

Abstract
Motivation
1.
Vision Task는 오랜시간 CNN이 지배했다. 그런데 최근엔 ViT가 특정 상황에서 더 나은 성능을 보인다.
2.
ViT는 Self-Attetion의 Quadratic한 Runtime 증가 때문에, Patch Embedding을 이용한다.
3.
이 지점에서 저자는 의문을 가진다. “ViT의 강력함은 Transformer 때문일까? Patch 때문일까?”
4.
그리고 후자쪽에 힘을 실어주는 증거를 ConvMixer를 통해 제시한다.
ConvMixer
1.
ConvMixer는 매우 단순한 모델로 MLP-Mixer와 유사한 구조를 가지고 있다.
2.
ConvMixer는 MLP-Mixer와 다르게 Standard Conv만 사용해 Mixing을 수행한다.
3.
간단하지만, ResNet같은 Classic 뿐만 아니라 ViT, MLP-Mixer와 동일조건에서 우위를 보여준다.
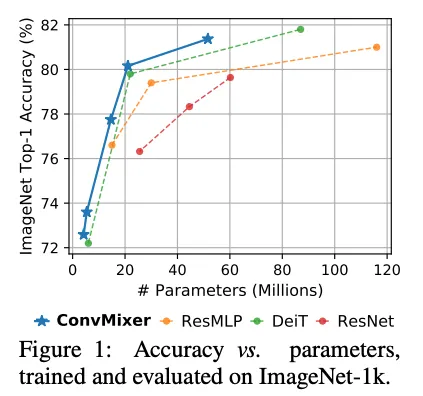
Introduction
Deep-Learning Architecture in CV
1.
CV Task에선 CNNs가 지배적이었으나, ViTs가 데이터셋이 커질수록 더 강력한 모습을 보인다.
2.
최근 연구 동향으로 봤을땐, NLP처럼 CV도 Transformer가 지배적인 위치를 갖는건 시간문제로 보인다.
Patch Representation
1.
Self-Attention의 Cost때문에, ViT는 이미지를 Patch로 분할해서 모델링한다.
2.
ConvMixer는 ViT의 강력한 성능이 Transformer보다 Patch 에서 오는게 아닌가 의심한다.
ConvMixer
1.
ConvMIxer는 MLP Mixer처럼 Patch단위 연산을 하고, Channel Mix와 Spatial Mix를 분리한다.
2.
다른점은 그 연산을 Standard Convolution으로만 수행한다는 것이다.
3.
간단한 구조임에도 ResNets나 ViT, Mixer 시리즈 대비 동일 조건에서 우위 성능을 보인다.
4.
게다가 현재 구조는 성능이나 속도를 최적화한게 아닌 비교만을 위한 것이기때문에 발전의 여지가 많다.
5.
연구가 더 깊게 이루어지면, Convolution + Patch Based가 강력한 Baseline으로 자리잡을것 같다.
Conclusion
ConvMIxer는 MLP-Mixer에서 영감을 받아 Convolution으로 연산을 대체한 모델이다. 그리고 성능이나 속도에 대한 고려가 없었음에도, 베이스라인으로 쓰이는 Vision Model들과 경쟁할만한 성능을 보인다. ConvMixer를 통해 간단한 Patch Embedding이 딥러닝에서 강력한 Stem임을 보였다.
Patch Embedding은 한번에 다운 샘플링을 수행하고, Resolution을 줄여 Effective Receptive field size를 갖게한다. 따라서 Global한 정보를 더 잘 혼합할 수 있다. Attention 뿐만아니라 Patch Embedding도 중요한 Feature다.
또한 더 깊고 큰 Patch를 가진 ConvMixer가 이후엔 최적에 도달할 수 있을것이라고 전망하며, Patch Embedding 의 효과를 제대로 확인하려면 Larger Scale Dataset에 대해 ViT, MLP-MIxer와 비교해 봐야 할 것이다.
