
Abstract
Existing GCN(Graph Convolution Network)
현존하는 GCNs은 강력한 Node Embedding 성능을 보이고 있지만 Graph를 Homogeneous로 간주한다는 단점이 있다. 현실에서 Node가 가지고 있는 복잡한 Interaction을 Homogeneous Graph만으로는 모델링 하기 불충분하다.
MultiSAGE
저자들은 Target Node와 Context Node로 구성된 Multipartite Network를 만들어 맥락이 포함된 GCN인 MultiSAGE를 제시한다. 특히 Context Node를 Embedding해, Target Node Embedding과 함께 사용하므로서 DownStream Task에서 훨씬 정교한 모델링을 가능케 한다.
Introduction
What is Context Node?
상술했듯이, 일반적으로 대부분의 GCN 모델에서는 하나의 중요한 Node만을 다룬다. 그러나 현실을 잘 생각해보면 그 Node와 상호작용하는 주변 Node들이 꼭 존재한다.
예를들어 Pinterest의 경우 핵심 Node는 Pin이지만, Board가 Pin과 항상 함께 상호작용하며, 추가적인 정보를 제공한다. 학술 Graph의 경우도 핵심 Node는 Paper지만, 저자와 학회등의 Node가 논문과 함께 상호작용한다. 저자들은 이런 주변 Node를 Context Node라고 정의한다.
How to Leverage Context
MultiSAGE에선 GCN에 과정에 Context, Neighbor, Ego(Self) Node 정보를 Attention 하는 구조를 넣어 맥락정보를 녹여낸다. 이 구조를 Three-Way Attention이라고 부른다.
MultiSAGE
MultiSAGE도 기존 SAGEs와 마찬가지로 Target Node가 주어지면, 이웃들로 부터 정보를 Aggregation해 Embedding을 배운다. (Target Node = Ego Node = )
MultiSAGE가 차별점을 가지는 부분은 Ego Node와 이웃 Node 사이에 존재하는 Context Node를 이용한다는 점이다. 다만 모델링을 위해 Target Node의 수 많은 Context Node중 가장 Dominant한 Context Node 하나만을 사용한다. 이 관계를 Notation과 함께 표현하면 다음과 같다.

Ego Node 의 각 이웃 Node 는
Dominant Context Node 로 연결되어 있다.
Raw Feature Transform
Target Node의 집합 와 Context Node의 집합 의 크기는 한계가 없기때문에 ID 기반 Embedding은 비효율적이다. 따라서 일반적인 Feature기반 Embedding을 사용한다. 수식은 다음과 같다.
일반적인 FFN 구조이며, 는 Raw Feature를 의미한다.
Contextual Masking
Context Node와 Interaction한 Target Node라는 것을 모델링 하기 위해 Contextual Masking이란 방법을 사용한다. 이 방식은 와 를 Element-Wise 곱하는 연산으로 이루어져 있는데, 의 결과물이 ReLU Output 이므로 연관없는 Dimension은 0으로 Masking 되어버린다. 수식은 다음과 같다.
Contextual Attention
Contextual Masking을 이용하면 Ego, Neighbor Pair를 Feature Level에서 Subspace로 보낼수 있다. (가 그 역할을 한다) 이를 넘어서 Interaction에 따른 영향력까지 풍부하게 고려하기 위해 Attention을 사용한다.
이때 Attention은 Ego()-Context()-Neighbor() Triplet에 대해 가중치를 구하는데 수식은 다음과 같다.
자세히 살펴보면 GAT의 연산과 같음을 알 수 있다.(1) Node-Type 별로 정의된 가중치 를 통해 선형변환을 한 뒤 (2) Concat한 다음 가중치 를 통해 또 선형변환을 한다 (3) 이후 LeakyReLU()를 통과시킨 값을 이웃에 대해 Softmax한다. MultiSAGE도 GAT처럼 Multi-Head-Attention을 수행하며, 이렇게 구해진 Contextualized Embedding은 다음과 같이 표현할 수 있다.
