
1. First Step
Title
3D Human Pose Estimation with Spatial and Temporal Transformers
Abstract
1.
PoseFormer는 Pure Transformer Based 3D HPE 모델이다.
2.
Spatial-temporal structure를 이용해 Joint간 관계, Frame간 관계를 모델링했다.
Figures
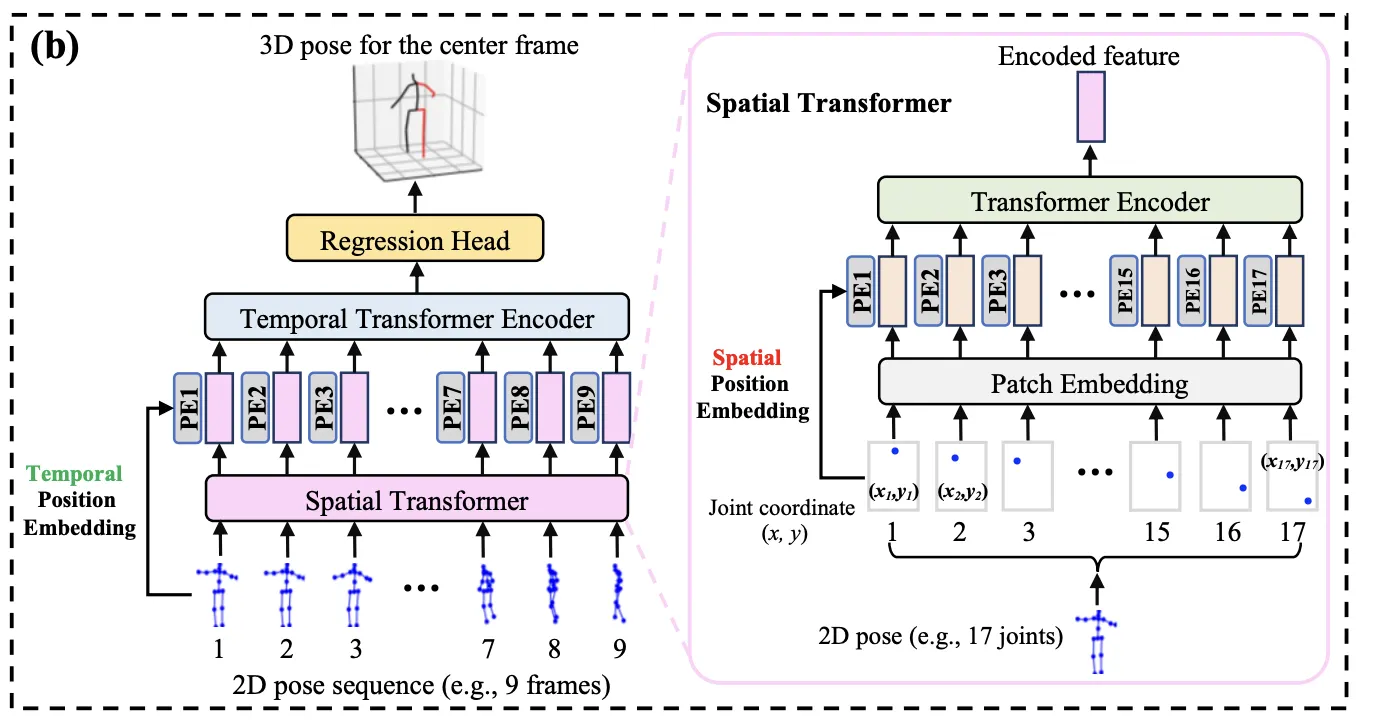
1.
2D Pose Sequence를 Spatial Attention해서 Feature로 만든다
2.
Feature를 Temporal Attention해서 CenterFrame을 Regression한다
2. Second Step
Introduction

Pose Estimation Approaches
크게 2가지 방식이 있으며 (2) Lifting이 SOTA 2D를 섞어 쓸 수 있어서 일반적으로 더 강력하고 많이 쓴다.
1.
Direct Estimation : 2D Image에서 2D Pose 안거치고 바로 3D Pose를 뽑는것
2.
2D-3D Lifting : 2D Image에서 2D Pose 뽑고 거기서 3D Pose 뽑는것
Problems of Lifting
Depth Ambiguity 때문에 같은 2D Pose에서 다양한 3D Pose가 매핑이 가능하다.
최근 연구들은 이를 해결하기 위해 Temporal CNN, RNN을 통해 Temporal Infomation을 넣어준다.
CNN은 Window가 제한적이고, RNN은 단순한 Sequential 관계만 본다는 단점이 있다.
Transformer in HPE Lifting
Transformer는 강력하나, Vision Task에서 CNN과 동급 성능을 보이려면 자원,구조적인 제약이 많고 사실 Transforemr의 장점을 3D HPE에 어떻게 녹일지도 불명확하다. 본 연구는 Lifting에 직접 Transformer를 넣는 여러 시나리오(Baseline)를 통해 PoseFormer를 만든다.
Poseformer
Poseformer는 2D-3D Lifting에 직접적으로 Transformer을 활용하는 첫 Pure Transformer 모델이다.
