



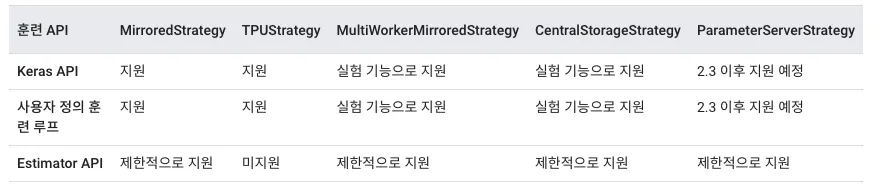
tf.distribute.Strategy
개요
•
Train을 여러 장비(GPU, TPU, Server)에 나누어 하기위한 API
•
keras, estimator, custom loop 모두에서 사용 가능
방식
•
데이터를 병렬 처리하는 방법은 크게 두 가지가 있다.
•
Synchronous:
◦
모든 worker가 데이터를 나눠갖고 동시에 훈련하며, Step별로 Gradient를 합산한다.
◦
All-Reduce 방식으로 구현한다.
•
Asynchronous training:
◦
모든 worker가 독립적으로 데이터를 사용하고, 비동기적으로 변수를 업데이트한다.
◦
ParameterServer 방식으로 구현한다.
•
이 외에도 하드웨어 플랫폼(GPU, Server, Cloud, TPU)에 따른 다양한 Strategy API가 존재한다.
MirroredStrategy
개요
•
장비 하나에서의 다중 GPU를 이용한 Synchronous 분산 훈련
•
각 GPU마다 모델의 모든 Variable이 미러링되며(MirroredVariable), 모두 같은 값을 유지한다.
•
All-Reduce 알고리즘은 기본적으로 NVIDIA NCCL으로 구현되어있으며, 선택하거나 구현할 수도 있다.
예시
mirrored_strategy = tf.distribute.MirroredStrategy()
# TF가 인식한 모든 GPU를 쓰는게 디폴트이다. 일부만 사용하고 싶다면 지정해 주면 된다.
mirrored_strategy = tf.distribute.MirroredStrategy(devices=["/gpu:0", "/gpu:1"])
# 장치간 통신 방법은 cross_devices_ops 인자를 이용하면 된다.
# tf.distribute.CrossDeviceOps Instance를 전달하면 된다.
mirrored_strategy = tf.distribute.MirroredStrategy(
cross_device_ops=tf.distribute.HierarchicalCopyAllReduce())
Python
복사
TPUStrategy
개요
•
TPU를 이용한 분산 훈련 ,MirroredStrategy와 같다.
•
대신 효율적인 All-reduce 알고리즘과 Multiple TPU Core에 대한 동작이 구현되어있다.
예시
cluster_resolver = tf.distribute.cluster_resolver.TPUClusterResolver(
tpu=tpu_address)
tf.config.experimental_connect_to_host(cluster_resolver.master())
tf.tpu.experimental.initialize_tpu_system(cluster_resolver)
tpu_strategy = tf.distribute.experimental.TPUStrategy(cluster_resolver)
Python
복사
MultiWorkerMirroredStrategy
개요
•
MirroredStrategy 와 매우 유사하다. 즉 모든 Device에 모든 Variable을 복사한다.
•
Mutiple GPU를 갖고있는 Multiple Worker간의 Synchronous 분산 훈련을 지원한다.
•
Cross-Device 통신을 위해 2가지 구현이 있다.
◦
RING : CPU, GPU를 지원하는 RPC-Based 방식
◦
NCCL : NCCL을 이용하며 GPU에선 SOTA급 성능을 보이는 방식(CPU 지원 X)
◦
AUTO : Tensorflow가 알아서 고르게 두는 방식
예시
strategy = tf.distribute.MultiWorkerMirroredStrategy()
# 통신 방식 설정
communication_options = tf.distribute.experimental.CommunicationOptions(
implementation=tf.distribute.experimental.CommunicationImplementation.NCCL)
strategy = tf.distribute.MultiWorkerMirroredStrategy(
communication_options=communication_options)
Python
복사
ParameterServerStrategy
개요
•
여러 Machine에 걸친 훈련을 Scale-Up할 때 사용하는 일반적인 Data-Parellel 방법
•
이때 Clusters는 Worker들과 Parameter Server들로 구성된다.
•
Variable들은 Parameter Server들에서 생성되고, Worker들은 이를 읽고 업데이트한다.
coordinator-Based
•
TF2에선 tf.distribute.experimental.coordinator.ClusterCoordinator를 이용한다.
•
이 방법에선 Worker와 Parameter서버가 tf.distribute.Server 를 실행시킨다.
•
tf.distribute.Server 는 Coordinator로 부터 Task를 전달받는다.
•
Coordinator는 Resources를 만들고, Task를 전달하고, Checkpoint를 작성하고, Failure를 처리한다.