이렇게 Embedding을 구하고 나면 Ego Node의 임베딩 과 를 더해서 로 사용한다. 학습 과정에선 PinSAGE 처럼 Query, Positive, Negative의 Triplet Loss를 사용하며 를 이용해 최적화한다.
Web-Scale Implementation
Parallel Contextualized Random Walk
MultiSAGE는 Multi-Layer GCN이므로 여러 Hop에 걸친 이웃 정보가 필요하다. 그러나 일반적으로 Hop수가 늘어나면 Graph 전역에서 이웃이 관찰되므로, 그 이웃들의 인접행렬을 메모리에 가지고 있기란 불가능하다. 이를 해결하기 위해 Batch마다 고정된 이웃을 샘플링 할 수 있지만, Layer가 늘어날수록 연산이 복잡해지는건 그대로다.
그런데 최근 연구결과에 따르면, PageRank Score를 바탕으로 이웃을 Sampling하면, Single-Layer GCN만으로도 Multi-Layer GCN을 모방할 수 있는것으로 관찰됐다. 이 연구를 MultiSAGE에서도 활용해 병렬로 Random-Walk를 수행한 뒤, 고정된 수의 중요한 이웃을 DB에 저장해놓고 학습에 사용한다.
이웃 Sampling뿐만아니라, Ego-Neighbor Pair의 Context Node도 이 과정에서 추출된다. 일종의 Greedy 알고리즘을 사용하는데, 병렬로 Ego Node에 대해 Random Walk를 수행한뒤 (Ego-Neighbor)가 포함된 Walk에서 가장 많이 나타난 Context Node를 Dominant Context Node로 사용한다.
Hadoop2-Based Data Provider
Node Feature를 찾아내서 Join하는 것도 무거운 연산이다. 예를들어 10억개의 Pin이 있는데, 64차원의 Visual Feature와 128차원의 Textual Feature를 저장해야 한다면 Feature Store는 1TB의 공간이 필요하다.
Train, Inference 과정에선 필요한 Feature를 바로바로 불러와야 하기 때문에, Feature가 Memory에 올라가 있지 않다면 BottleNeck이 될 수도 있다. 이를 최대한 개선하기 위해 S3 스트리밍 기반 파이프라인을 구축했다.
구체적으로는 Random Walk를 통해 모든 Target Node의 이웃 List를 Off-Line으로 고정한다. 그 다음 미리 이웃 List의 Feature를 결합한채로 Feature Store에 올려 둔 뒤 S3에 저장해 놓는다. 이렇게 하면 학습 과정이나 Online Inference에서 이웃별로 Feature를 불러오고 Join하는 과정을 생략할 수 있다. Pinterest는 이런 구조로 S3 파이프라인을 견고하게 구축해 두었다.
Experiments
Dataset Preparation
Pinterest Graph는 7,600만개의 핀 1,500만개의 보드 27억개의 Link를 사용했다. Link는 Repin 데이터 기반으로 추출되었는데, Query를 Pin한 직후 상호작용한 Item을 Positive Pair로 이용했다. 이때 Noise를 줄이기 위해 2회 이하로 나타난 Pair는 사용하지 않았으며, Bias를 줄이기 위해 Query당 최대 20개의 Pair만 사용했다. 이렇게 7500만개의 Pair를 추출했으며, 이중 100만개를 랜덤 샘플링해 ValidSet으로 사용하였다.
Evaluation Metrics
(Evalution Node Pair)에 대하여 Metric을 측정한다. 대중적인 MRR, REC@K 뿐만아니라, Node Embedding의 거리를 재는 Metirc도 사용한다.
이때 척도로는 코사인 거리와 유클리디안 거리를 사용하는데, (Average Cosine Distance), (Average Euclidean Distance)라는 Notation을 사용한다. 이 두가지를 모든 Node와 Pair Node에 대하여 계산한다. 좋은 임베딩의 경우 전체적으로 넓게 퍼져있으면서, Pair Node끼리는 가깝에 위치해야 하므로, 두가지 지표를 이용하면 이에대한 정보를 얻을 수 있다.
