서 A/B Test한 결과 GNN Feature를 사용한 경우 기존보다 CTR과 Engagement가 크게 향상됨
Data & Training Pipeline
•
GNN이 Recsys에 긍정적 Impact를 가져다 주는것을 확인했음
•
광범위한 사용을 위해 Production에서 Real-Time Train & Inference가 가능한 파이프라인을 구축함
(아래 파이프를 보면 알겠지만 Real-Time은 아님 ㅎㅎ..)
•
도시별로 Graph가 느슨하게 연결되어있으므로, 이를 분리해서 도시별 Graph를 구축 & 학습시켰음
•
데이터 파이프라인을 통해 Raw 주문 데이터를 Aggregated Feature와 Graph로 녹여냈음
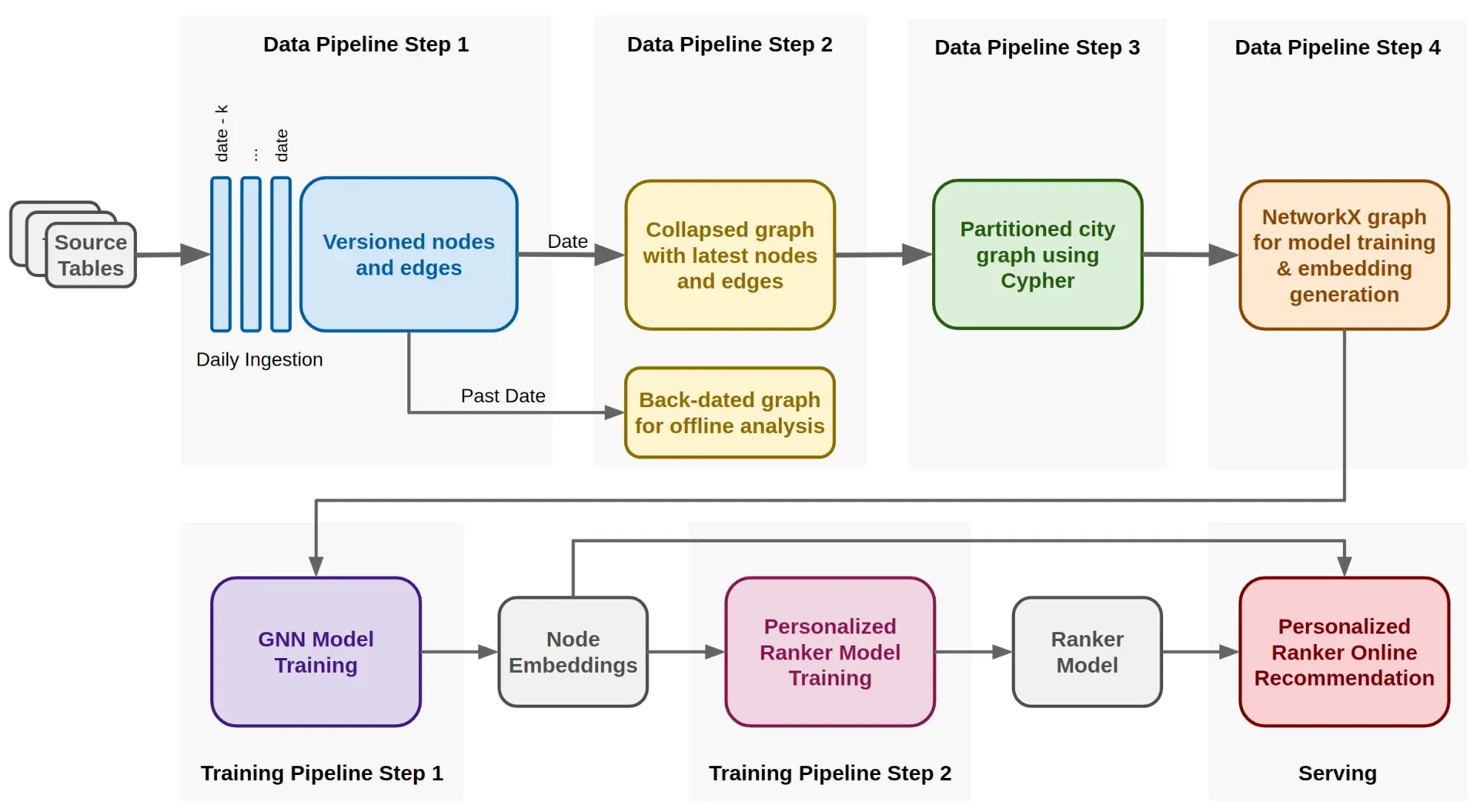
Step 1
•
Hive 테이블에서 병렬로 데이터를 가져오고, Node와 Edge 정보를 갖고있는 Paquet으로 변환
•
Node, Edge는 TimeStamp로 버저닝된 프로퍼티가 있음 (Backfill등의 재현을 위함인 듯)
Step 2
•
날짜가 주어지면, 날짜 기준 Node와 Edge의 최신 Property를 Cypher로 변환해서 저장함
•
Production으로 나가는 모델을 학습시킬때는 항상 현재 날짜 사용, 과거 날짜에 대해서도 프로세스 동일함
Step 3
•
Spark로 Cypher Query를 실행시켜 도시별 Graph를 생성해냄
Step 4
•
생성된 Graph를 NetworkX형태로 변환하고, Model Train & Embedding Generation에 넘겨줌
•
생성된 Embedding은 Lookup Table에 저장되어 추천 요청이 있을 때 Ranking 모델이 검색해옴