1.
Off-the-Shelf 2D Estimator로 2D Joint Sequence를 추출하고
2.
Spatial Encoder로 각 Joint간의 Local Relation을 모델링한다.
3.
Temporal Encoder가 각 Spatial Feature의 Temporal Global Dependency를 모델링한다.
4.
정확한 3D Pose를 만들어낸다.
Conclusion
PoseFormer는 2D Video로부터 3D Pose를 뽑아내는 Pure Transformer Based Approach이다.
(1) Sptial Transformer는 2D Joint의 Local Relationship을 모델링하고
(2) Temporal Transforemr는 Frame간 2D Joint의 Global Dependency를 모델링한다.
(3) 유명한 2개의 Pose BenchMark에서 SOTA를 달성했다.
Figures
위에서 소개한 Baseline
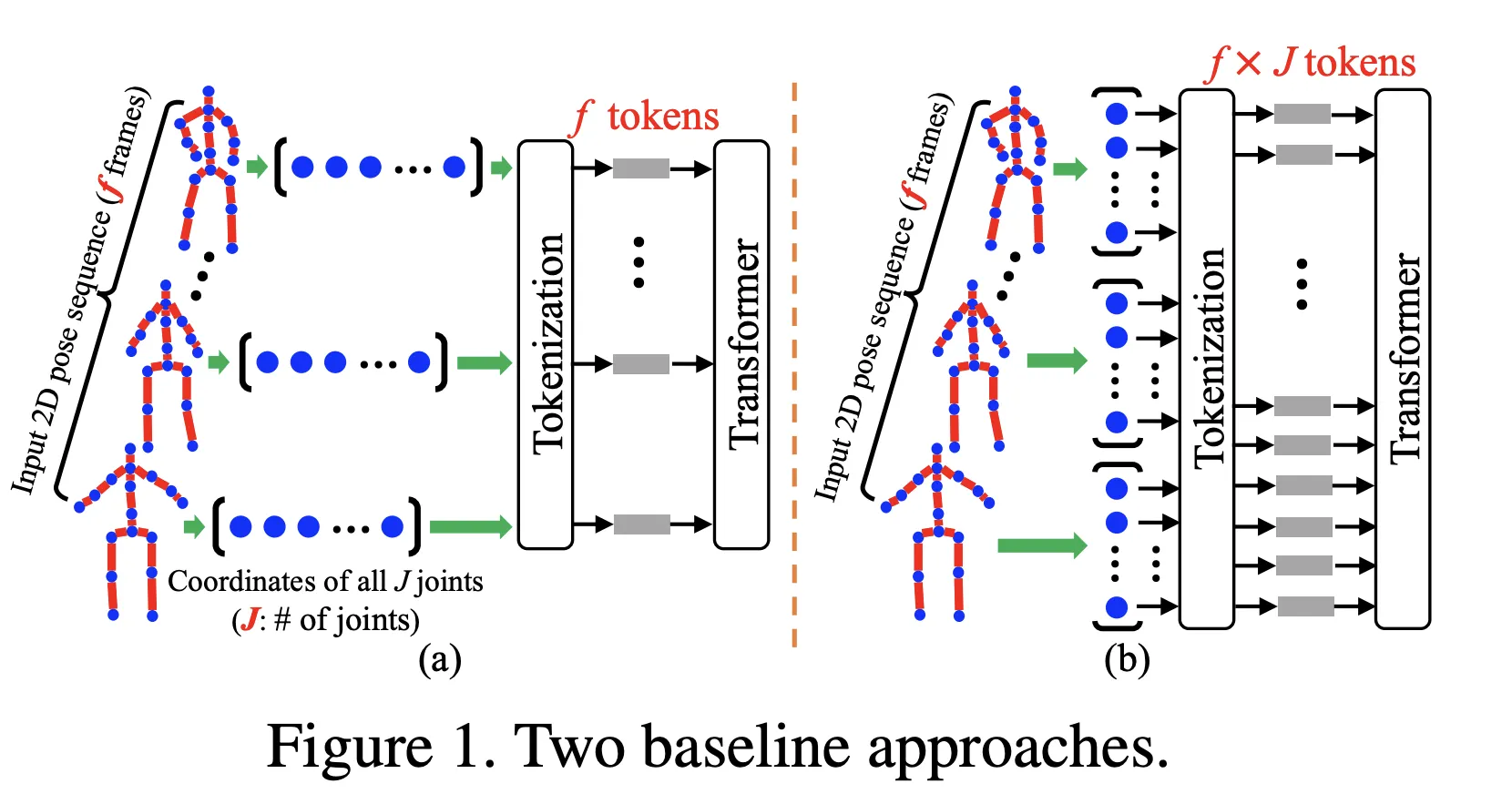
(a) 2D Pose 전체를 Token으로 취급한 Baseline (b) 각 Joint까지 분해해서 Token으로 취급한 Baseline
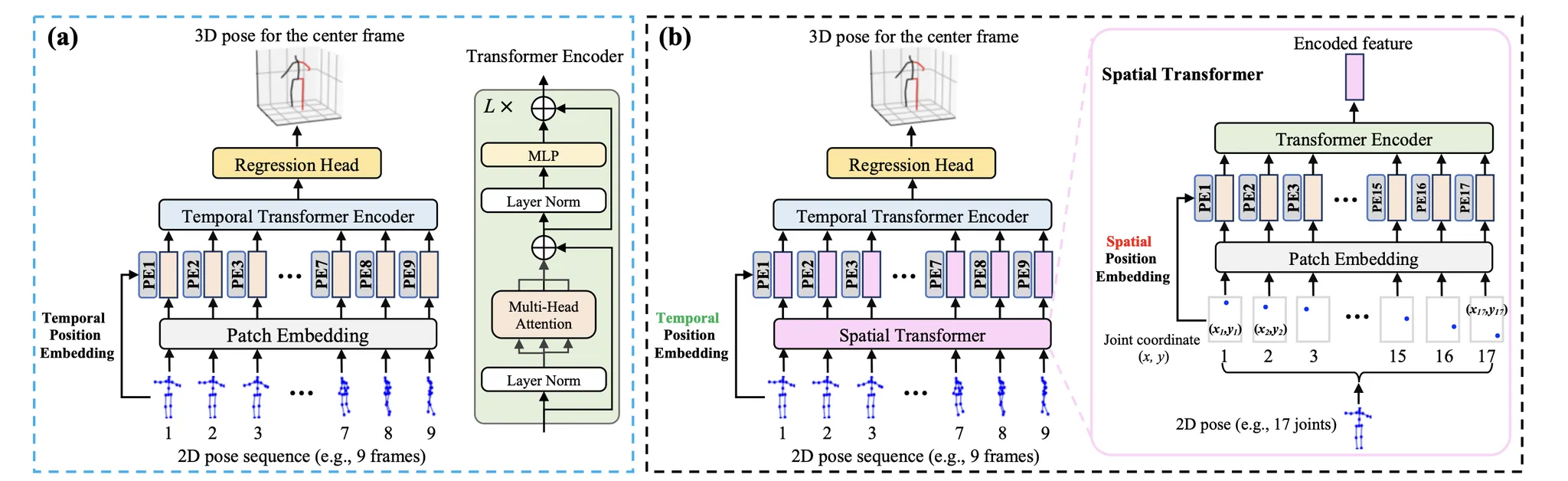
(a) Temporal Transformer Baseline, (b) Spatial-Temporal Transformer(PoseFormer)
3. Third Step
Model Architecture
(1) Temporal Transformer Baseline
1.
Input Sequence는 Frame별 2D Joint 이다.
2.
차원으로 Linear Projection한 다음 (Learnable) Positional Embedding을 더해 Encoder로 넣는다.
(2) Poseformer
Temporal Transformer Basline은 Global Dependency에 집중하고, Patch Embedding이 Joint를 고차원 Hidden Dims으로 Projeciton 해준다. 그러나 이런 간단한 Linear Projection으로는 Local Joint간의 관계를 배우기 어렵다. 해결방안 중 하나는 각 Joint도 Patch로 나눠버려 Sequence을 길이로 만드는건데 계산량이 엄청나게 늘어난다. 따라서 Spatial Transformer Module을 사용해 다음 3모듈을 포함한 구조를 이용한다. (1)Spatial, (2)Temporal, (3) Regression
