
0. Abstarct
Detection Transformer (DETR)
1.
Object Detection을 Set Prediction Task로 정의했다.
2.
Bipartite Matching Loss로 One-to-One Matching을 유도했다.
3.
Threshold 설정, Anchor 설정 등의 수작업을 제거해 Pipeline을 간소화했다.
4.
Transformer Encoder-Decoder 구조를 차용했다.
5.
COCO BenchMark에서 Facster R-CNN과 견줄만한 성능을 보인다.
1. Introduction
Object Detection
1.
Object Detection의 목표는 관심있는 object에 대해 label, box 묶음을 예측하는 것이다.
2.
기존 연구는 Set prediction을 Direct하게 하지 않는다(회귀 근사로, 분류로 풀거나, anchor 등등)
3.
이러면 휴리스틱하게 box를 할당하게 되는 과정이 존재하고 이게 성능에 영향을 크게 미친다.
4.
딥러닝의 End-to-End 철학과도 맞지 않다.
DETR
1.
직접적인 Set Prediction 문제로 Object Detection을 풀어, Training Pipeline을 간소화 시켰다.
2.
Self-Attention이 중복 제거와 같은 Set Prediction을 해결하기 적합해 Transformer 구조를 사용했다.
3.
Predict Set  Ground Truth Set을 바로 매칭시키는 Bipartite Loss fuction을 이용했다.
Ground Truth Set을 바로 매칭시키는 Bipartite Loss fuction을 이용했다.
Ground Truth Set을 바로 매칭시키는 Bipartite Loss fuction을 이용했다.4.
Globality때문인지 큰 Object에 대해 강력했으나, 작은 Object에 대해서는 아쉬웠다.
Novelty of DETR
1.
Predict objects at once
•
이전 연구들은 Decoding에 RNN을 사용해, DETR은 Transformer를 사용해 Parellel하다.
•
Predicted Set을 1:1로 할당하는 Bipartite Matching Loss덕에 순서도 상관없다.
2.
Trained End-to-End
•
Prior로 사용하는 Spatial Anchors나 Non-Maximal Suppression이 없다.
•
Prior를 위한 Cstom Layer가 필요없으며, Framework로 쉽게 구현이 가능하다.
2. Related Work
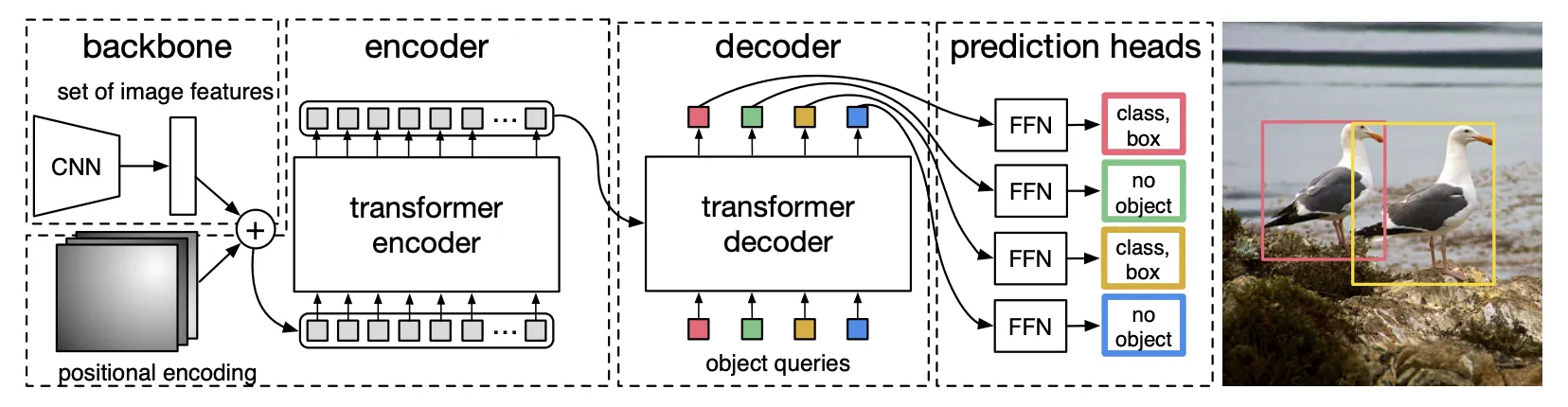
3. The DETR Model
3.1 Object Detection set prediction loss
DETR는 Decoder를 통해 개의 Set을 예측하는데, 은 고정된 값으로 일반적으로 이미지에 있는 Object 갯수들보다 상당히 커야한다. 매칭을 위해 각 Set의 정보를 Ground Truth와 비교해 점수를 줘야하는데, 이를위해 다음과같은 Loss가 사용된다.
