

Background
CTR
Order of Feature Interaction
Abstract
DeepFM은 CTR을 예측하는 추천시스템 모델이다. DeepFM 이전 추천시스템들은 도메인 전문적인 Feature Engineering을 필요로 하거나, 여러 Order의 Feature Interaction을 고려하지 못한다는 단점이 있었다. 이런 문제를 해결하기 위해, DeepFM은 Raw Feature로 부터 NeuralNet을 이용해 모든 단계의 상호작용을 End to End로 Capture한다.
Introduction
Feature Interaction
유저의 행동 뒤에는 다양한 Feature의 상호작용이 숨어있다. 예를 들어 식사 시간대에 배달 어플 클릭률이 급증한다면 시간과 어플리케이션 카테고리의 상호작용이 행동에 영향을 끼친것이고, 10대 남자의 슈팅게임 클릭률이 높다면 연령대, 성별, 카테고리의 상호작용이 행동에 영향을 끼친것이라고 볼 수 있다. 이런 관점에서 보았을 때 유저의 행동을 예측하는 모델은 만든다는 것은 결국 Feature Interaction을 잘 Capture하는 모델을 만든다고도 볼 수도 있다.
하지만 Feature Interaction을 찾아내기란 쉽지 않다. 위의 예시처럼 직관적으로 떠오르는 상호작용도 있지만, 현실세계는 이보다 훨씬 복잡해서 사람이 떠올리기 힘든 Feature Interaction이 훨씬 많다.(기저귀와 맥주가 유명한 예시이다.) 이런 Interaction은 ML을 이용해서 자동으로 Capture하는 방법밖에 없다. 특히 Feature의 갯수가 많아질수록 수작업으로 효과적인 Feature Engineering을 하는건 불가능에 가깝다.
CTR Models
DeepFM 이전에도 CTR을 예측하려는 다양한 ML 모델들이 있었다. 가장 직관적인 Linear Model은 초기에 많이 사용되었으나 Feture Interaction을 손수 넣어 주어야 하는 문제가 있어, 일반화와 확장이 어렵다. Factorization Machine(FM)은 Feature Interaction을 내적으로 모델링 해서 좋은 결과를 얻어낸 모델이다. 이론적으로 High-Order Interaction까지 모델링 할 수 있지만, 복잡도 때문에 현실적으로는 Order-2 Interaction 까지만 모델링 한다는 한계가있다.
NeuralNet을 이용해 Feature Representation을 학습시키려는 시도도 있었다. 구체적인 방법으로는 FM의 표현능력을 늘리기 위해 FM 형태로 Pre-Train한뒤 NeuralNet으로 이어서 학습시키는 등의 방법들이 있었는데, 낮은 Order의 Interaction을 잘 고려하지 못한다는 단점이 있었다. 이런 문제를 해결하기 위해 구글이 Linear 모델과 Deep 모델을 섞은 Wide & Deep 방법론을 제시했지만, Wide(Linear) Part에서 Feature Engineering이 필요하다는 한계를 극복하지는 못했다.
살펴보았듯, 선행 연구들은 전부 Low or High Order만 고려하거나, Feature Engineering에 의존한다는 한계가 있다.
DeepFM
DeepFM은 FM과 NeuralNet을 결합한 새로운 모델이다. Low-Order Interaction은 FM을 이용해 모델링 하고, High Order는 DNN을 통해 모델링한다. Wide&Deep 모델과 다르게, Feature Engineering 없이 End-to-End로 표현을 학습하며, 단계간 Embedding Vector를 공유해 효율적으로 학습한다. 즉 모든 단계의 Order를 고려하며, Feature Engineering이 필요하지 않은 CTR 모델이다. 이러한 개선을 바탕으로 CTR Prediction Task에서 기존 모델들 보다 뛰어난 Metric을 보였다.