(3) Spatial Transformer Module
Single Frame에 대해 수행되며, 각 2D Joint를 Patch로 사용한다. 일반적인 ViT와 거의 같다.
1.
2D Joint를 차원으로 Linear Projection한다. (Spatial Patch Embedding)
2.
(Learnable) Spatial Positional Embedding을 더해 Encoder에 넣는다.
3.
차원의 결과물을 얻는다.
(4) Temporal Transformer Module
1.
Spatial Transformer의 결과물을 Frame단위로 묶는다.
2.
(Learnable) Temporal Positional Embedding을 더해 Encoder에 넣는다.
3.
결과물 를 얻는다.
(5) Regression Head
Poseforemr는 Frame의 Center만 예측하기에(Video Pose Style) Learned Weight를 이용해 Frame에 대해 Weighted Mean을 적용한다.
Details
GPU : 3090 x2
Dataset : H3.6M, 3DHP
Loss : MPJPE
Epoch : 130
Batch_size : 1024
Optimizer : Adam(2e-4)
Lr Scheduler : 0.1 WeightDecay, Exponential Decay by 0.98 every epoch
Technique : Flip and Mean Augmentation, Stochastic Depth(0.1)
2D Pose Detector : CPN
4. Fourth Step
What did the author(s) try to accomplish?
•
Transformer를 3D HPE Task 특히 Lift에 이용해보려고 했으며, 대단하진 않아도 괜찮은 성능을 얻었다.
What were the key elements of the approach?
•
Linear Projection만으로는 Joint간의 관계를 모델링하기 어려워서 사용한 Spatial Transformer
What can you use yourself?
1.
Lifting 관련 Idea 획득
2.
MixSTE의 Reference로서 연구흐름 따라가기
What other references do you want to follow?
•
VideoPose나 CNN기반 Lift 연구에서 아이디어를 얻으면 좋을 듯.