
Abstact
본 논문은 Clsasafciation, Detection, Segmentation Task를 수행하기 위해 작성된 백여개의 Visual Transformer 논문에 대한 Review Paper 이다. 동기, 구조, 용례에 따라 구성했으며 각 논문의 학습 세팅과 Task 종류가 다르므로, 간단하고 직관적인 Evaluation또한 추가했다.
Introduction
(1) NLP에서의 Self-Attention의 성공에 영감을 받아. CNN Model에서도 Long-Range Depedency를 Channel or Spatial 차원의 Self-Attention으로 모델링 해보려는 시도가 있었다.
(2) 전통적인 Convolution을 Global or Local Self-Attention으로 대체해보려는 시도가 있었다.
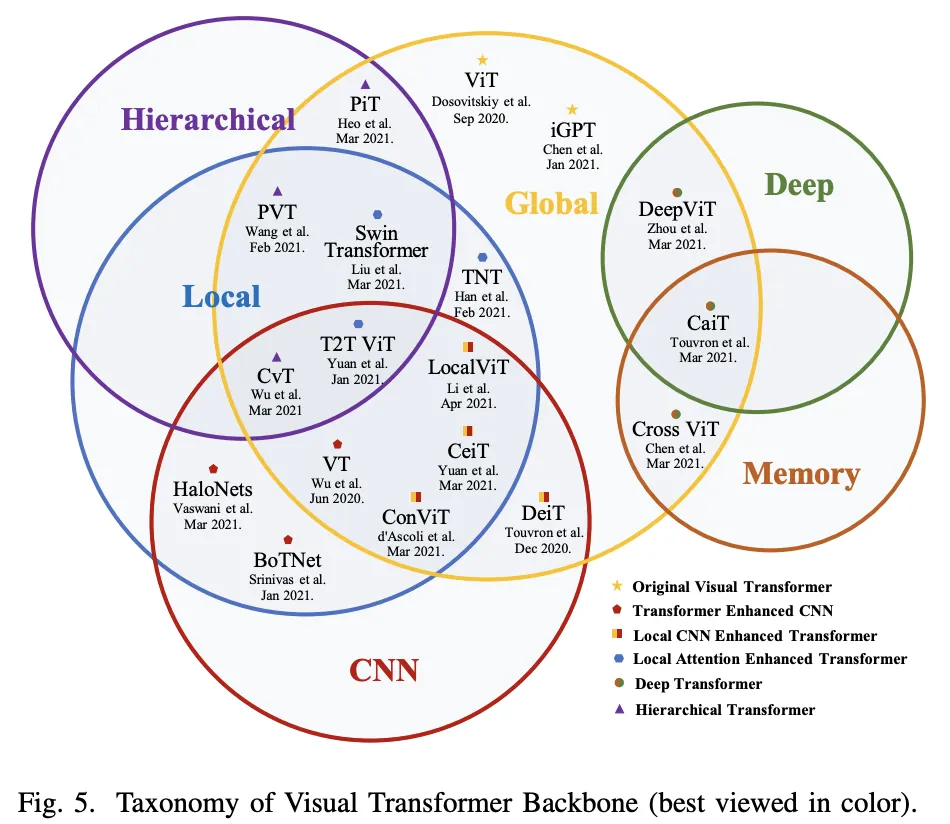
Transformer for Classification
Introduction

동기와 구현에 따라 6가지로 분류해 볼 수 있다.
1.
ViT : The Original
2.
Transformer Enchanced CNN :
CNN Backbone + Transformer for Long-Range Depedency
3.
CNN Enhanced Transformer :
적절한 Convolution Bias를 Transformer에 추가
4.
Local Attention Enhanced Transformer :
Patch 방식 재설계 + Transformer의 Local 능력을 강화시켜서 Convolution Free 구조 유지
5.
Hierarchical Transformer :
CNN 선행 연구로부터 영감을 받아, 고정 Resolution → Pyramid Stem 차용
6.
