

2021.08.24
(페이지로 열어서 봐주세요)
(블럭과 블럭 사이가 너무 멀면 창의 너비를 조절해주세요)
0. Abstract

What is METRO ?
•
METRO 는 단일 이미지로부터 3D Human Pose와 Mesh Vertex를 추출하기 위한 방법론입니다.
•
METRO 는 이름과 같이, Transformer의 Encoder 구조를 채용했습니다.
◦
Transformer 구조를 이용해 Vertex-Vertex, Vertex-Joint 간의 상호작용을 같이 모델링하고
◦
3D Joint와 Mesh Vertex를 동시에 Output으로 내보냅니다.
What is Novelty ?
•
METRO 는 SMPL과 같은 Parametric Model에 의존하지 않습니다.
◦
때문에 손과 같은 Domain으로도 쉽게 확장될 수 습니다.
•
METRO 는 Self-Attention을 이용합니다.
◦
Mesh Topology와 같은 Inductive Bias를 완화시키고,
◦
Vertex, Joint간의 Non-Local 관계를 자유롭게 학습시킬수 있습니다.
•
METRO 는 Masked Vertex Modeling을 사용합니다.
◦
Parital Occlusions 같은 상황에 Robust합니다.
1. Introduction
3D Human Pose & Mesh Reconsturcion Task
•
VR, 스포츠 동작 분석 등 다양한 Application에 이용가능해 많은 관심을 받고있는 Task이자,
•
관절 운동의 복합성과, Occlusion 문제 때문에 Challenging한 Task입니다.
Vertex Reconstruct Approches
Use Parametric Model
•
SMPL 과 같은 Parametric Model을 이용하는 방법입니다.
•
Shape()과 Pose() Coefficient를 예측하도록 학습됩니다.
•
장점 : Model에 Encode되어있는 강력한 Prior 덕에 Robust합니다.
•
단점 : Model을 구축할 때 사용된 제한된 Sample 때문에, Parameter Space가 한정되어있습니다.
Don't Use Parametric Model
•
Parametric Model의 한계를 극복하기 위한 방법입니다.
•
GCNN을 이용해 이웃한 Vertex-Vertex Interaction을 모델링하거나
•
1D Heatmap을 이용해 Vertex좌표를 Regressiong하는 방식입니다.
•
한계 : Nol-Local Interaction을 Modeling 하는데엔 비 효율적입니다.
Global Correlation in Vertices
•
손과 발 같은 Non-Local Vertices 사이에서도 강한 상관관계가 존재한다는 연구결과가 제시되어왔습니다.
•
따라서 저자들은 Vertices의 Global Correlation을 학습시키는 것이 Reconsturction 문제 해결에 도움이 되리라 믿고있습니다.
•
METRO에선 Transformer 구조를 이용해 간단하지만 효율적인 Global Interaction Modeling을 구현합니다.
METRO Description
[구조] : 점진적 차원축소를 진행하는 Multi-Layer Transformer Encoder 구조입니다.
[출력] : Joint와 Mesh Vertices를 동시에 Reconstruct 해 내보냅니다.
[트릭] : Masked Vertex Modeling을 이용해 Joint & Vertex 상호작용을 강화시킵니다.
•
METRO 는 Novel한 구조를 갖고있습니다.
1.
Transforemer Encoder를 이용해
2.
3D Pose와 Mesh를 같이 Reconsturct하는 첫 시도입니다.
•
METRO 는 Global Correlataion을 Modeling 합니다 (Fig 1)
1.
Joint, Vertex간 Short & Long Range Interaction을 찾아내고
2.
이를 통해 Occlusion이나, Variant Poses 문제를 완화합니다.
•
METRO 는 강력하고, 확장성도 높습니다.
1.
H3.6M, 3DPW Dataset에서 SOTA를 달성했습니다.
2.
3D Hand 처럼 다른 Domain에 대해서도 SOTA를 달성했습니다. (FreiHAND)

2. Related Works
Human Mesh Reconstruction (HMR)
[Background]
•
HMR 은 말 그대로 3D Human Body Shape을 Reconsturct하는 Task입니다.
•
초기 연구들은 Depth Sensor 등을 이용해 인상적인 성능을 달성했습니다.
