

Abstract
•
SASRec 이전엔 Markov Chain(이하 MC)과 RNN을 이용해서 Sequence Modeling했음
•
MC는 Action이 Sparse한 데이터에서 강력하고 RNN은 Dense한 데이터에서 강력함
•
Attention기반의 Transformer를 이용해 두 방법의 장점을 적절히 섞은 모델을 만들었음
Methodology
SASRec
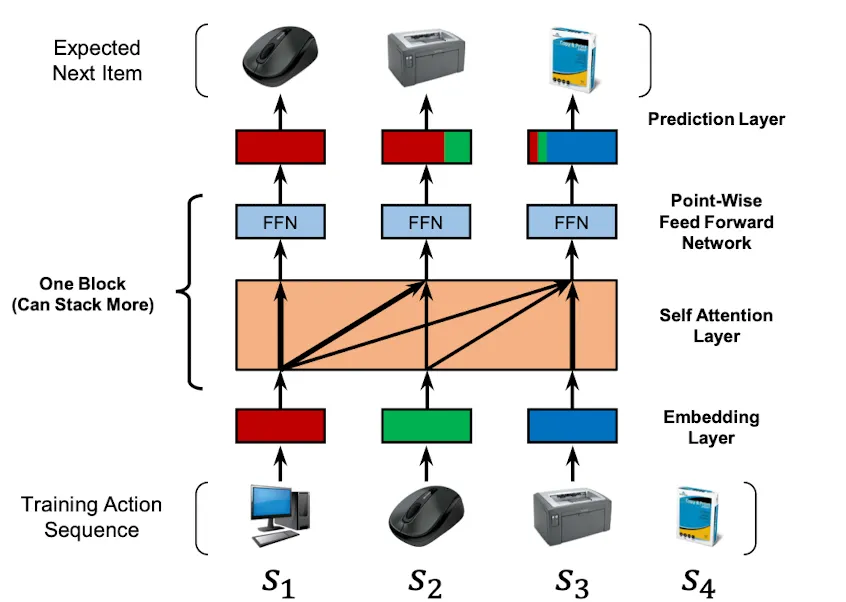
•
User Action Sequence 가 주어졌을 때
•
모델은 시점마다 이전 Sequence를 이용해 시점의 Item을 예측하도록 학습함
•
즉 Sequence Pair 두 개가 있어서, 각 시점별로 Shift된 Item을 맞추도록 학습된다고 보면 됨
Embedding Layer
•
각 Item은 차원의 Embedding을 가지고 있음, Padding은 으로 처리됨
•
Learnable Postional Encoding을 더해서 Transformer Block에 넣어줌
Self-Attention Layer
•
일반적인 Transformer와 같음
•
다만 학습 과정에서 미래의 Sequence Item을 못보도록 Casual Attention Masking을 해줌
•
FFN 까지가 하나의 Block이고 여러개 쌓을 수 있음
Prediction
•
Item Embedding은 모든 Layer에서 공유됨
•
Block 끝까지 돌고나면 Target Item Embedding과 Inner Product한 걸 Relavance Score로 사용함
•
당연히 Ground-Truth와의 Inner Product값이 극대화 하도록 모델이 학습됨
•
Loss로는 Activation Function으로 태우고 Negative Sample과 BCE 발생시킴
•
User Embedding을 Prediction 전에 더해서 넣어줄 수도 있지만, 경험상 성능향상은 없었음
Experiments
4가지 질문에 답하면서 SASRec의 효용을 증명함
1.
SASRec이 CNN,RNN Based SOTA Model보다 강력한 성능을 보이는가? (Yes)
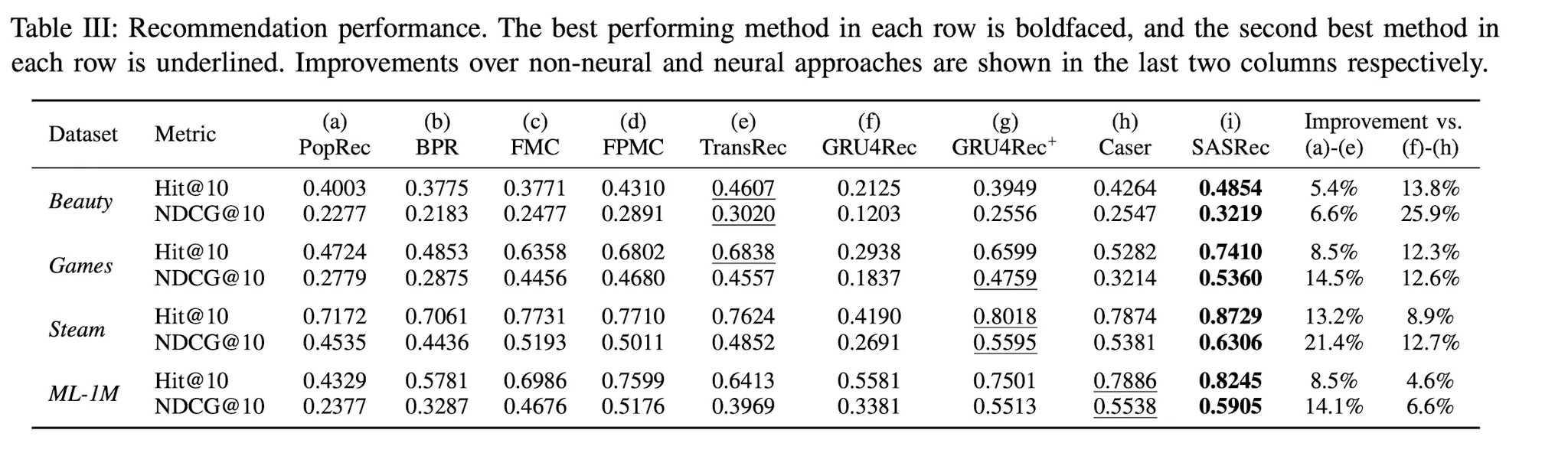
2.
