

Abstract
GAT는 기존 Graph Convolution의 한계를 Attention으로 극복한 Paper다. Attention을 통해 이웃 Node별로 Message Passing 가중치를 결정하기 때문에, 사전 작업이 필요없다.(Ex: RandomWalk) 효율적으로 작업을 줄이면서, Transductive, Inductive BenchMark 양쪽에서 GCn, GraphSAGE를 압도하는 성능을 보였다.
Comparision to Related Work
Attention
Attention을 이용했으므로, 기존 방법론 대비 더 큰 Capacity를 갖고있다. 게다가 Attention Score를 통해 Node간의 영향력을 관측할 수 있는 이점이 있다.
Independent on Global Graph Structure
GraphSAGE의 Sampling, PinSAGE의 RandomWalk와 같은 사전작업이 필요없다.
Elegant Aggregation
GraphSAGE의 경우 Fixed-Size의 Random Sample된 이웃을 사용하는데, 이러면 전체 이웃에 대한 정보를 가져올 수 없다. 게다가 성능을 위해 Permute Invariant한 Neighbor에서 LSTM Aggregate Function을 사용한 부분이 비직관적인데, Attention을 이용하면 이러한 부분이 모두 해결된다. (Positional Encoding이 없는 Self-Attention은 Permute Invariant하다)
GAT
Single Graph Attention Layer
개의 이웃 중 에 대해 Attention을 수행한다고 가정하고 수식을 설명한다. 우선 이웃 Feature 벡터 에 대해 를 곱하고 를 곱한다. 이렇게 구해진 값에 대해 이웃전체에 대해 Summation을 수행한뒤 Activation에 넘긴다. 이때 는 Attention Score 를 Softmax한 결과값인데, 기준 다음과 같이 구해진다.
풀어서 설명하면