•
이후엔, Monocular를 통한 HMR에 대한 연구가 진행되고 있으나
◦
Complex Pose Variants, Occlusions, 한정된 Dataset등이 발목을 잡고있습니다.
[Parametric Model]
•
사전 연구로는 Pre-Trained Parametric Model을 사용하는 연구가 있습니다. (SMPL, STAR, MANO)
•
Model의 Pose, Shape parmeter를 추정해 HMR을 수행합니다.
•
당연히 Image → Parameter 추정은 쉽지않은 Task 이므로 최근 연구는 다음과 같은 요소의 활용을 제안합니다.
1.
2.
Optimize 전략 연구
3.
Temporal Informatin 사용 (VIBE)
[Non-Parametric Model]
•
Parametric Model 없이 직접 HMR를 수행하는 연구또한 있습니다.
•
이 때, Human Body를 Repersentation 하는 방법으론 (3D Mesh, Volumetric Space,Occupancy Field)이 있습니다.
◦
이 연구들은 각자의 Target Application에 Representation이 한정되어있다는 한계가 있습니다.
[GCNNs Model]
•
Graph Convolution NeuralNet(GCNN)을 사용해 Vertex를 추정하는 연구도 있습니다.
•
•
그러나 GCNN은 사전 정의된 이웃 Vertex-Vertex Interaction을 모델링 하도록 설계되어있습니다.
◦
Long-Range Interaction을 모델링하기엔 비효율적이라는 한계가 있습니다.
[METRO]
•
Joint & Vertex의 Interaction을 모델링 할때 어떤 제한도 없으며
•
Self-Attention을 이용해 학습됩니다.
Attentions and Transformers
[Attention]
•
Attention 메커니즘은 다양한 NLP Task에서 성능 향상을 가지고 왔습니다.
•
Attention의 Key Insight는
1.
Output 예측에 큰 역할을 하는 관련 Input을
2.
Soft-Search해 Attention하는 방법을 배운다는 것입니다.
[Transformer]
•
Transformer는 Attention만을 사용해 만들어진 구조로
◦
고도의 병렬화된 Self-Attention을 이용해, 학습과 추론의 효율성을 끌어올렸습니다.
•
GPT, BERT와 같은 후속 연구를 통해 Scale에 맞는 강력한 Performance를 보임을 입증했습니다.
[Transformer in Vision]
•
NLP에서 큰 성공을 거둔 Transformer에 영감을 받아, Vision Task에 활용하려는 시도도 늘어나고 있습니다.
◦
Ex) ViT(Classification), DETR(Detection), Generation..
•
그러나 3D Human Reconsturction은 아직 제시된 방향이 없습니다.
•
METRO는 점진적 차원축소를 포함한 Multi-Layer-Transformer를 이용한 Joints, Vertices 추론을 방법을 제시합니다.
3. Method
METRO Architecture Introduction

1.
Image가 주어지면 CNN을 이용해 Feature Vector를 추출합니다.
2.
Template Joint와 Vertex를 Concat해 Positiong Encoding을 수행합니다.
3.
Joint, Vertex Query Set이 주어지면 병렬적으로 3D Coordinate Value를 Regression 합니다.