Deep Transformer :
CNN 선행 연구로부터 영감을 받아, 깊은 Layer에서 다양성을 증가시키고 Over-Smooth 방지
1. ViT (Original Visual Transformer)
Image Classification을 위해 Transofrmer를 Backbone으로 처음 사용한 모델
Large Scale의 비공개 Dataset(JFT-300M)을 사용해 학습시켰으며 ImageNet, CIFAR등의 BenchMark들에서 CNN과 유사하거나 더 좋은 성능을 보였다. Training Data가 부족해 일반화할순 없지만, CV Tasks 에서의 효과를 입증했다.
1.
Input Image를 겹치지 않는 Patch로 분할하고 (Token)
2.
Embedding으로 Project한다.
3.
Spatial한 정보를 주기 위해 1D Positional Encoding을 넣어준다.
4.
BERT 처럼 class Token을 추가해 Encoder로 Classification을 위해 Repersentation을 학습시킨다.
2. Transfomrer Enhanced CNN
Transformers는 MHSA와 FFN으로 구성되어있는데, 충분한 Head가 있는 MHSA라면 Covolution을 근사할 수 있음이 증명됐다. 이론적으로 Transformer가 Capability가 CNN보다 크므로 더 강력한 모델링이 가능한데, 완벽히 대체하기엔 Self-Attention의 Cost가 Resolution에 따라 Quadratic하게 늘어나므로 Cost가 너무 크다. 따라서 CNN Backbone에 Transformer를 추가하거나, Convolution Block 일부를 Transformer로 대체하려는 시도가 있었다.
연구 목록
3. CNN Enhanced Transformer
Çovolution Inductive Bias
Convolution의 Inductive BIas는 효율적이지만, 충분한 Dataset이 주어졌을 때 성능의 Upper Bound를 제한한다. 최근 Transformer를 이용해 CNN을 강화하고, 수렴을 빠르게 하기 위한 시도가 있었다. 이러한 시도들은 다음과 같이 요약될 수 있다.
1.
Soft Approximation
연구 목록
2.
Direct Locality Processing
연구 목록
3.
Direct Replacements of the positional encoding
연구 목록
4.
Structural combination
연구 목록
4. Local Attention Enhanced Transformer
(1) ViT의 Patch 방식은 섬세하지 못해, Local 정보를 쉽게 손상시킨다. (2) Covolution은 데이터의 양이 커지면 Representation을 배우기 적합하지 않다. (3)Local-Attention은 Convolution에 비해 다양한 Representation을 학습할 수 있다. 따라서, Convolution을 제거하고 Local-Attention으로 Patch 방식을 커버하려는 시도가 있었다.
연구 목록
5. Hierarchical Transformer
Origin ViT는 고정 Resolution 구조를 갖고있어, Fine-Grained Feature를 잃고, 거대한 Cost를 사용한다. CNNs 처럼 Transformer에서도 Hierarchial 한 구조를 적용하려는 시도가 있었다.
연구 목록
6. Deep Transformer
모델이 깊어질수록, 복잡한 Representation을 모델링할 수 있다. 그러나 Transformer는 깊어질수록 Feature의 representation이 줄고(Attention collapse), Patch는 구분할 수 없는 latent representation으로 매핑된다(Over-smoothing). 이런 문제를 해결하기 위해 다방면의 시도가 있었다.
연구 목록
7. Transformers with Self-Supervised Learning
Self-Supervised가 NLP에서는 성공한 반면, CV Task에서는 아직 Supervised Pretrain이 지배적이다.
최근 CV Tasks에서도 Self-Supervised Learning Scheme들을 설계해보려는 다양한 시도가 있었다.
연구 목록
8. Discussion
1. Experimental Evaluation and Comparative Analysis
•
구조를 개선한 모델은 특정 조건(Model-Size, Task, Input Resolution)에만 최적화 되어있지만
DeiT, LV-VIT는 비교적 보편적으로 작동하는 모습을 보여준다.