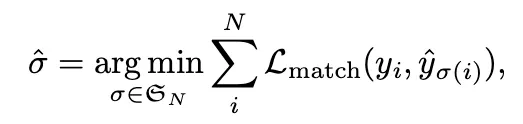
Loss Detail for Bipartite Matching
1.
Set of Ground Truth
•
→ 는 class, 는 Object의 좌표를 의미한다.
•
이 일반적으로 Object보다 많으므로, 특정 는 로 Padding된다.
2.
N개의 예측된 Set
•
→ ( : Probabilty of Class, : Index)
3.
와 사이의 Bipartite Matching을 찾기 위해, N개의 원소 사이의 최소 Cost의 순열을 찾는다.
•
와 의 번째 원소의 Matching Cost 구한다는 뜻
•
조합은 헝가리안 알고리즘을 통해 계산된다.
Matcing Cost :
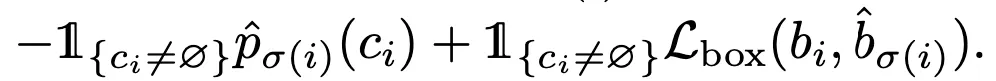
1.
Class Loss와 Box Loss의 선형 결합이다.
2.
Ground Truth의 빈 Slot()은 제외하고 구한다.
3.
이 식이 기존의 Dectector들의 Hand-Crafted Feature 역할을 한다.
Hungarian loss
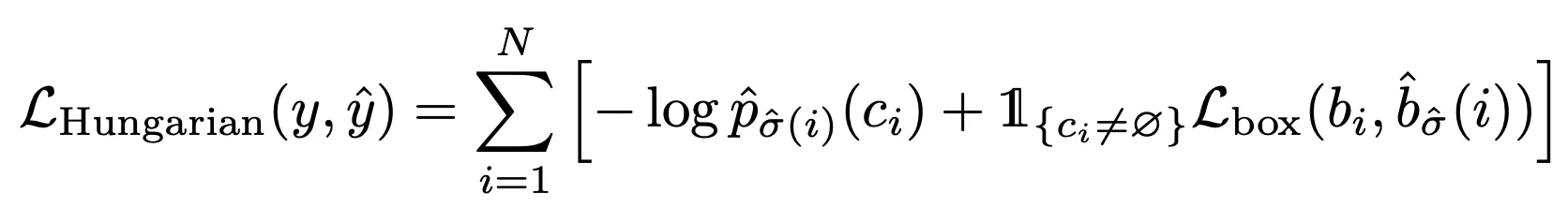
1.
Matching Cost를 통해 얻은 최적의 조합인 에 대해 Loss를 구한다.
2.
실제로 사용할 때는 불균형을 고려하기 위해 일 때 log term의 가중치를 1/10로 줄인다.