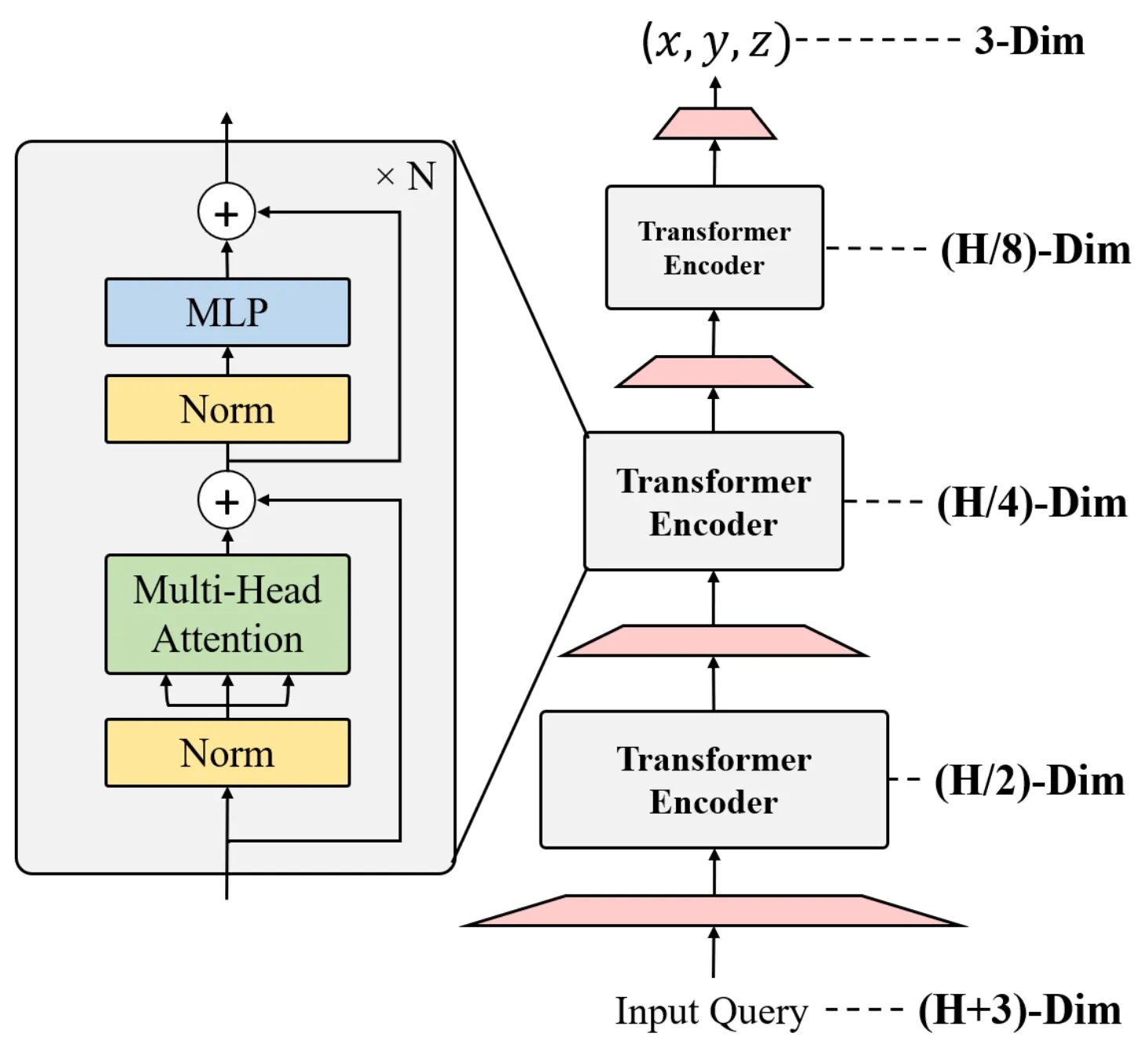
1.
각 Token은 Layer를 거치며 차원이 축소되어, 3D Coord에 도달합니니다.
2.
Encoder는 Progressive Dimensionality Reduction 구조를 사용합니다.
3.
각 Block은 4개의 Layer와 4개의 Head를 갖고있습니다.
Details of CNN
•
ImageNet Classification Pretrain CNN을 사용했습니다.
•
마지막 Hidden Layer로 부터 Feature Vector()를 얻습니다. (일반적으로 )
•
End-to-End Training이 가능하며, HRNet과 같은 Large-Scale CNN도 활용 가능합니다.
◦
High-Resolution Feature → High Transformer Regression Performance
Mesh Dimension
•
일반적으로 사용하는 Fine-Level Mesh(SMPL)는 6890 개의 점으로 표현되는데, 이는 Memory에 큰 부담이됩니다.
•
따라서, 모델에선 SubSampling을 거친 Coarse-Level(431개) Vertices만 사용합니다.
•
모델 연산이 끝나면, 2-Layer MLP를 이용해 Coarse(431) → Fine(6890) Upsampling을 해 Output을 얻습니다.