Visualized Learned Embedding
•
Graph Representation의 특징을 파악하기 위해 가상의 시나리오에 따른 임베딩 시각화를 해봄
•
탄두리치킨과 야채 커리(인도음식들)를 주문한 신규 사용자가
•
아래의 음식을 주문하면 임베딩 어떻게 달라지는지를 관찰함
◦
피자, 콥샐러드, 도넛, 마파두부, 치킨 마살라, 난
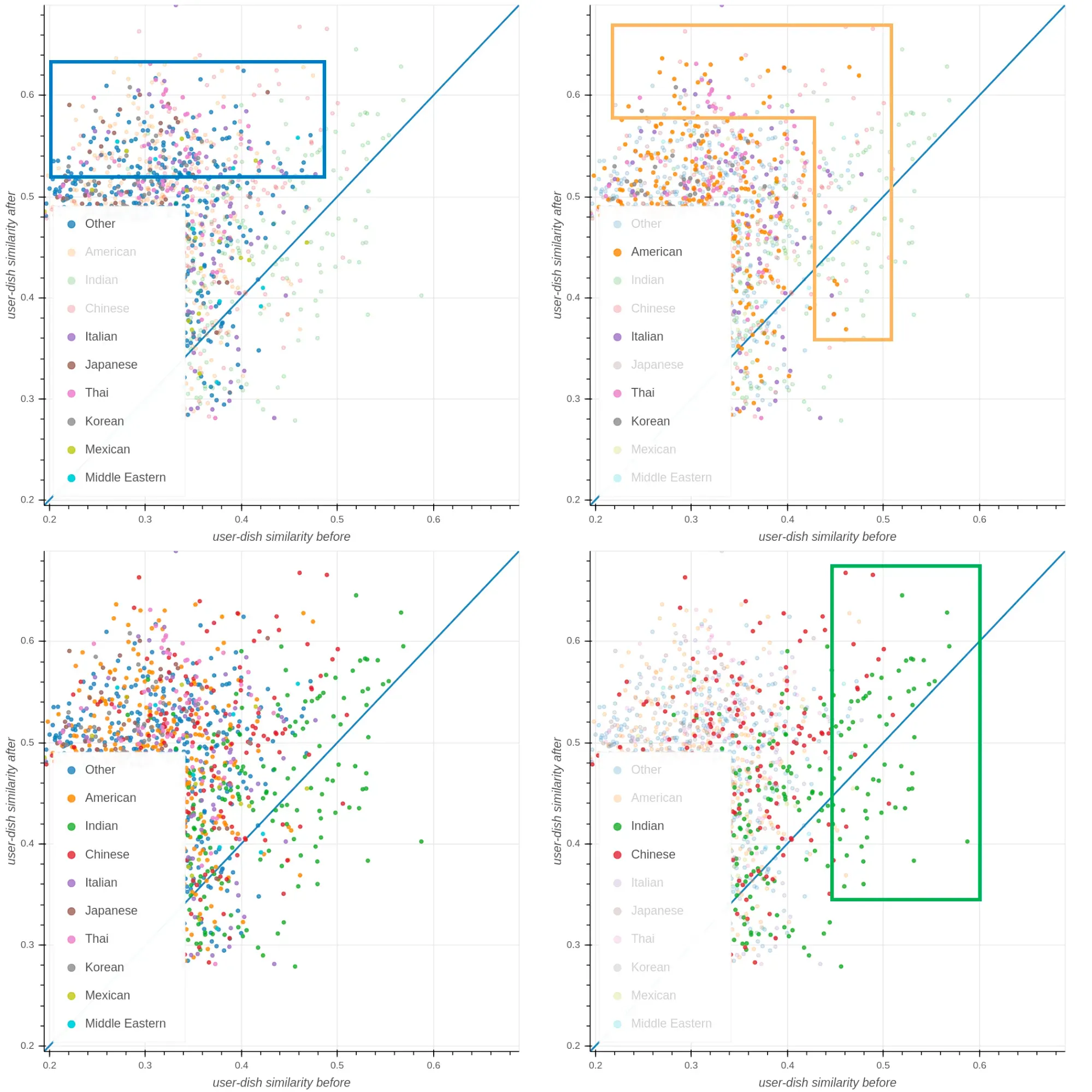
다 같은 그래프인데 하이라이팅 박스만 다르게 함 X축은 추가 주문 전 Y축은 추가 주문 후 코사인 유사도를 나타냄
•
(좌측 하단)
◦
아무런 하이라이팅 하지 않은 표
•
(좌측 상단)
◦
X축과 Y축의 양상이 많이 다른걸 볼 수 있는데, 모델이 새로운 요리를 추천해줄 수 있음을 시사함
•
(우측 하단)
◦
신규 사용자가 인도음식을 주문했으므로 X축이 커질수록 인도음식이 많아짐
◦
X축 높은 중국요리도 꽤있는데 이는 인도음식과 중국 음식이 어느정도 상관관계가 있다는것을 보여줌
◦
Y축을 보면 중국요리가 상당히 많은데 마파두부 주문이 영향을 미친것을 보임
•
(우측 상단)
◦
추가주문을 하고 나니 아메리칸, 이탈리안, 타이, 코리안이 올라간 걸 볼 수 있음
◦
아메리칸, 이탈리안은 피자, 도넛, 콥샐러드가 영향을 끼친 결과로 보임
◦
인도와 중국음식 때문에 타이 코리안이 올라감
Future Directions
•
대규모로 이미 배포된 추천시스템에도 Graph를 이용해 개선할 수 있는 다양한 옵션이 있음
•
우리도 Graph를 이용해 추천 품질을 끌러 올렸으나 할 일이 많이 남아있음
1.
메뉴과 레스토랑을 분리해서 학습시키는 것을 통합하려고 함
2.
우버 이츠가 처음 들어가는 도시와 같이 데이터가 없는 경우에도 추천을 잘하는 방법을 찾고있음