(Faster R-CNN의 샘플링 방법론과 유사하다)
Bounding box loss :
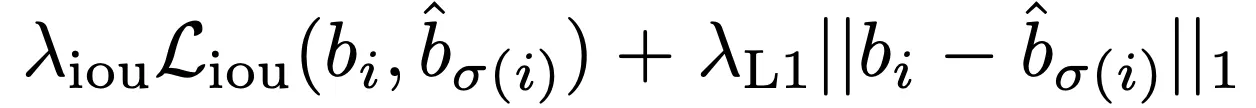
1.
일반적으로 Detector에서 사용하는 Bounding Box Loss는 Ground Truth Relative하게 계산한다.
2.
DETR은 Direct하게 Absolute Position을 뽑아주므로 추가적인 과정이 필요하다.
3.
이때 L1 Loss는 Box Scale에 따라 영향을 받는 문제가 있기때문에
4.
Genralized IoU와 L1 Loss를 가중합해서 사용한다.
3.2 DETR architecture
DETR은 간단한 구조로 이루어져있다. (1) CNN Backbone, (2) Encoder-Decoder Transformer, (3) FFN
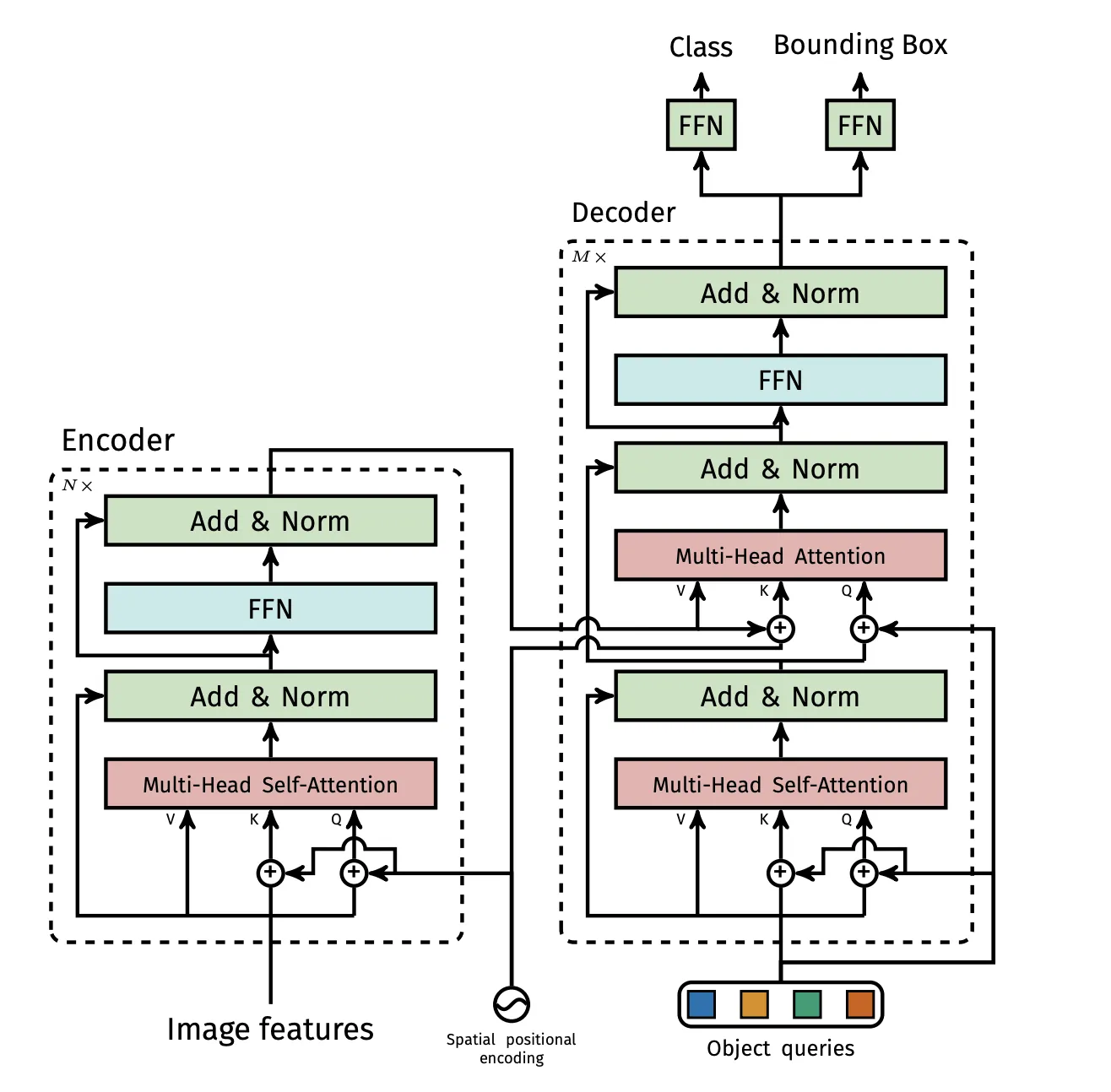
CNN Backbone : RGB 채널의 이미지를 입력받아 FeatureMap 으로 변환시킨다.