DeepFM Approach
Notation
설명을 위해 Notation을 먼저 정의하고 간다. Dataset이 개의 인스턴스를 갖고 있으면 는 개의 Feature를 가지고 있으며, 는 클릭할 확률을 의미한다. 는 Categorical, Continous Feature 모두를 포함하며, 각각의 Instance는 차원의 와 의 집합으로 표현 가능하다. 일반적으로 는 고차원의, Sparse한 벡터이다.
DeepFM

DeepFM은 Low, High Order Interaction을 모두 고려하기 위해 FM과 Deep 두 종류의 Component를 사용한다. 두 Component는 같은 입력을 공유한다. Feature 에 대하여, Scalar 는 Feature의 중요도를 나타내는 가중치로 작용하며 Latent Vector 는 다른 Feature와의 Interaction의 중요도를 나타내기 위해 사용된다.
가 FM 로 입력되면 Order-2 Feature Interaction을 모델링하고, Deep 으로 입력되면 High Interaction을 모델링한다. FM의 Output과 Deep의 Output을 합한뒤 Sigmoid를 거친값을 로 사용한다.
FM Component
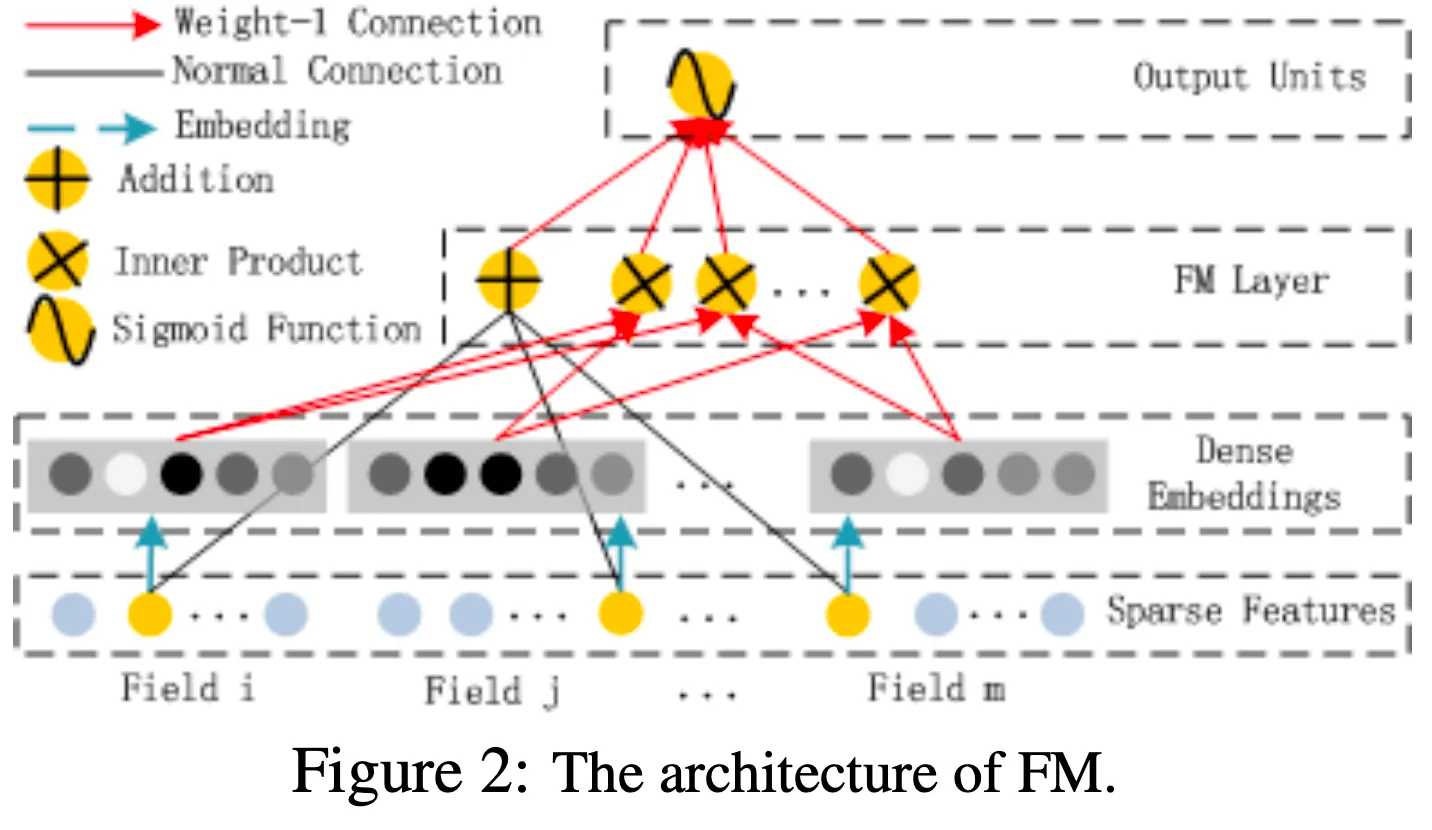
FM은 2010년에 제시된 방법론으로, Feature Interaction을 Latent Vector의 내적으로 표현한 일종의 Polynomial Regression이다. Polynomial Regression으로 Feature Interaction을 모델링 하면, Feature와 Weight의 갯수가 기하급수적으로 증가하는데, FM은 Feature Interaction을 간의 내적으로 바꾸어 효과적으로 모델링한 방법론이다. 