Quantitative Evaluation
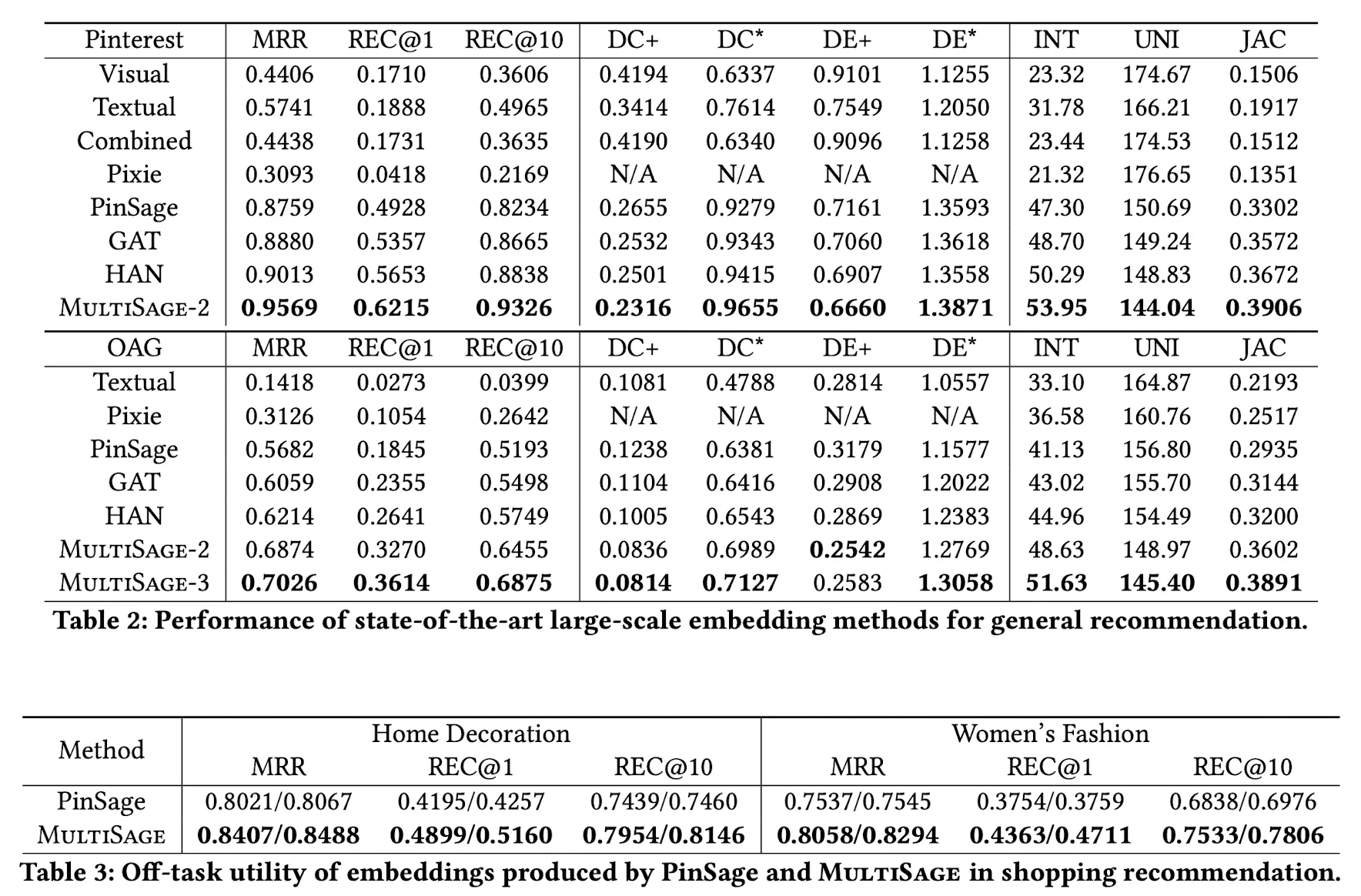
*는 모든 Node와의 거리, +는 Positive Pair와의 거리이다.
