



문제 정의 : 한국어 음성에서 비속어 검출
사용 데이터 : 유튜브 1인 미디어 컨텐츠 크롤링
사용 기술 : Python, Keras, Librosa
사용 방법론 : Mel-Spectrogram , 1D CNN + GRU
Python
복사

맡은 역할 : 프로젝트 기획, 데이터 Labelling, 모델링 일부

빅데이터 연합동아리 투빅스에서 제 9회 컨퍼런스의 일환으로 진행된 프로젝트입니다.
개요
시대적 배경 :
1인 미디어의 영향력이 더욱 더 커지고 있는 상황에서 비속어에 대한 규제는 미비했습니다.
어린 아이들도 이런 미디어에 쉽게 노출되어 있는데 이는 큰 문제라고 생각했습니다.
기술적 배경 :
한국어 비속어 음성에 대한 프로젝트 는 없었습니다.
이런 배경을 바탕으로, 한국어 비속어 음성을 잡아내는 프로젝트를 시작했습니다.
목표
1. 한국어 유튜브 동영상의 음성에서 비속어 부분을 찾아내자
2. 그 부분을 묵음(삐처리)하자
Python
복사
주요 아이디어
데이터
쉽게 접할 수 있는 1인 방송 유튜브 영상들을 크롤링
이후 Labeling의 편의를 위해 문장단위로 영상들을 분할(VoyagerX의 Vrew 사용)
그 문장 안에서 단어단위로 Labeling을 진행
Class = {
'0' : 'Negative', #일상어
'1' : 'Activate', #비속어
'9' : 'Background' #말이 아닌 배경음 (원본 - Activate - Negative)
}
Python
복사
전처리
데이터 생성(Overlay)
배경 :
1.