각각의 Feature가 등장할 때 마다 가 Train 되므로, Train-set에 거의 등장하지 않던 Interaction이라도 어느정도 모델링 할 수 있다.
FM Component는 FM을 사용해 Order-2 Interaction까지 모델링한다. 수식은 다음과 같다.
(는 Feature의 갯수)
Deep Component
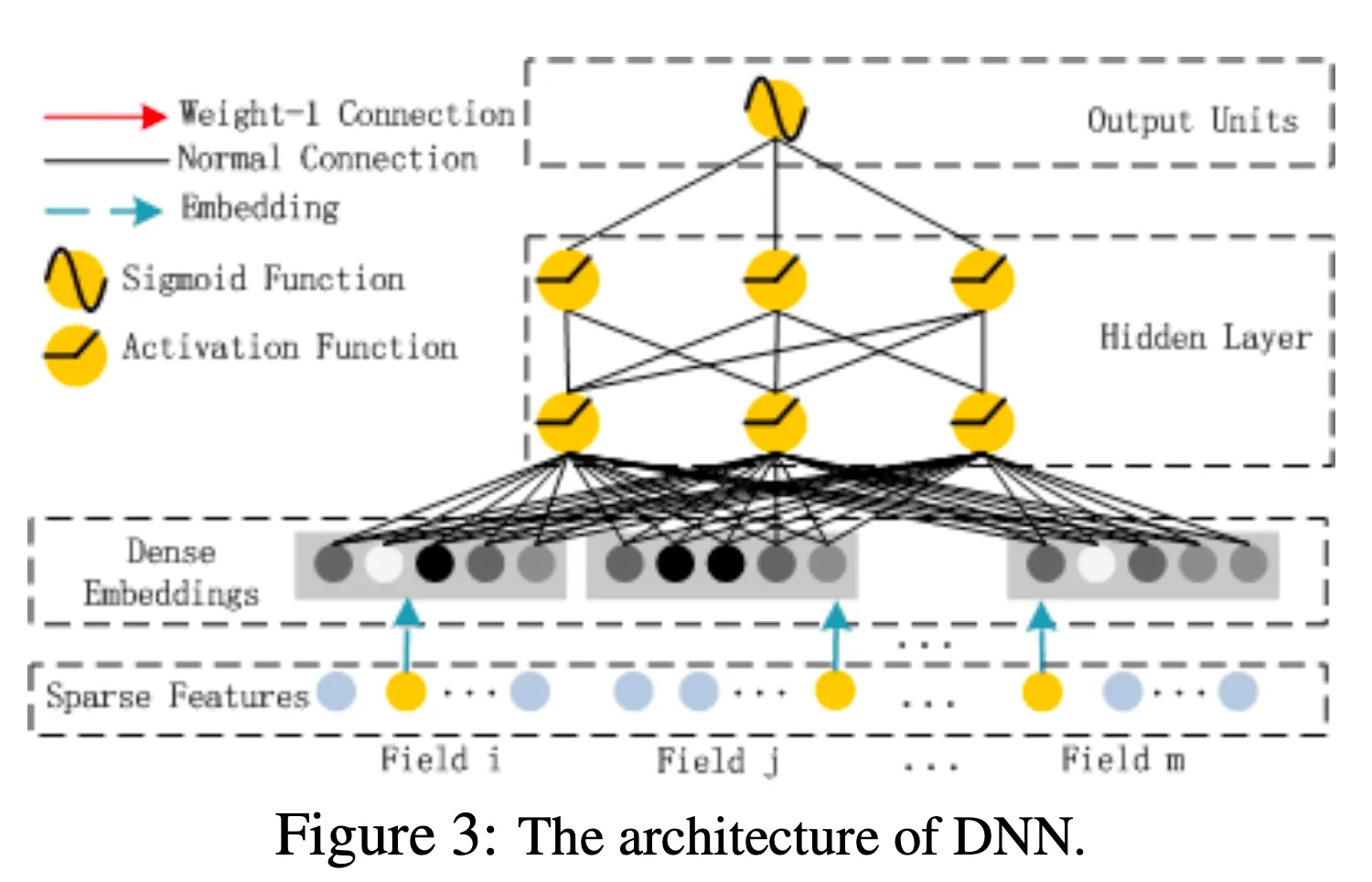
Deep Component는 FFN(Feed-Forward NeuralNet)으로 이루어져 있으며 High-Order Interaction을 모델링한다. Sparse한 Categorical Feature들을 Field별로 묶어서 Embedding하는데, Field 원소 갯수에 상관없이 차원으로 뿌려준다. 이는 FM Component에서 사용한 를 사용하기 위함인데, Embedding Vector로서 를 사용한다.
즉 FM Component의 변환과 Deep Component의 Embedding이 동일한 가중치로, 동일한 방식으로 이루어진다. 이렇게 를 양쪽에서 학습시킴으로서 Raw Feature에서 High, Low Interaction을 둘 다 모델링 할 수 있게되고, Feature Engineering을 할 필요가 없어진다.
Embedding Layer의 Output을 수식으로 나타내면 아래와 같다.
는 를 통해 Embedding 된 번째 Field를 의미하고, 은 Field 갯수이다. 이렇게 구해진 가 N-Layer FFN로 입력된다. 마지막 Layer의 결과값을 으로 사용한다.