Transformer Encoder
1.
1x1 Conv를 이용해 2048 → 로 차원을 줄인다.
2.
Flatten해서 Sequence 형태로 만든다.
3.
Fixed Positional Encoding을 더해서 입력한다. (Attention할 때 마다 더해진다)
Transformer Decoder
1.
Decoding을 병렬적으로 수행하며, Query로서 Learnable Positional Embedding을 사용한다.
2.
Self-Attention, Encoder-Decoder Attention을 통해 각 Query가 Global Context정보를 갖게된다.
Prediction feed-forward networks(FFN) : 3-Layer Relu로 이루어져 있다.
Auxiliary Decoding Losses (보조 Loss)
•
Decoder 훈련할 때 보조 Loss를 넣으면 Object의 숫자를 정확히 세는데 도움되는것을 발견했다.
•
각 Decoder Layer마다 Layer-Norm + FFN과 Hungarian Loss를 이용해서 보조 Loss를 사용한다.
•
각 FFN과 Layer-Norm의 가중치는 공유된다.
4. Experiments
Dataset
•
Segmentation : Panatonic
•
Detection : COCO 2017 (Train 118k, Valid 5k) 각 이미지에 평균적으로 7 개의 객채, 최대 63개 존재
Technical Detail
•
Optimizer : AdamW
•
Augmentation : Resize, RandomCrop,
•
Transformer : lr = , Xavier init, Dropout 0.1,
•
BackBone : lr = , decay to ResNet Pre-Trained, Frozen Batchnorm
◦
FeatureResolution 키우기(DC5) : 첫 Conv의 Stride를 제거하고, 마지막에 Dilation을 추가했다.
•
Training Schedule : 300 Epoch, 200 Epoch부터 1/10로 줄임, V100 16대로 3일이 걸렸다.
4.2 Ablation Study
Number of Encoder Layer

1.
Global Image Level의 Self-Attention이 미치는 영향을 알고 싶어서 Encoder를 건드려 보았다.
2.
Encoder의 Layer 를 없애면 4%p 정도 성능 하락, 특히 큰 물체에 대해서는 6% 하락 했다.
3.
Last Layer의 Attention Map을 보면 Encoder에서 이미 물체를 구분하고 Localization 까지 되어있다.
Number of Decoder Layer

1.
각 Decoder Layer의 보조 Loss용 FFN으로 Stage 마다의 Decoder Layer의 성능을 평가할 수 있다.
2.
First Layer 와 Last Layer의 성능 차이가 굉장히 컸다. (뒤로 갈수록 크게 개선됐다)
3.
Attention Map을 보면 머리, 발끝같은 경계쪽을 Local하게 잡는다.
4.
Encoder가 Instance를 나눴으니, Decoder가 Class와 Boundary에 집중하는듯 하다.
Importance of FFN
1.
Transformer의 FFN은 1x1 Conv로도 간주할 수 있다.