개별 Data 간 Length 차이가 너무 많이남
2.
클래스 불균형 문제가 존재함
방법 :
1.
Background를 이어 붙여 10초 길이의 배경음 생성 ( Lenght 통일 )
2.
그 위에 Negative, Activate 를 랜덤하게 덮어 씌움 ( 불균형 문제 해결 )
3.
1이 끝나는 시점부터 일정 시간동안 Label 1 부여 ( Sequential )
음량 조절
배경 :
Activate의 음량이 전반적으로 큰 편이라, 큰 소리면 1로 찍는 경향 발견
방법 :
Negative,Activate를 덮어 씌울 때, 랜덤하게 음량을 줄이거나 늘림 + 정규화
특성 추출
배경 :
일반적인 음성 파형을 바로 사용하는 것 보다, Mel-Scale인 Spectrogram의 정보량이 더 많음
방법 :
Librosa를 이용해, 파라미터를 조정해 가며 Mel-Spectrogram을 추출해 입력으로 사용
모델링
•
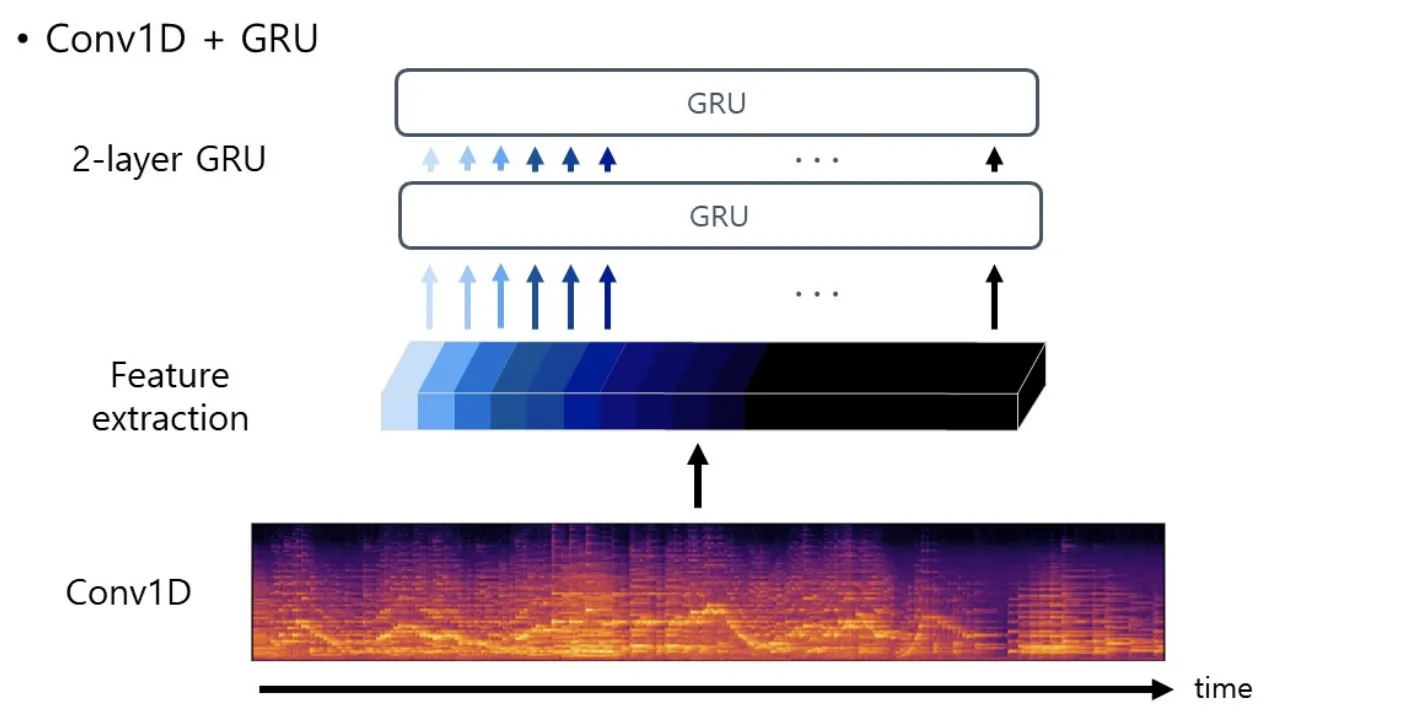
구조(Architecture)
Conv1D : 음성 자체의 Sequential 함을 살리면서, Spectrogram의 적절한 특징 추출
GRU : 2계층의 RNN을 사용해, 여러 관점으로 특징 추출 유도, 각 Time 마다의 값으로 욕설 판별
•
기타
Dropout & BN : 일반적으론 둘 중 하나(특히BN)을 사용하지만
둘 다 사용할 때의 성능이 더 높았습니다.
•
성능
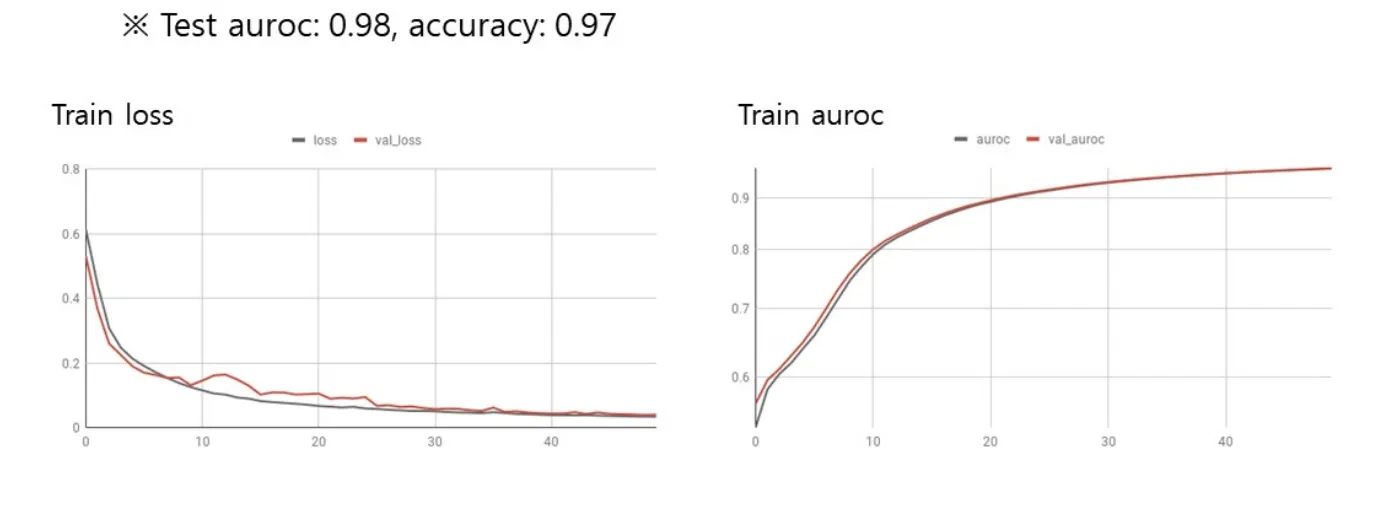
결과
자료
데모 영상