Pinterest와 Academic Graph인 OAG에 대한 Metric Table이다. 대부분의 지표에서 성능이 상승한 것을 볼 수 있다. 재미있는 점은 OAG의 MultiSAGE-3인데, MultiSAGE-3은 Node Type을 3개로 확장한 Tripartite Graph에 대해 MulitSAGE를 적용한것을 의미한다. Node Type을 나누어 정보를 추가해줄수록 성능이 올라가는 것을 볼 수 있다.
Ablation Tests
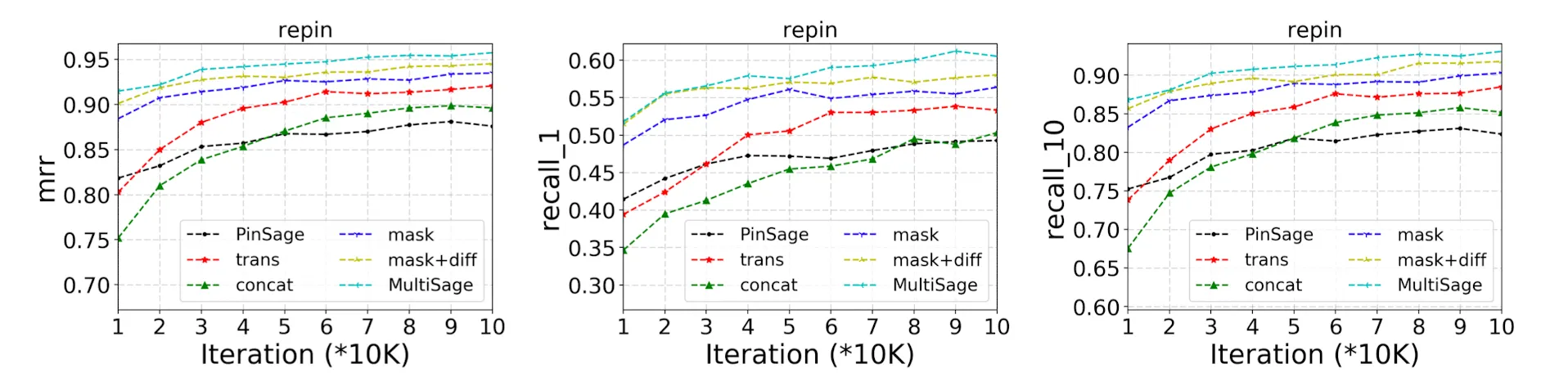
Contextual Masking과 Contextual Attention의 효용을 입증하기 위한 실험결과다. 두 개를 모두 적용한 MultiSAGE가 모든 실험에서 좋은 결과를 보임을 알 수 있다.
Scalability Study
MultiSAGE와 PinSAGE는 일반적으로 한 Epoch이 다 돌기 전에 수렴한다는 것이 관찰되었다. 여러 세팅때문에 PinSAGE보다 런타임이 조금 길지만, 상술한 Hadoop2-Based Provider를 이용하면, 기존 PinSAGE Pipeline보다 25% 런타임이 감소한다. 이 파이프라인(Feature 사전결합)은 Production에서의 여러 Constraint를 제거하면서 더 큰 그래프를 사용할 수 있게 해준다.
Conclusion

MultiSAGE는 Context 기반으로 Node에 대해 Multi Embedding을 하는 첫 연구이다. Fine-Grained 추천에 큰 개선이 있는걸 여러 실험을 통해 확인했으며, 인기가 적고 신선한 아이템을 추천하는데에 큰 도움이 된다.