•
VOLO, Swin이 Classification, Dense prediction에서 SOTA이며, Locality가 필수적임을 보여준다.
•
큰 모델에서 Covolution Patch Stem, Ealry Conv가 성능을 크게 향상시킨다.
이는 얕은 Layer에서 Fine-Grained Feature를 잘 포착해낼 수 있기 때문이다.
•
Deep Transformer는 큰 포텐을 갖고있다. 다만 Trade-off는 심층적인 추가 연구가 필요하다.
•
CeiT, CvT 같은 모델이 (~40M) 규모에선 큰 이점이 있다. 경량화를 위한 Hybrid Attention의 연구가치를 보여준다.
2. Overview of Development Trend on Visual Transformers
1.
처음엔 ViT는 NLP의 기본 모델을 차용하거나, Attention을 차용함으로서 재설계됐다.
2.
CNN에서의 Deep, Hierarchical 관련 구조를 ViT에 적용하려 했다.
3.
일부 연구는 Transformer의 이미지 능력을 끌어 올리기 위해 내부요소(PE, MHSA, MLP)에 집중했다.
4.
Locality가 다음 물결인데, 대부분 Local-Attention이나 Convolution을 이용해 Locality를 주입한다.
5.
Self-Supervised도 비중있게 다뤄지는데, 어떤 Task나 구조가 적합한지는 아직 불분명하다.
3. Brief Discussion on Alternatives
•
핵심질문은 Transformer가 Convolution을 대체할 수 있는가? 이다.
•
ViT가 Hybrid가 되어가고, Global Information이 점점 Local과 Mix되면서 No는 아니게 되었다.
•
그럼에도 Covolution은 얕은 Layer에서 Local, low-level Semantic 정보를 처리하기 너무 적합하다.
•
따라서, 이 둘을 적절히 섞는것이 Classfication의 돌파구 개척을 이끌것이다.
Transformer for Detection
A. Transformer Neck
(DETR) Object Query 를 기반으로 Detection 문제를 Set Prediction 문제로 푸는 연구들이다.
수렴이 느리고, 작은 물체에 대한 정확도가 낮다는 근본적인 문제가 존재한다. 이 문제를
(1) Sparse Attention, (2) Spatial Prior (3), Structural Redesign 세가지 방법으로 개선하려 했다.
DETR(Original)
첫 번째 End-to-End Transformer Detector
Object Query를 도입했으며 수작업이 필요한 과정을 제거했다.
1.
이미지에서 CNN으로 Feature를 뽑고 1D로 편다
2.
Positional Encoding을 넣고 Encoder로 넣는다.
3.
Object Query(Learnable Positional Encoding)는 Decoder로 넣는다.
4.
Prediction Head가 Box 정보와 Class 정보를 예측한다.
5.
(Train)Bipartite Mathing Loss를 이용해 Ground Truth와 Prediction 의 최적의 조합을 찾는다
1. Sparse Attention
DETR의 Decoder Embedding과 Global Feature사이의 Attention Cost가 크고, 수렴이 느린 문제를 Data-Depedent한 Sparse Attention으로 해결하려 했던 연구들이다.
연구 목록
2. Spatial Prior
수작업으로 만들어진 Feature들과 다르게, Object Query는 학습을 통해 암묵적으로 공간 정보를 배운다.
그러므로 Query Box의 관계가 직접적이지 않을 수 있다. 이런 문제를 (1) 1-Stage + Empiricial Infomation Prior (2) 2-Stage + Geometric Coordinate Init 으로 해결하려 했던 연구들이다.
Box의 관계가 직접적이지 않을 수 있다. 이런 문제를 (1) 1-Stage + Empiricial Infomation Prior (2) 2-Stage + Geometric Coordinate Init 으로 해결하려 했던 연구들이다.연구 목록
3. Strutural Redesign
Decoderd의 문제를 피하기 위해(특히 Cross-Attention) Encoder-Only 구조를 재설계한 연구들이다.