•
Coordinator에서 실행되는 프로그램에선
◦
ParameterServerStrategy 객체를 이용해 TrainStep을 정의하고
◦
ClusterCoordinator 를 이용해 Remote Worker로 Task를 전달한다.
strategy = tf.distribute.experimental.ParameterServerStrategy(
tf.distribute.cluster_resolver.TFConfigClusterResolver(),
variable_partitioner=variable_partitioner)
coordinator = tf.distribute.experimental.coordinator.ClusterCoordinator(
strategy)
Plain Text
복사
CentralStorageStrategy
개요
•
변수를 미러링하지 않고, CPU에서 관리하는 Synchronous 분산 훈련 방식
•
작업은 Local GPU로 복제되며, GPU가 하나밖에 없다면 변수와 작업모두 그 GPU로 배치
예시
central_storage_strategy = tf.distribute.experimental.CentralStorageStrategy()
Python
복사
tf.distribute.Strategy with keras
방법
1.
적절한 tf.distribute.Strategy 인스턴스를 만들고
2.
strategy.scope 안에서 keras Model 설정과 컴파일을 한다.
예시
mirrored_strategy = tf.distribute.MirroredStrategy()
with mirrored_strategy.scope():
model = tf.keras.Sequential([tf.keras.layers.Dense(1, input_shape=(1,))])
model.compile(loss='mse', optimizer='sgd')
Python
복사
•
scope안에서 Model을 선언하고 compile하면 Distributed Variable을 만든다.
•
이렇게 설정하고나면 이후 fit은 기존과 같다.
디테일
•
Distributed Learning을 하면, Batch의 갯수가 분산된 만큼 똑같이 나누어져 들어간다.
◦
만약 Batch size 10이고 GPU가 2개면 한 GPU당 Batch 5개를 나눠가진다.
◦
장비가 추가될수록 Batch size를 키우는것이 일반적이고, Learning Rate도 조정해야 할 수 있다.
# Compute a global batch size using a number of replicas.
BATCH_SIZE_PER_REPLICA = 5
global_batch_size = (BATCH_SIZE_PER_REPLICA *
mirrored_strategy.num_replicas_in_sync)
dataset = tf.data.Dataset.from_tensors(([1.], [1.])).repeat(100)
dataset = dataset.batch(global_batch_size)
LEARNING_RATES_BY_BATCH_SIZE = {5: 0.1, 10: 0.15}
learning_rate = LEARNING_RATES_BY_BATCH_SIZE[global_batch_size]
Python
복사
tf.distribute.Strategy with Custom Loop
방법
1.
적절한 tf.distribute.Strategy 인스턴스를 만들고
2.
strategy.scope안에서 Model과 Optimizer를 설정한다.
3.
Dataset을 strategy.experimental_distribute_dataset method를 이용해 분산시킨다.
4.
TrainStep을 정의해 GradientTape부터 Weight update까지 수행한다.
5.
starategy 인스턴스의 run method로 TrainStep과 Distributed Dataset을 전달한다.
6.
starategy 인스턴스의 reduce method를 이용해 Loss를 취합한다.
예시
loss_object = tf.keras.losses.BinaryCrossentropy(
from_logits=True,
reduction=tf.keras.losses.Reduction.NONE)
def compute_loss(labels, predictions):
per_example_loss = loss_object(labels, predictions)
return tf.nn.compute_average_loss(per_example_loss, global_batch_size=global_batch_size)
def train_step(inputs):
features, labels = inputs
with tf.GradientTape() as tape:
predictions = model(features, training=True)
loss = compute_loss(labels, predictions)
gradients = tape.gradient(loss, model.trainable_variables)
optimizer.apply_gradients(zip(gradients, model.trainable_variables))
return loss
@tf.function
def distributed_train_step(dist_inputs):
per_replica_losses = mirrored_strategy.run(train_step, args=(dist_inputs,))
return mirrored_strategy.reduce(tf.distribute.ReduceOp.SUM, per_replica_losses,axis=None)
Python
복사
디테일
위의 예시를 기반으로 주목해야할 점을 소개하면
1.
Loss는 나중에 Sum되기 때문에, Global Batch size로 나눠주어야 한다.
2.
mirrored_strategy.reduce 는 mirrored_strategy.run 의 결과를 취합한다
3.
mirrored_strategy.run 의 결과는 각 Local Replica로부터 얻어진다.
4.
mirrored_strategy.experimental_local_results 를 통해 결과물의 List를 볼 수 있다.
5.
scope안에서 apply_gradient를 실행하면 동작이 수정된다. 특히 synchronous의 경우 모든 Replica의 Gradient를 합치고, 각자의 Parallel Instance에 적용된다.
상세 튜토리얼
Examples and tutorials
Here are some examples for using distribution strategies with custom training loops:
1.
2.
3.
4.
5.
TensorFlow Model Garden repository containing collections of state-of-the-art models implemented using various strategies.