
Abstract
Graph 데이터에 딥러닝을 적용하는 연구들이 Recsys Task에서 놀라운 성능 발전을 보인다. 그러나 이런 연구들은 Web-Scale Recommendation에서 바로 적용 가능할 만큼 실용적이진 못하다.
저자들은 이를 지적하며 Pinterest의 Large-Scale Graph에도 적용 가능한 효율적인 GCN Framework PinSAGE를 제시한다. Pinterest가 가지고있는 30억개의 Node 와 180억개의 Egde위에서 학습시켜 Offline, Online Test에서 놀라운 성능향상을 보였다.
Introduction
Previous Work : GCN-Based Model
GCN-Based 모델들은 강력하지만, 대부분의 연구가 Large-Scale Graph 위에서 사용 불가능하다. 예를들어 당시 존재했던 GCN-Based Recommender들은 학습과정에서 Full-Graph의 Laplacian(인접행렬)을 사용했다. Pinterest의 Full-Graph Laplacian은 최소 30억30억 크기의 행렬인데, 이걸 메모리에 올릴 순 없다.
Present Work: PinSAGE
저자들은 위 문제를 지적하며 확장 가능한 GCN Framework PinSAGE를 제시한다. 핵심 요소는 다음과 같으며, 아래의 요소를 이용해 Pinterest의 추천 퀄리티를 극적으로 개선시켰다.
On-the-fly Convolution
•
Node의 전체 이웃을 사용하는게 아니라 가까운 이웃들을 샘플링하여 사용한다.
Producer-consumer minibatch construction
•
학습과정에서 GPU 사용을 극대화 하기 위해 Producer-Consumer 구조를 사용했다.
•
Producer는 큰 Memory가 필요한 CPU-Bound 작업을 처리한다. (Node Sample, Fetch Feature)
•
Consumer는 GPU-Bound Tensorflow Task를 CPU에서 처리한 Graph에 대해 수행한다.
Efficient MapReduce Inference
•
수십억개 Node에 대한 Embedding을 최대한 중복연산 없이 뽑아낸다.
Constructring Convolutions via random walks
•
Importance Score을 기반으로한 Short Random Walk를 이용한다.
Importance Pooling
•
Random Walk기반 유사도를 계산해 Neighbor Importance Weight로 사용한다. (46%  )
)
) Curriculum Training
•
학습과정에서 점점 더 어려운 Sample을 제공한다. (12% )
)Method
Pinterest Data
Pinterest는 일종의 Contents Discovery App이다. User는 Online Content에 대해 북마크인 Pin을 남길 수 있다. 유저는 저장된 Pin을 Board로 묶을 수 있으며, Board 내부의 Pin들은 테마적으로 유사하다고 가정한다.
Pin을 남길 수 있다. 유저는 저장된 Pin을 Board로 묶을 수 있으며, Board 내부의 Pin들은 테마적으로 유사하다고 가정한다. Pinterest는 자신들의 환경을 Pin과 Board 두 가지 Node Type이 존재하는 Bipartite Graph로 규정했다. Graph로 규정함으로서 Pin의 Attributes(Text, Image, etc..)와 더불어 Structure 정보를 이용해 높은 품질의 Embedding을 만들고, 추천에 활용하는것을 연구의 목표로 설정했다.