SASRec의 어떤 Component가 가장 중요한가? (Shared IE, Transfmrer Block)
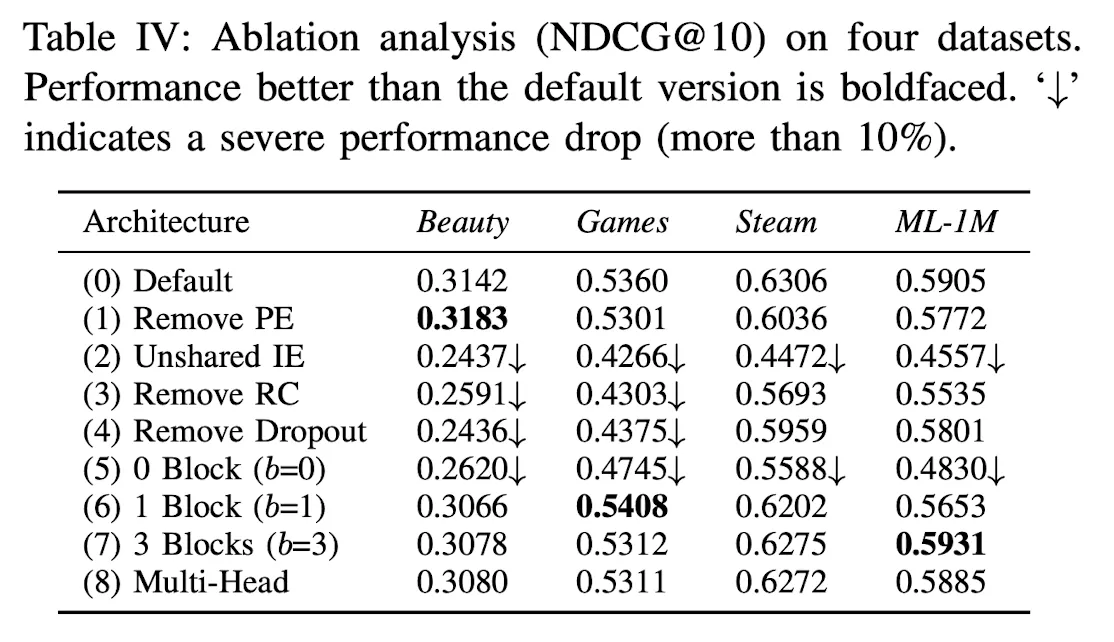
3.
Sequence Length에 따른 SASRec의 효율과 확장성은 어떤가?
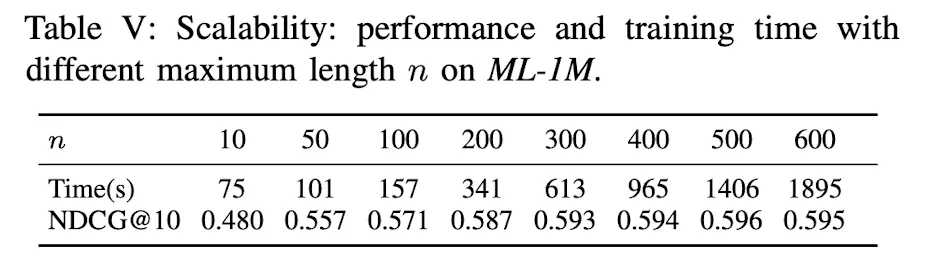
4.
Attention Weight가 Attribute나 Position에 따른 패턴을 학습할 수 있는가?
