



2020.07.27

1. Introduction
배경
많은 Neural NLU 모델에서, Pre-Trained된 Word Representations은 매우 중요한 역할을 합니다.
(Embedding의 질이 하위 Task의 성능에 큰 영향을 끼칩니다)
하지만 Representation을 '잘 학습' 시키는건 쉬운일이 아닌데요, 이유는 다음과 같습니다.
1.
단어 사용의 복잡한 특성을 알맞게 모델링 해야하고 (문법에 맞는지, 말이되는지)
2.
이 단어들이 문맥에 따라 어떻게 달라지는지를 모델링 해야합니다. (동음이의어, 다의어 등..)
저자는 이 두 가지 어려움을 직접적으로 해결할 수 있는 'Deep Contextualized Word Representation' 라는 새로운 방법론을 제시합니다.
설명
ELMo는 문맥에 관계 없이 한 Token에 하나의 Representation이 할당되는 기존의 Word Embedding 방법론 (ex: word2vec) 과는 다르게
문장 전체를 기반으로 Token의 임베딩이 결정됩니다. ( 문장 수준 임베딩 )
이는 대규모 Corpus를 Bidirection - LSTM를 언어모델(Language Model) 방식으로 훈련시킨 Vector를 이용하기 때문인데,
이 때문에 ELMo(Embeddings from Language Models) 라는 이름이 붙게 되었습니다.
기존의 Bi-LSTM 모델을 사용할 땐 마지막 Layer의 Output 값의 사용이 일반적인 것과 다르게,
ELMo는 모든 Layer의 Representation를 선형결합해 사용합니다.
이는 계층에 따라 포착하는 Ascept가 다르기 때문입니다.
•
Low - Level State : Syntax(문법적인) 의미를 포착해냄 (품사 Tagging과 같은 Task에 적합)
•
High - Level State : Context-Depedent(문맥에 따른) 단어의 의미를 포착해냄 (Word-sense disambiguation)
이렇게 Bid-LM으로 학습된 특성이 다른 State들을 Task에 맞게 선형결합하여 사용하는 것이 ELMo의 핵심 아이디어 입니다 !
* Character Convolution
상술했듯이, 기존 Word Embedding 방법론들은
하나의 Word에 대하여 문맥과 관계없는 하나의 Representation이 할당되는 문제점이 있었습니다.
이를 극복하기 위해 Subword Unit(준단어)를 이용하는 방법론이 주로 사용되어왔는데,
ELMo또한 Character 단위 Conv를 첫 Layer로 이용해 Subword Information을 추출했습니다.
2. ELMo
ELMo의 핵심 아이디어는 다음과 같습니다.
1.
Character 단위 Conv를 통과한 Vector들을 2-Layer Bi-LM에 통과시킴 (Bi-LM Layer)
2.
계산된 각 Layer의 Representation을 선형결합해 사용(ELMo Layer)
3.
이를 통해, Bi-LM을 이용한 대규모 Corpus의 Semi-Supervised Learning을 가능하게 함(Pre-Trained Bi-LM Architecture)
4.
학습된 Representation을 이미 있는 NLP 구조에 쉽게 통합시킬 수 있음 (Using biLMs for supervised NLP tasks)
1. Bi-LM Layer
Bi-LM은 Bidirection - LSTM를 언어모델(Language Model) 방식으로 훈련시킨 모델을 말합니다.
여기서 언어모델(LM)은 단어 시퀀스 즉, 문장의 '그럴듯 함'을 확률 단위로 할당하는 모델입니다.
이 모델은 단어 시퀀스 즉, 문장이 주어지면 다음 단어를 예측하는 방식으로 학습됩니다.
Ex)
•
= { 나는, 오늘, 맛있게, 밥을 } 일 때
•
에 '먹었다' 가 오도록 학습합니다.
이를 수식으로 표현하면 다음과 같습니다.
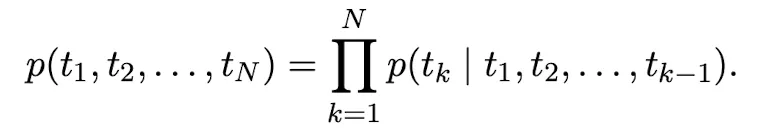
당시 SOTA Neural LM들은 다음과 같은 순서로 연산이 진행되었습니다.