연구 목록
4. Transformer Detector with Self-Supervised Learning
UpStream Task를 모아놓은 UP-DETR이 있다. 주 목적은 DownStream Task를 더 잘하기 위함이다.
B. Transformer Backbone
위에서 다룬 Classification을 위한 Transformer 구조를 Backone으로 사용한다. Hierarchical(PVT)는 Multi Scale Feature를 배우기 위하여 사용하고, Local Enhanced 구조는 효율적으로 local-global Feature를 뽑아내기 위해 사용한다. 이런 Trasnformer Backbone 모델은 CNN Backbone Mode 보다 약 2-6.8% 정도 좋은 성능을 보이며, Dense Prediction에서 Transformer의 효과를 보여준다.
FPT
Transformer for Segmentation
Trasnformer는 (1) Patch-Based, (2) Query-Based 방식으로 Segementation에 적용되었다.
더 들어가면 (2) Query Based는 Object Query, Mask Embedding으로 구분할 수 있다.
A. Patch-Based
CNN은 High-level Feature를 원본 Resolution으로 매핑하려면 많은 Decoder Stack이 필요하다.
Patch-Based Transformer는 Image를 Patch Sequence로 처리하면 되어서 간단한 Decoder 만으로 원하는 성능을 뽑아낼 수 있다.
연구 목록
B. Query-Based
B-1. with Object Queries
3가지 훈련 방법이 있다. (a) Pre-Trained DETR의 Object Query를 이용해 Mask Head로 Task 수행
(b) Object Query가 Detection, Mask Task 둘 다 수행 (c) 둘 다 수행하는데 Box값이 Mask로 들어감
연구 목록
B-2. with Mask Embeddings
Query를 Mask를 예측하는데 직접 예측하려 했던 연구들이다. (d) Object Query와 Mask Query를 각각 병렬적으로 사용하는 연구, (e) Mask Query만 사용하는 연구
연구 목록
Discussion & Conclusion
A. Summary
Classification
[ Insight ]
1.
깊은 층에선 Hierarchical Transformer Backbone이 Over Smoothing을 막고, 연산 Cost를 줄여서 유용하다.
2.
낮은 층에선 Early Conv가 Low-level Feature 잡기 충분한 데다가, 연산 Cost도 작고 Robustness도 강화하기 때문에 유용하다.
3.
Conv Projection, Local Attention은 Locality를 강화해준다.
4.
Transformer가 Positional Encoding을 대체할 수 있다.
Detection
[ Insight ]
1.
Trasnformer Neck은 Encoder-Only보다 적은 계산량으로 Encoder-Decoder 장점을 챙긴다.
2.
Decoder는 필수적이지만, 수렴이 느리기 때문에 조금만 쌓는다.
3.
Sparse Attention은 계산 복잡도는 줄이고, 수렴을 빠르게 한다
4.
Spatial Prior는 수렴을 빠르게 해 성능 향상에 도움을 준다.
Segmentation
[ Insight ]
1.
Encdoer-Decoder 모델은 Mask Prediction 문제로 Subtask를 통합해 풀 수 있다.
2.
이런 Box-Free 접근법이 여러 벤치마크에서 SOTA이다.
3.
Box-Based Hybrid cascaded Model이 Instance Segmentation에서 성능이 더 좋다.
B. Discussion
How Transformer Bridge The Gap Between Language and Vision
NLP:
Vision
Word가 가장 기본적인 단위로 간주되며, 고차원, 고수준의 의미 정보를 담고 있다.
저 수준의 Vector Space로 임베딩 될 수 있다.
Pixel이 가장 기본적인 단위로 간주되며, Pixel은 저차원, 저수준의 의미 정보를 담고있다.
바로 임베딩시키기 적합하지 않다.
⇒ 이 주제의 Key는 Image-to-Vector Transformation, Maintain Image’s characteristics 이다.
