

0. Motivation
MixSTE를 구현하던 도중, VideoPose3D부터 전해 내려오는 Test-Time Horizontal Flip Augmentation 테크닉이 정확히 무엇인지 이해가 안가서 찾아보다가 Test-Time Augmentation이라는 일종의 앙상블(?) 테크닉이 있다는 것을 알게되었다. 알게된 내용을 공유하기 위해 이 글을 작성한다.
1. Augmentation
일반적으로 딥러닝 모델 (특히 Vision)을 학습시킬때, 부족한 데이터를 늘리기 위해 임의로 데이터에 변형을 주는Augmentation을 사용한다. Vision Task(Image)에서의 Augmentation의 예로는 Flip, Noise, Jitter 등이 있으며, Dataset에 Bias가 껴있을 경우 유의미한 성능 향상을 보일 때가 많다.

Example of Data Augmentation on the CIFAR10 dataset (https://towardsdatascience.com/test-time-augmentation-tta-and-how-to-perform-it-with-keras-4ac19b67fb4d)
2. Test-Time Augmentation
Test-Time Augmentation(이하 TTA)는 이런 Augmentation을 Inference 과정에도 사용하는 것이다.
Dogs vs Cats Binary Classification Task에서 TTA를 사용하는 상황을 가정해보자. 학습이 완료된 모델을 평가할 때, Augmentation을 통해 2장의 이미지를 추가하고 전부 Inference를 수행한다. 그리고 그 결과물의 평균을 내어 Class를 할당한다.
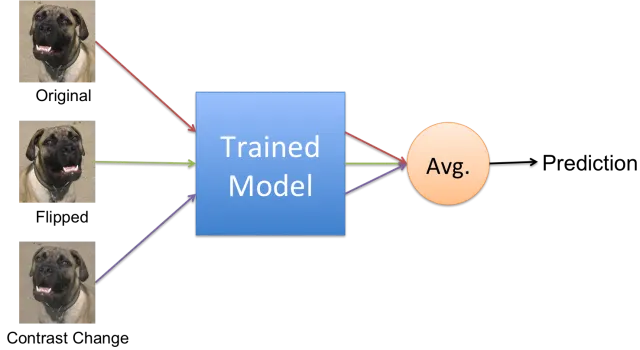
결국 성능을 높이기 위한, 일종의 앙상블 과정으로 볼 수 있으며 사용할 때 주의할 점은 크게 두 가지가 있다.
(1) Train과 마찬가지로 핵심 Feature를 손상시키는 과도한 Augmentation은 성능에 악영향을 끼칠 수 있으며
(2) Augmentation으로 늘어난 이미지 갯수만큼 Inference 해야하는 횟수가 늘어난다.
3. TTA in 3D Pose Domain
VideoPose3D가 대표적인 TTA 방법을 쓴 모델이다. VideoPose는 2D Joint를 받아 3D Joint를 예측하는 모델인데, 이때 Horizontal Flip Augmentation을 이용한다. 적용 여부에 따른 성능 변화는 다음과 같으며, TTA가 성능 향상에 도움이 꽤 되는 것을 볼 수 있다.
Case | Metric(MPJPE) |
Non Filp | 49.22 |
Only Train Augmentation | 47.7 |
Train, Test Augmentation | 46.8 |
4. Summary
TTA는 Train 과정에 사용되는 Augmentation을 Test-Time 에도 적용해 앙상블과 같은 효과를 내기위한 테크닉이다. 실제 여러 곳에서 사용되고 있으며 Kaggle같은 Competition에서는 필수적으로 보인다. 다만 서비스에 적용하기에는 Cost Trade-off가 많이 별로인 듯 하다.
참고한 문서