Model Architecture
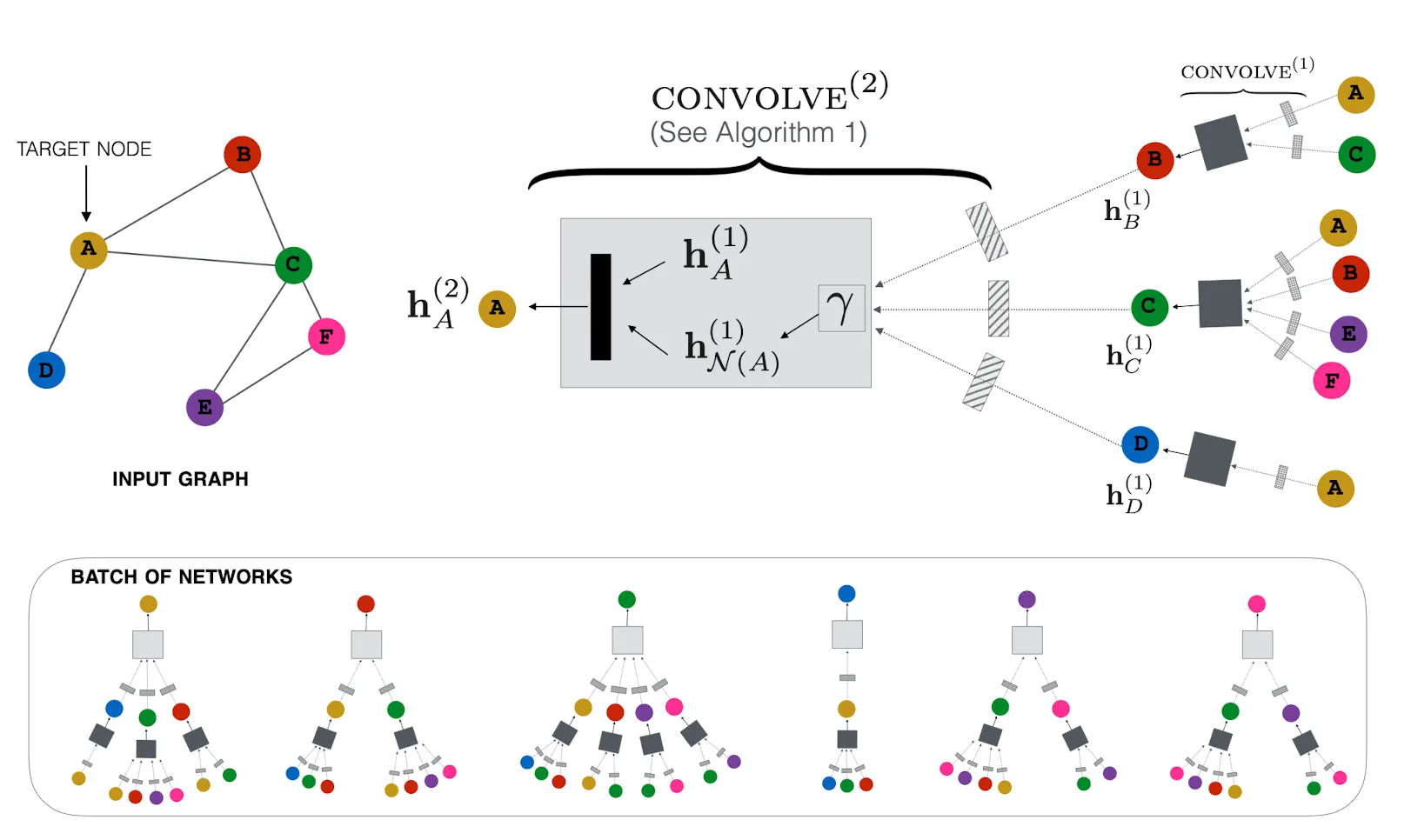
1. Forward Propagation

1.
관심있는 Node의 이웃 Feature를 FFN에 통과시킨다
2.
중요도 바탕으로 정보들을 가중 Aggregation 시켜 Vector로 만든다.
3.
관심있는 Node와 이웃 정보 Vector를 Concat해 FFN에 통과시킨다
4.
결과물을 L2 Normalize한다.
2. Importance-Based Neighborhoods
PinSAGE에서는 Random Walk로 부터 구해진 거리정보를 이용해 이웃을 Sampling한다. 구체적으로는 관심 있는 Node로 부터 Random Walk를 수행한 뒤 이웃 노드들의 방문 횟수를 Normalize한 수치를 거리이자 Importance로 사용한다. 이후 관심있는 Node로 부터 가까운 Top Node를 이웃으로 정의한다.