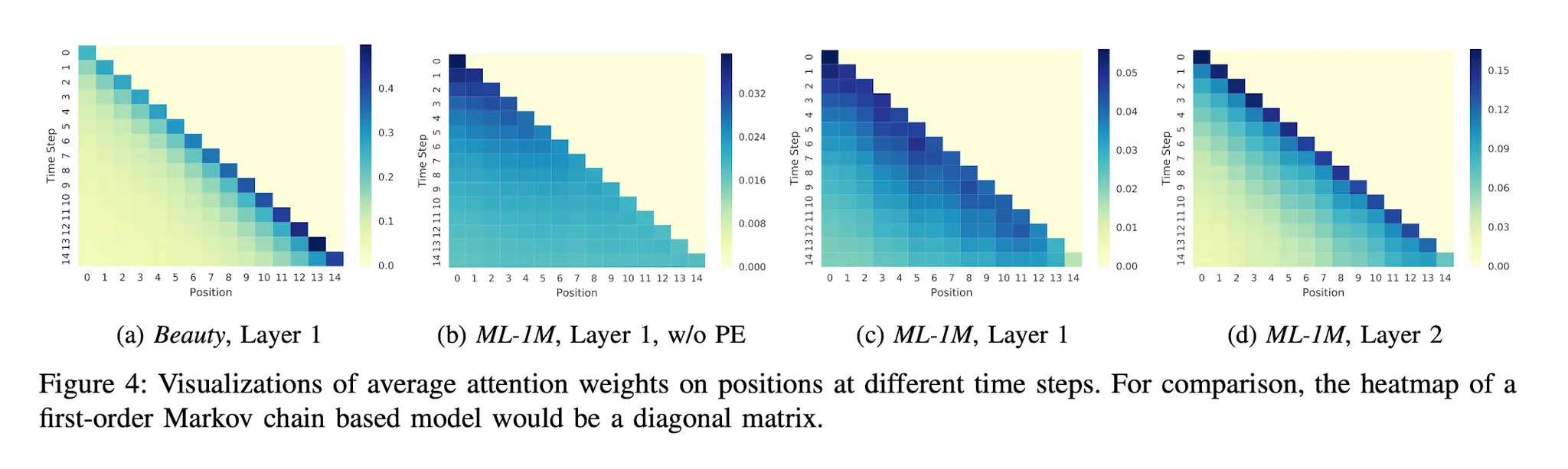
(a) : Sparse
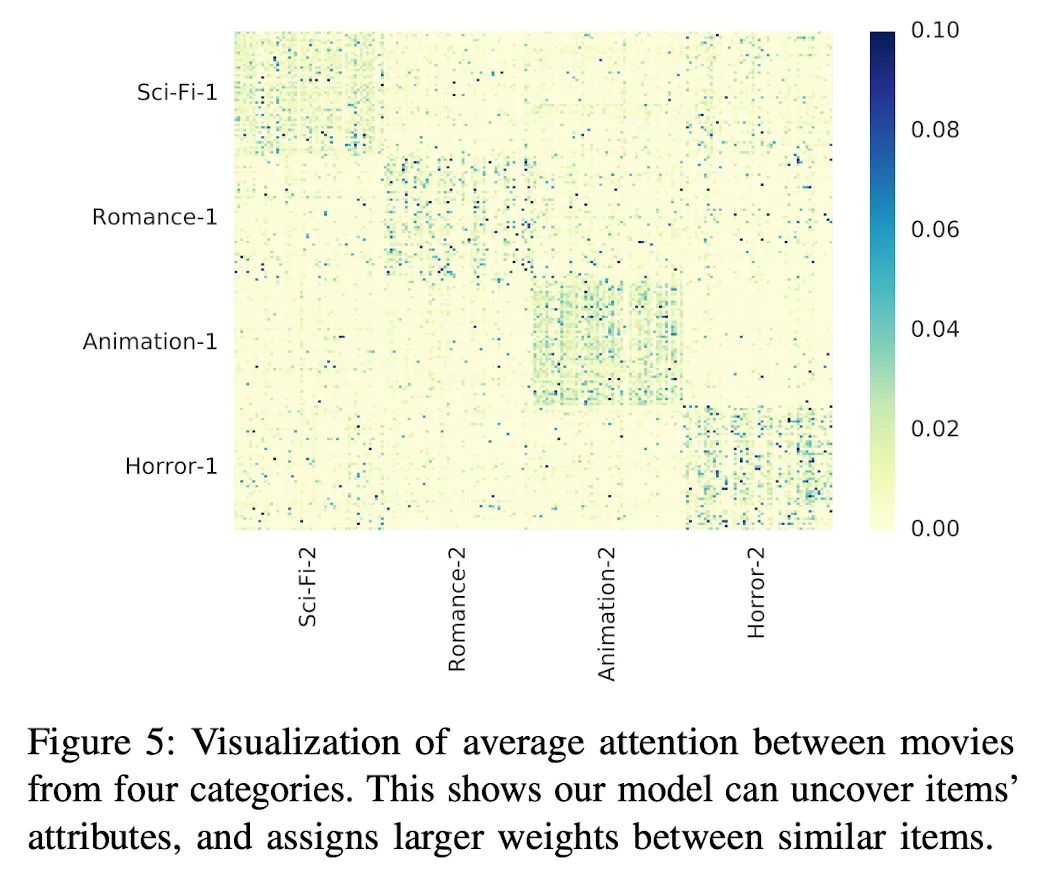
Conclusion
•
SASRec은 Trasnformer Based Next Item Recommendation의 시초이다.
•
당시 CNN/RNN 기반 알고리즘보다 강력하고 빠른 성능을 보여주었다 (RNN은 안되는 병렬가능)