1.
Character 단위 CNN을 이용해 맥락 독립적으로 Representation을 계산합니다 → (는 Token 번호)
2.
Representation값을 L개의 Forward LSTM로 전달해 맥락 의존적으로 Representation을 계산합니다→ (=)
3.
Top Layer의 결과값인 를 이용해 을 예측합니다(Softmax)
ELMo의 Forward LM도 이런 방식으로 연산이 진행됩니다.
Backward LM 을 이용해 를 예측하는 즉, 반대의 Sequence로 연산이 진행되고,
각 모델을 Joint해 Log likelihood를 최대화 하는 방향으로 학습이 진행됩니다.
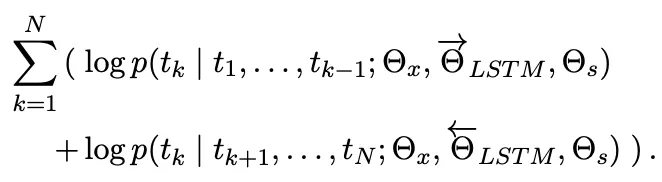
2. ELMo Layer
Bi - LM을 거치고 나면, Token당 개의 Representation이 계산됩니다.
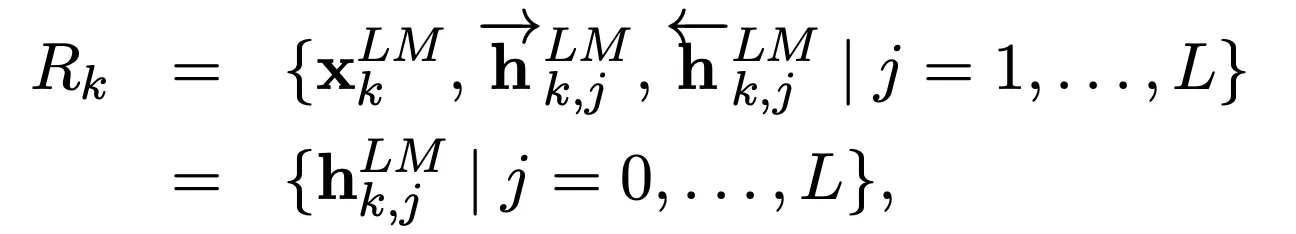
(CNN 1개,Forward LM L개, Backward LM L개)
(=Token Layer, = [; ] )
ELMo Layer는 하위 Task를 수행하기 위해 위에서 계산된 Representation들을 선형 결합하는 역할을 합니다.
선형 결합은 Task에 따라 Representation을 가중합하는 형태로 이루어지는데, 수식으로 표현하면 다음과 같습니다.
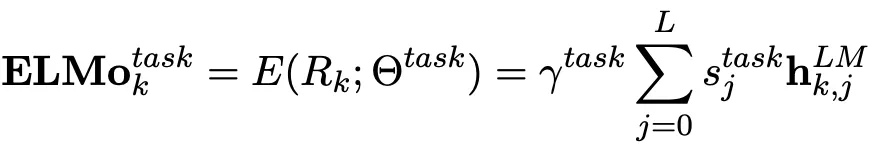
는 Task에 중요한 정도가 softmax로 Normalize된 Parameter 이며
는 Task에 사용되는 ELMo Vector의 크기 자체를 결정하는 Hyper-Parameter 입니다.
3. Pre-Trained Bi-LM Architecture
ELMo의 Bi-LM은 기존 Bi-LM들과 유사한 구조를 이용하지만,
원활한 Joint Traning을 위해 LSTM 사이에 Residual Connection을 사용합니다.
또한 Character 단위 Representation을 사용하면서 성능과 Model size를 모두 고려하기 위해
•
CNN : 2048 Character n-gram Conv → Highway-Network + Projection → 512차원 Embedding
•
LSTM : L=2 인 Bi-LSTM ,Units = 4096, Residual Connection과 Projection 적용
이 구조로 대규모 Corpus를 학습시키면 어떤 Task에든 Representation을 사용할 수 있고,
대부분의 Task에서 ELMo를 Fine-Tuning 하는 것만으로도 유의미한 성능 향상을 보였습니다.