Figures
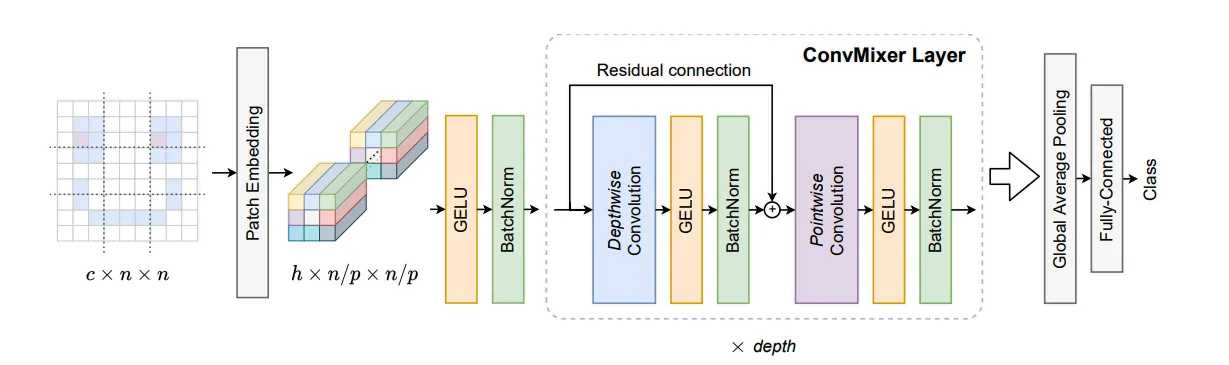
Summary
Simple Model
위의 Figure와 같이, ViT와 유사한 구조이다. Patch Embedding을 Conv를 통해 수행하고 그 이후는 Fully Conv Block으로 구성되어있다.
Desing Parameters
1.
4개의 하이퍼 파라미터가 있다. (1) hidden dim , (2) depth , (3) Patch size , (4) Kernel Size
2.
하이퍼 파라미터에 따라 ConvMixer- 로 네이밍 한다.
Motivation
1.
Spatial Mixing은 DepthWise로, Channel Mixing은 Point Wise로 치환한 구조이다.
2.
Pyramid-Shaped, Progressively Downsampling 같은 기존 구조와 차이를 갖는다.
Experiment
Training Setup
1.
ImageNet-1k를 추가 데이터나 Pre-Train없이 실험했다.
2.
RandAug, mixup, CutMix, random erasing, Gradient Norm Cliping을 timm에 더해 이용했다.
3.
AdamW로 Triangular Lr Schedule을 이용했으며, 하이퍼파라미터 튜닝을 하지 않았다.
Results
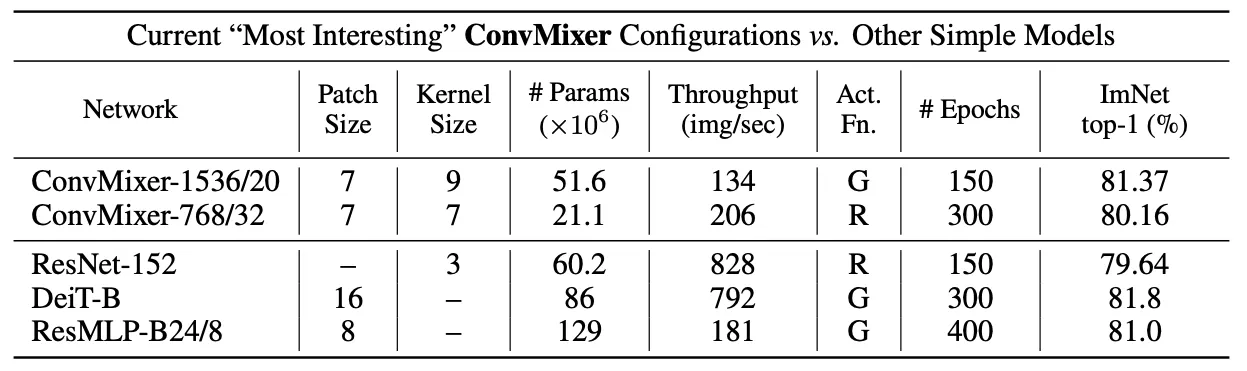
1.
Wider ConvMixer가 수렴은 빨리하는데 Memory, Computation이 많이 필요하다.
2.
ConvMixer가 깊어질수록 Larger Patch가 필요하다.
3.
모든 조건이 같을때 Patch Size를 7→14로 2배 키웠더니 정확도가 2.5%p 떨어졌지만 4배 빨라졌다.
4.
Gelu가 꼭 필요하진 않았다.
5.
Comparision들 대비 적은 파라미터와 에폭이 필요하지만, Inference는 작은 Patch 때문에 느리다.
6.
하이퍼파라미터 튜닝으로 어느정도 해결이 가능하다.
자세한 성능 비교 표
다음 질문에 답해보세요.
What did the author(s) try to accomplish?
ViT의 강력함이 Transformer에서 오는게 아니라 Patch에서 오는 것일수도 있다.
What were the key elements of the approach?
MLP-Mixer의 개념을 계승해 Channel-Mix, Spatial-Mix을 Fully-Conv로 대체했으며
실제로 유의미한 성능을 얻었다.
What can you use yourself?
-
What other references do you want to follow?
-