1.
이웃과 자신의 Feature에 를 곱하고 Concat한다
2.
Concat된 Embedding에 를 곱하고 LeakeyReLU를 통과시킨다.
3.
LeakeyReLU 결과값을 이웃별로 Softmax한게 Attention Score가 된다.
4.
Attention Score만큼 1번에서 구했던 이웃 Vector를 가지고와서 Summation한다.
Multi Head Graph Attention
위에서 수행된 Single Graph Attention을 Head를 나눠 진행한다. Multi Head Attention이 추가된 수식은 다음과 같다. 이때 는 Head 숫자이며 는 Concat의 Notation이다.
Experiment
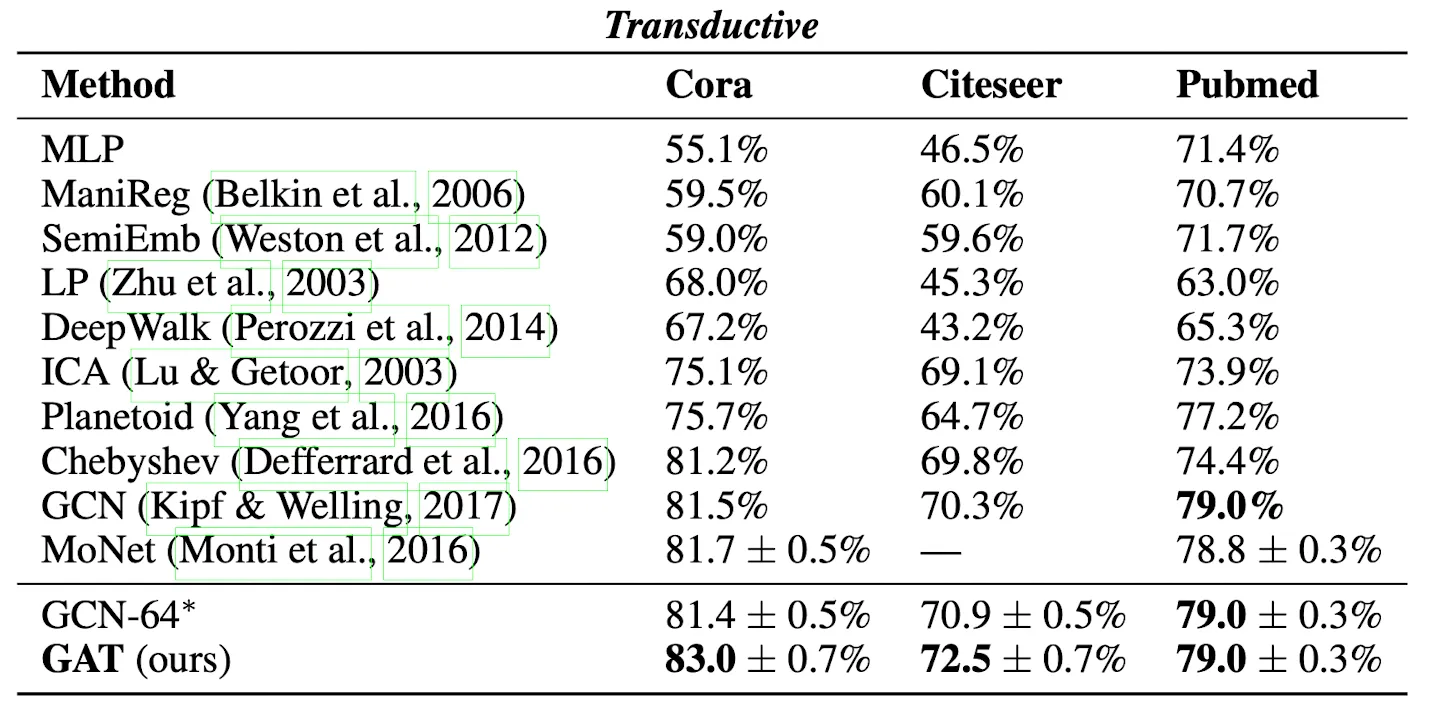
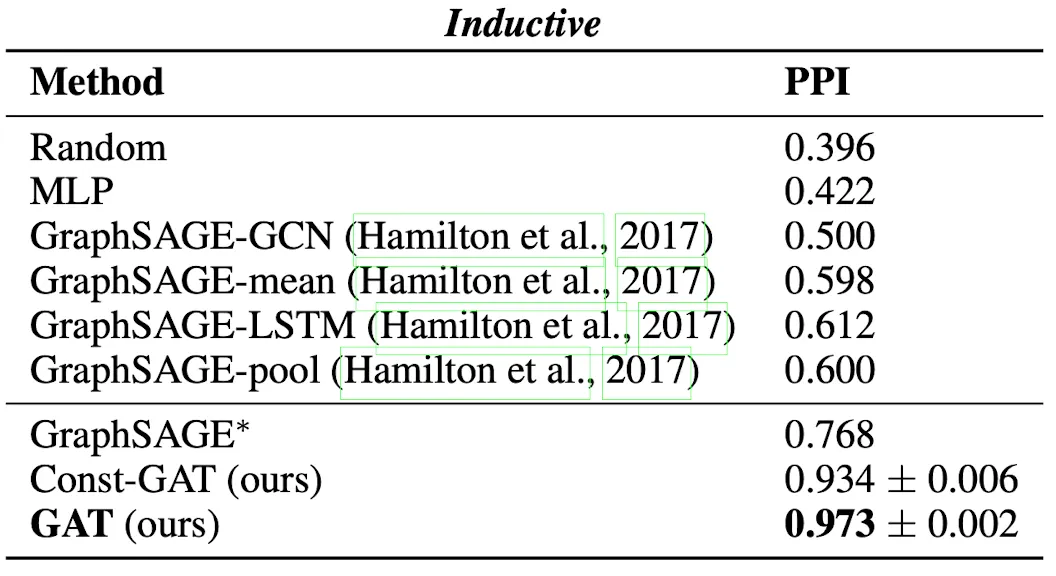
GAT를 GCN모듈로 사용해 당시 Transductive, Inductive BenchMark를 수행한 Figure이다. 당시 Transductive에서 많이 사용되던 GCN을 뛰어넘었고, 단백질 구조 예측 Task(Hard Inductive)에서는 GraphSAGE를 압도적으로 이기는 모습을 보여준다.
특히 Const-GAT는 모든 Attention Score를 1로 박아둔 구조인데, GraphSAGE의 Fixed-Length Neighborhood Uniform Sampling이 안좋은 선택지라는 점을 극적으로 보여준다.
Conclusion
GAT는 Attention을 이용해 Model Capacity를 늘렸으며, Random Walk와 같은 사전 작업들로 부터 자유로운 GCN Layer다. 이를 통해 GraphSAGE, GCN보다 뛰어난 성능을 보여주었으며, Attention 연산은 Head, Neighbor별로 병렬 연산이 가능해 효율적이다. 추가로 XAI, Graph Level Task, Edge Feature등을 Future Work로 제시하였다.