Experiment
Experiment Table
DeepFM의 효용을 입증하기 위해 당시 SOTA 모델들과 비교하는 실험을 했다. BenchMark(Criteo) Dataset와 실제 현업(Company) Dataset에 대해 AUC와 Logloss를 비교했다. 공정한 비교를 위해 Hyper-Parameter는 통일했다.
•
Dropout : 0.5
•
Hidden Dimension : [400,400,400]
•
Optimizer : Adam
•
Activation : Relu
•
Latent Dimension(FM) : 10

Insights
•
Interaction을 고려하지 않는 LR이 성능이 가장 낮은것으로 보아, Feature Interaction을 모델링 하는것이
•
DeepFM이 FM(Lower), *NN(Higher) 모델보다 성능이 높은걸로 보아, High-Low Interaction을 동시에 고려하는것이 CTR Prediction 성능을 향상시킨다.
•
DeepFM이 Wide & Deep (LR & DNN, FM & DNN) 모델보다 성능이 높은걸로 보아, High-Low Interaction을 배우는 Weight를 공유하는 것이 CTR Prediction 성능을 향상시킨다.
Conclusion
DeepFM은 SOTA Model들의 단점을 분석하고 FM과 FFN을 적절히 섞어 성능향상을 이루어냈다. 핵심은 두 Component를 결합해 학습시킨다는 것인데, 이것 덕분에 Pretrain과 Feature Engineering이 필요하지 않고 High-Low Interaction을 동시에 고려할 수 있다.