[Progressive Dimensionality Reduction]
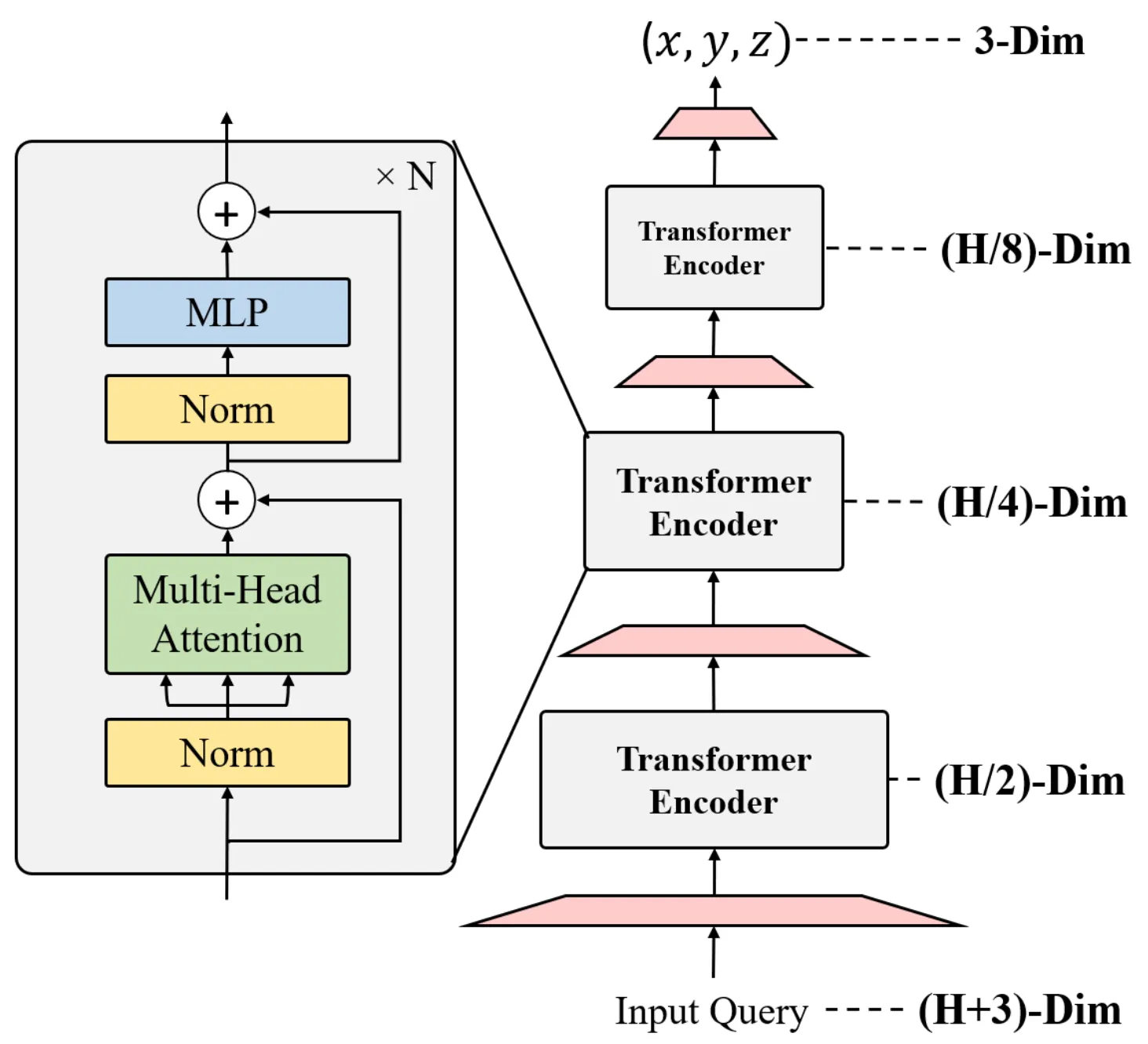
•
Constant하게 Dimension을 가져가는 기존 Transformer 대신,
•
Progressive Dimensionality Reduction Architecutre를 개발했습니다.
•
Dimension Reduction을 위해 Encoder Block 끝에 Embedding을 통해 Linear Projection을 사용합니다.
•
3D Coordinates에서의 Joint, Vertex 좌표가 마지막 Output으로 나옵니다.
[Positional Encoding with Template]
•
Input Query의 위치정보를 보존하기 위해 Positional Encoding 처럼 3D Human Template을 사용합니다.
•
인 경우를 예를 들어 설명하자면
1.
3D Human Template으로 부터 를 얻습니다.
•
( 는 Body Joint, 는 Mesh Vertex)
2.
와 를 Concat 합니다.