4. Using bi-LMs for supervised NLP tasks
Pre-Trained Bi-LM을 어떻게 하위 Task에 사용할 수 있을까요?
우선 대부분의 NLP 모델들은 일정한 구조로 학습됩니다.
1.
Token을 Pre-Trained Embedding을 이용해 맥락 독립적인 Representation 연산
2.
CNNs,RNNs를 이용해 맥락에 민감한 Representation 연산
따라서 Pre-Trained Bi-LM을 이용하기도 쉬운데,
(1) 각 Token에 대해 Bi-LM의 Representation을 연산하고 (가중치 동결)
(2) ELMo Layer를 통해 Concat된 Representation을 Task RNNs,CNNs로 넘겨 사용합니다. ( 학습)
3. Result
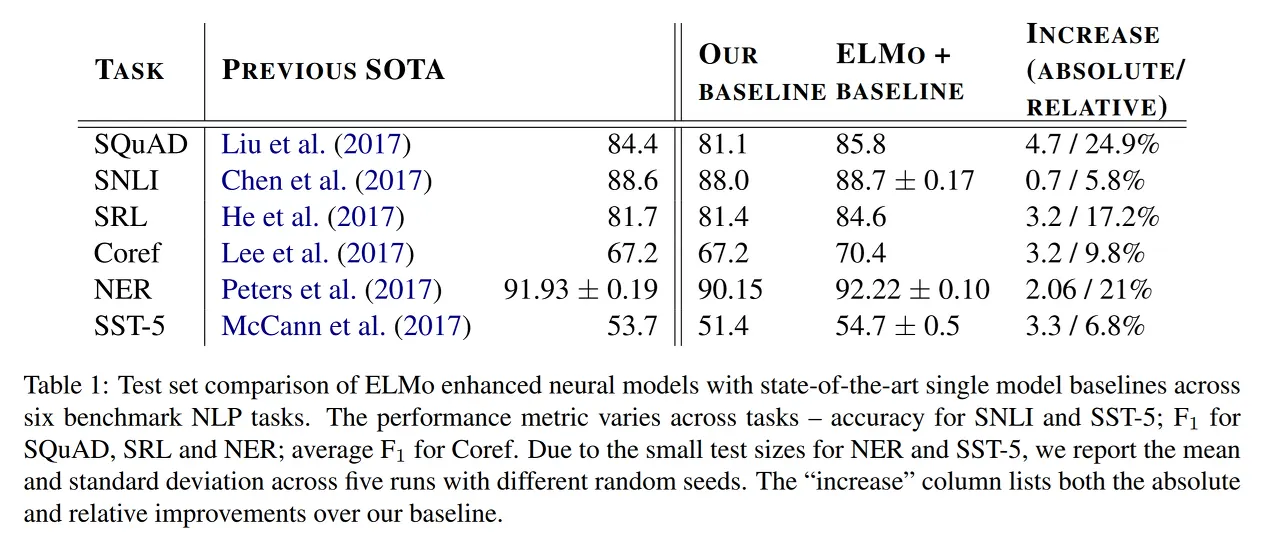
위 표는 기존 모델에 ELMo를 적용한 결과를 보여주고 있습니다.
대부분의 Task에서 당시 SOTA를 능가하는 성능 지표를 보여주고 있습니다.
4. Conclusion
ELMo는 대규모 Corpus를 이용해 Bi-LM을 학습시켜 Deep하고 문맥 의존적인 Representation을 얻는 접근법을 도입했고,
이를 이용해 대부분의 NLP Task에서 유의미한 개선을 이루어 냈습니다.
여러 실험을 통해 LM의 각 Layer별로 포착하는 aspect가 다른점을 확인했으며,
나아가 Task에 따라 Layer를 조합하여 사용하는 방법론을 제시했습니다.
NLP의 흐름에도 큰 영향을 미쳤는데
1.
LM을 이용한 Sentence 단위 Embedding을 제시했습니다.
2.
대규모 Corpus를 학습시켜, 하위 Task에 Transfer Learning 하는 방법을 일반화 시켰습니다.