2.
Transformer Layer에서 Attention만 남겨보려고 FFN을 없애봤다. (Param: 41.3M → 28.7M)
3.
FFN을 없앴더니 2.3 AP가 떨어졌다.
Importance of positional encodings
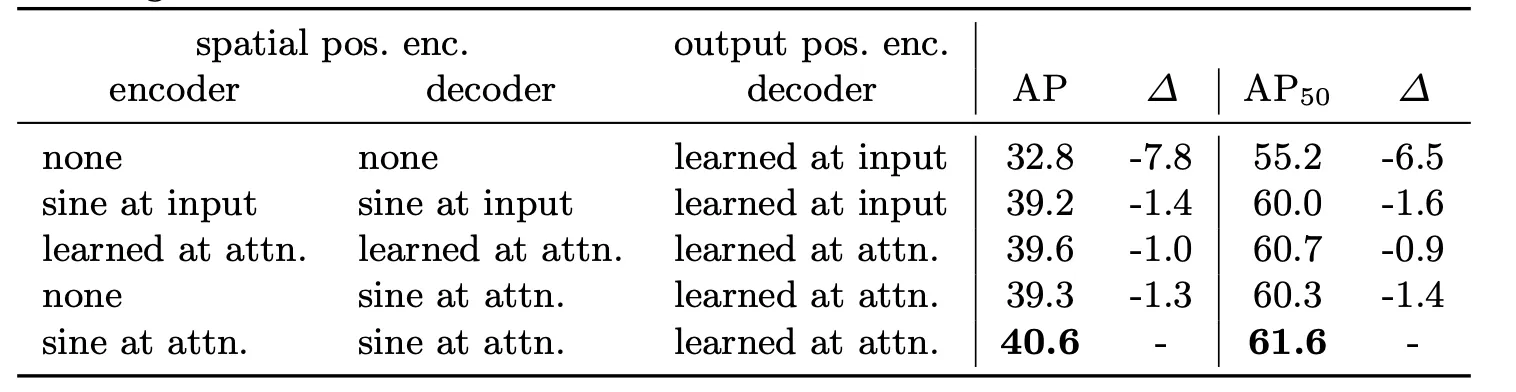
1.
DETR에 사용되는 Positional Encoding은 Spatial, Output Encoding(Object Queries) 2개가 있다.
2.
Spatial은 Encoder, Decoder 모두에 Attention할 때 마다 Fixed(Sine)로 넣고
3.
Object Query는 Attention할 때마다 Learnable로 넣는게 성능이 가장 좋았다.
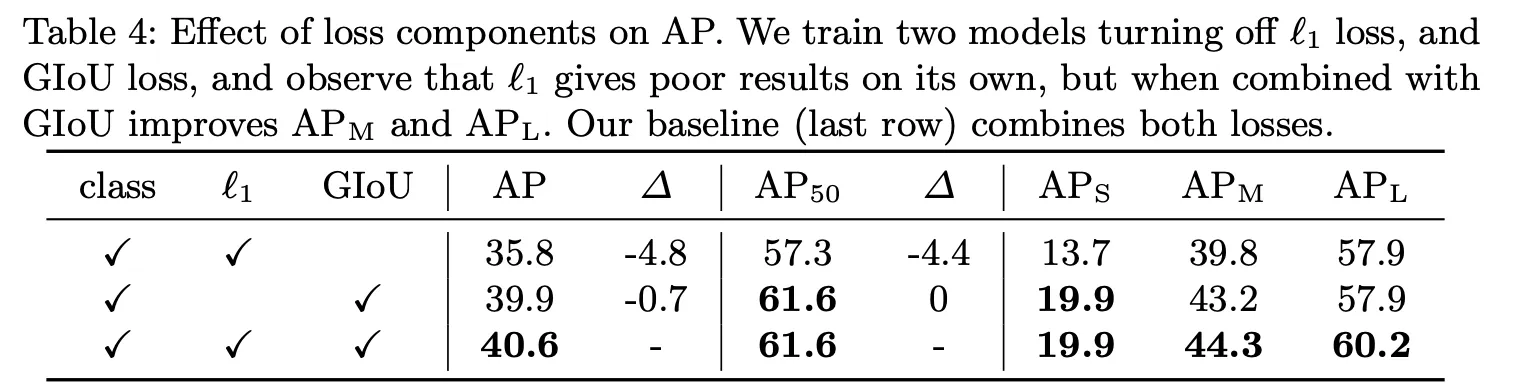
Loss Ablations : GIoU Loss가 성능에 가장 큰 영향을 끼쳤고, L1과 같이 사용하면 성능이 더 좋았다.