이렇게 Importance-Based Neighborhood를 정의함으로서 두 가지 이점을 가져갈 수 있다. 첫 번째는 이웃의 크기를 로 고정할 수 있다는 점(GraphSAGE와 동일)이고 두 번째는 Aggregation 단계에서 Importance를 활용할 수 있다는 점이다. 위의 Algorithm 1 을 보면 Aggregation Function 의 인자로 가 들어가는 것을 볼 수 있는데, 실제로 PinSAGE는 를 가중 평균으로 구현했으며 로는 이웃별 Noramlize 방문 횟수를 사용했다. (이 테크닉을 Importance Pooling이라 부른다)
Model Training
PinSAGE는 Max-Margin Ranking-Loss를 이용해 Supervised로 학습한다. 이때 Supervision으로 작용하는 정보는 Item Pair 인데, 로 Notation 된다. 는 Query Item, 는 Related Item이며 이렇게 묶인 Item 사이엔 관련이 있다고 가정한다. 학습의 목표는 Pair로 묶인 Item을 가깝게 Embedding하는 것이고, Max-Margin Ranking Loss가 이를 위해 사용된다.
1. Loss Function : Max-Margin Ranking Loss
상술했듯이, 학습의 목표는 관련 있는 Item을 가까이 Embedding하는 것이다. 이를 위해 Positive Example의 Inner Product를 최대화 하는 동시에, Negative Sample에 대해선 그 값을 최소화 하는 Loss를 사용했다.
2. Sampling Negative Items
우선 효율적인 Sampling을 위해 각 Batch마다 500개의 Negative Item Set을 뽑는다. 이 Negative Sample은 모든 Training Example에서 공유된다. 경험적으로 실험해 보았을 때 Node마다 Sampling한 것과 Batch마다 Sampling한 것 과의 성능 차이가 거의 없다.
Sampling 방법도 사려깊게 설계해야하는데, Uniform하게 Negative Sample을 뽑으면 모델 입장에서 너무 쉬운 문제이기 때문에, Backprop될 만한 정보가 거의 없다. 실제 Pinterest의 Pin을 생각해보면, 전체 Pin에서 무작위로 뽑은 500개의 Pin이 Query와 관련있을 확률이 거의 없다.
풀어야 하는 문제는 20억개 Pin 중에 가장 관련있는 한 자릿수의 Pin을 찾는건데, Uniform Sampling으로 학습을 시킨다면 결국 모델이 ‘관련있는 Pin’과 ‘추천 해주어야 하는 Pin’을 잘 구별하지 못할 확률이 크다.
위 문제를 해결하기 위해, Query와 관련있지만 Positive Sample만큼은 관련있지 않은 Hard Negative Sample이라는 개념을 사용한다. 이 Sample들은 Query로부터 추출한 PageRank Score 순위가 2000 ~5000등 사이인 Node를 이용한다.

위와 같은 방법으로 Hard Negative Sample을 추출하면, Item을 더 정교하게 구분하도록 학습되지만, 수렴하는데에 필요한 Epoch이 2배로 늘어난다. 이를 완화하기 위해 에폭별로 Hard Negative Sample을 늘려나가는 식으로 학습을 스케쥴링 한다. 구체적으로는 번째 Epoch은 개의 Hard Negative Sample을 학습에 사용한다.
Experiment
Experiment Setup
PinSAGE의 Embedding 품질을 (1)Query와 관련있는 Pin 추천, (2)User의 Feed에 Pin 추천, 두 가지 Task를 통해서 검증했다. 첫 번째 Task는 Embedding Space에서 Query Pin과 가까운 개의 Pin을 가져와 풀었고, 두 번째 Task는 가장 최근에 저장한 Pin을 Query Pin으로 사용했다. 실험은 모두 실제 Production 환경에서 배포되어 User Engagement를 기반으로 한 A/B Test 또한 진행했다.
1. Training Details and Data Preparation
Positive Sample의 경우 실제 Historical User Engagement 데이터를 사용했다. 와의 Interaction 직후에 와 Interaction 한 경우에만 Positive Sample로 사용하고, 이외에는 Negative Sample로 간주했다. 그렇게 추출된 12억개의 Positive Pair를 학습에 이용했으며, 7:1:2 비율로 Train/Valid/Test Set을 분할했다.