The Relationship Between Transformer, Self-Attention and CNN
Convoluiton :
Inductive Bias 때문에 효율적인 Template Match를 수행할 수 있지만, Upper Bound가 낮다.
(CNN Inductive Bias : Locality, Translation Invariance, Weight Sharing, Sparse Connection)
Self-Attention :
충분한 Head가 주어지면, Convolution Layer를 표현할 수 있다. Local, Global Attention을 결합하면 Feature간 관계에 따라 Dynamic하게 Attention Weight를 만들어 낼 수도 있다. 그러나 SOTA CNN보다 낮은 Accuracy와 높은 Cost를 보여 실용적이지는 않다.
(Self-Attention Layer는 FFN이나 Short-connection 없이 깊게 훈련시키면 “token uniformity” Bias를 주입한다.)
Transformer :
Transformer는 Token간의 관계를 모델링하는 Self-Attention과 Feature를 뽑아내는 FFN으로 이루어져 있다. Global Modeling Capacity가 강력하지만 Convolution이 Low-Level Feature를 뽑거나, Transformer에 Locality를 효율적으로 넣어줄 수 있다.
Learnable Embeddings in Different Visual Tasks
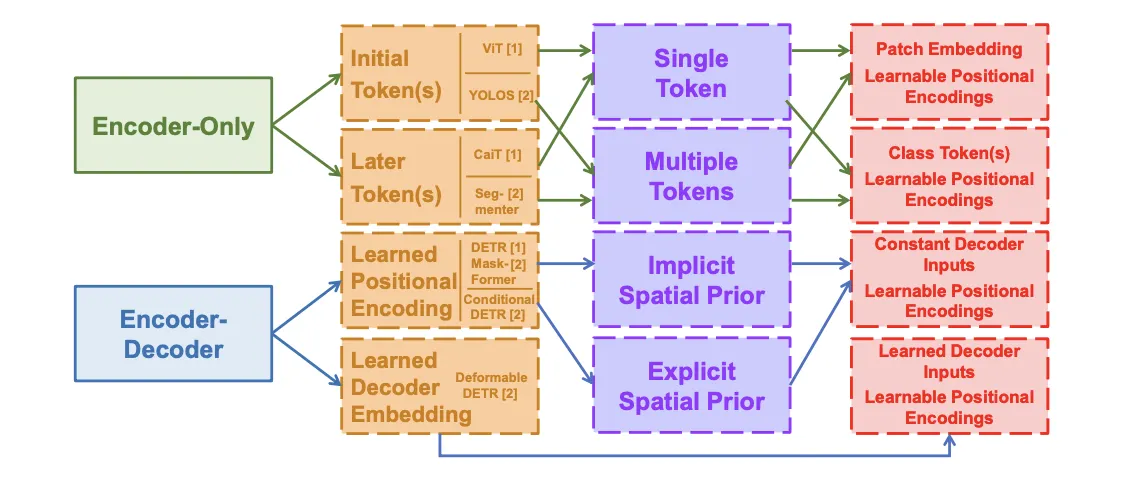
Future Reseach
Set Prediction
Bipartite Loss를 가진 Set Prediction 전략은 Dense Prediction Task에 광범위하게 적용되고 있다.
One-to-One Label 할당은 훈련 초기의 불안정성 때문에 최종 성능에 악영햘을 끼칠 수 있다.
Label을 다르게 할당하거나, Loss를 개선하면 새로운 Dectection Framework에 도움이 될 수 있다.
Self Supervised Learning
NLP에선 Self-Supervised Pre-Train→ Transfer 가 표준이 되었다.(with Masked AutoEncoder)
CV에선 Self-Supervised를 위해 Covonlution Siamese Network로 Contrastive Learning을 수행한다.
최근엔 Transformer를 이용해 NLP와 CV의 갭을 메우려 하고 있다.
Masked AutoEncoder or Contrastive Learning을 사용하는데, GPT-3같은 혁신이 없다.