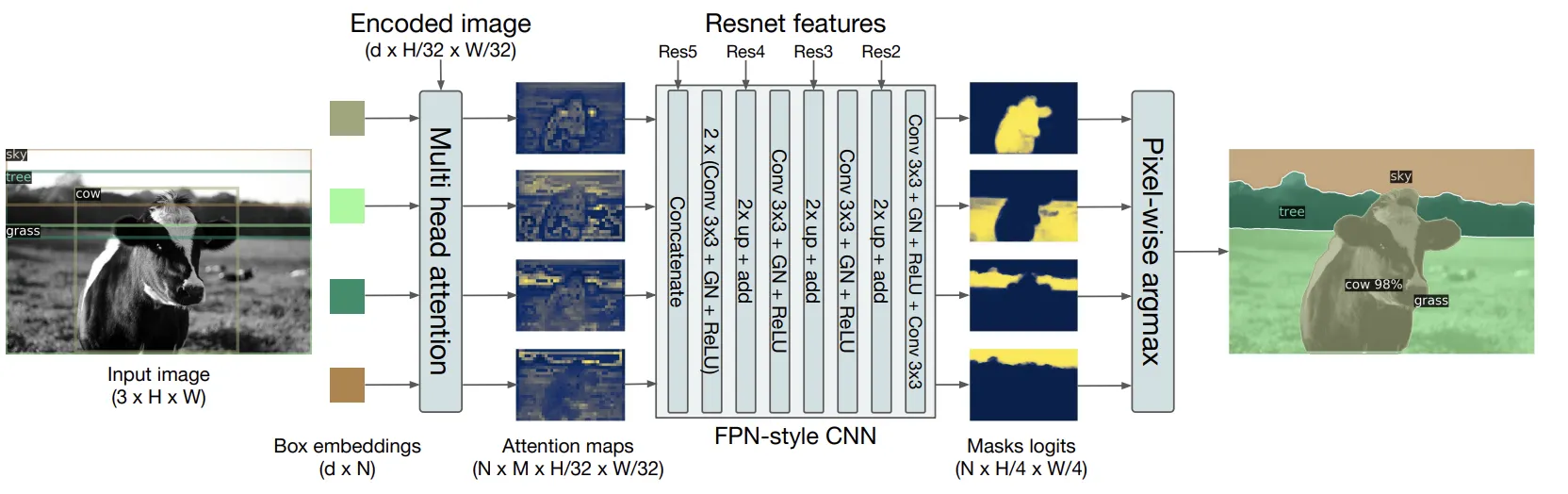
4.4 DETR for panoptic segmentation
Faster R-CNN을 Mask R-CNN으로 확장하듯이, DETR도 Decoder Output에 Mask Head를 달 수 있다.
COCO Dataset의 Panoptic Annotation을 사용했다(53 Stuff(셀수 없는 Object), + 80 Things)
5. Conclusion
DETR은 Bipartite Matching Loss을 이용한 Direct Set Prediction Task를 수행하는 Transformer기반 새로운 Object Detection System이다. 최적화된 Faster R-CNN과 COCO Dataset에서 비교할만한 성능을 달성했다.