2. Feature Used for Learning
Visual 정보의 경우 VGG-16을 이용해 4096차원으로 임베딩했고, Textual 정보의 경우 word2vec을 이용해 256차원으로 임베딩 했다. Log Degree또한 Feature로 사용했다.
3. Baselines for comparison
성능 비교를 위해 사용한 모델들은 다음과 같다. (1) KNN with Visual Embedding (2) KNN with Textual Embedding (3) KNN with Combined Embedding (4) Pixie : Random walk Based Ranking Model 위의 네 가지 모델과 =2, = 1024, =2048 세팅 PinSAGE 모델을 비교했다.
Offline Evaluation
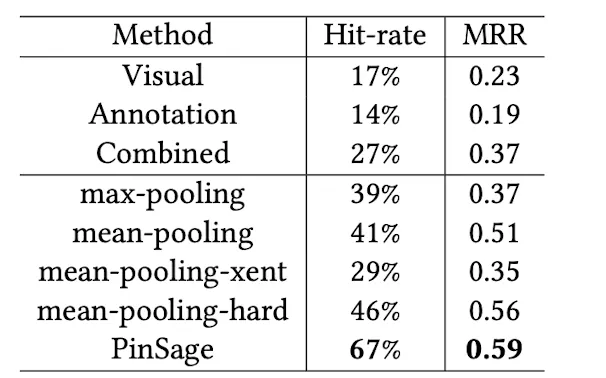
Hit Ratio
Query의 Positive Sample이 Top-K Nearest Neighbor안에 존재할 확률을 재는 Metirc이다. PinSAGE에선 K를 500개로 설정하였다.
MRR(Mean Reciprocal Rank)
Query의 Positive Sample이 얼마나 가까운지(Rank)를 재는 Metric이다. 아래와 같은 수식을 통해 계산된다. (는 Query로 부터 가 몇 번째로 가까운 이웃인지를 나타낸다.)
Training and Inference Runtime Analysis
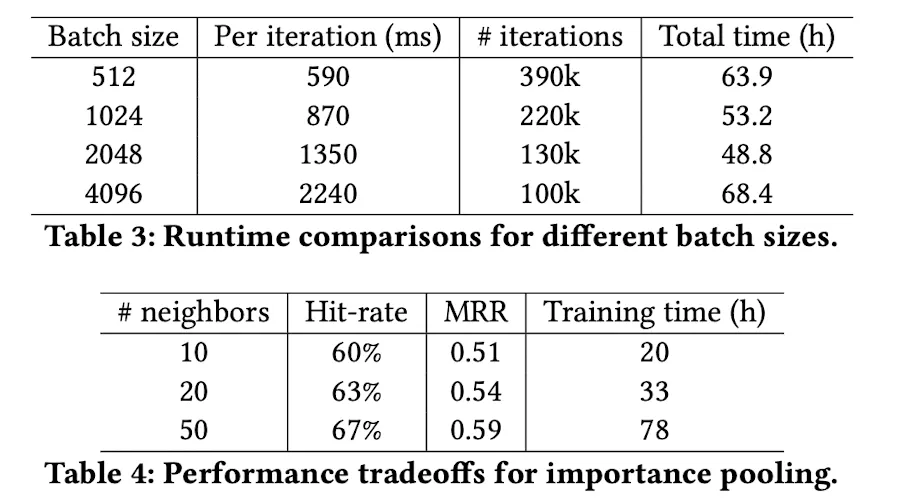
Importance Pooling 이웃의 수 에 따른 성능 Table이다. 실험 결과 50 정도가 효율적인 연산을 하면서 정보를 풍부하게 전달할 수 있는 이웃수이다.
Conclusion
PinSAGE는 Random-Walk 기반 GCN Framework이다. Web Scale Graph에서 동작할 수 있도록 많은 고민을 했으며, Importance Pooling과 Curriculum Training을 통해 Embedding Performance를 극대화 했다. 유저 테스트 결과도 기존 방법론 + Pixie 대비 준수한 성능을 보였으며, 다른 연구로 확장될 여지가 있다.