3.
, 를 Query로 사용합니다. ()
[MVM(Masked Vertex Modeling)]

[MLM]
•
BERT와 같은 NLP Transformer Model은 MLM(Masked Language Modeling)을 사용합니다.
MLM이란?
•
MLM을 통해 Bi-Directional을 극대화 시키고, 이를 통해 언어적 특성을 학습하도록 하는데,
•
기존 MLM은 Input Recovering에 초점이 맞춰져 있어 3D Regression Task에 바로 활용하기 어렵습니다.
•
따라서 저자들은 MVM(Masked Vertex Modeling)을 제안합니다.
[MVM]
•
MLM과 동일하게 Input Query의 일부를 Masking합니다.
•
Input을 Recovery 하는 대신, 그 Query로 모든 Joint Vertex와
•
를 Regress하도록 학습시킵니다.
•
모델은 누락된 Query의 Joint, Vertex도 예측해야 하므로, 다른 Query를 활용하는 법을 배울것이고(Occlusion과 같은 상황)
•
결과적으로는, Transformer가 Mesh Topology에 관계없이 가변적으로 필요한 Joint에 Attention하는 능력을 강화해줄 것입니다.
Loss Details
[Basic Loss]
•
Dataset = {이미지, 3D Vertex, 3D Joint, 2D Joint} 가 주어지면 다음과 같은 Loss를 계산한다.
•
(Vertex)
•
(Joint)
[Trick Loss]
•
결과값에 대한 Loss 이외에도 2가지 Loss를 더 사용하는데, 종류는 다음과 같다.
•
(Regressed)
◦
3D Mesh와 Reg Matrix()를 곱하면 3D Joints를 계산해낼 수 있다.
◦
즉 = 이며, 똑같이 L1 Loss를 사용한다 (는 사전 정의된 고정 Matrix)
•
(Re-Projected)
◦
3D → 2D Projection해 2D Joint를 계산해 낼 수 있다.
◦
사용되는 Cam Parameter는 모델이 Estimate한다.
(2D, 3D Dataset을 동시에 사용 하면 일반화에 유리하다)
[Total Loss]
( 는 각각 3D, 2D Avaliability를 나타내는 Binary Flags)
4. Experimental Results

Dataset
[3D Dataset]
•
3DPW
•
UP-3D : 아웃도어 이미지 데이터셋, 7000장, Annotation은 Model Fitting으로 생성됨
•
MuCo-3DHP : 3DHP를 기반으로한 Real-world BackGround 합성 데이터, 20만장
•
H3.6M: 3D Mesh가 없어서 SMPLify-X로 Pseudo Data를 만들어 사용
(Train : S1, S5, S6, S7, S8, Test : S9, S11)
[2D Dataset]
•
MPII
•
COCO : 3D Mesh SMPLify-X로 Pseudo Data를 만들어 사용
(3D Hands)
•
FreiHAND : METRO 의 확장성을 입증하기 위해 사용한 Hand Dataset
(Train : 130K, Test : 4K)
BenchMark
•
3DPW
◦
Wild하며, Occlusion이 자주 발생합니다.
◦
METRO는 VIBE를 누르고 SOTA를 달성함으로서, Wild한 환경에도 강력함을 보였습니다.
•
H3.6M
◦
3DPW대비 장면이 간단하므로, Body Shape을 정확히 측정해야합니다.
◦
METRO는 PA-MPJPE에서의 엄청난 성능 향상을 보였습니다.
→ 즉 METRO는 Wild & Occlusion에도 강건하고, 정확한 Body Shape을 추정한다고 볼 수 있습니다.
4-1. Experimental Results
[Effectiveness of Masked Vertex Modeling]


1.
MVM이 실제로 효과가 있는가 ?
•
H3.6M을 통해 실험한 결과 MVM의 유무에 따른 성능차이가 꽤 큰 것을 관찰할 수 있었습니다.
2.
어느정도로 Masking하는게 최적일까?
•
3DPW로 실험한 결과, 30%까진 Masking Ratio를 늘릴수록 성능이 향상되는 것을 관찰할 수 있었습니다.
•
30% 이상 Masking하면 효과가 줄어드는 양상을 보였습니다.
[Input Representation]

[ 정성적 평가 ]
•
CNN Backbone이 성능에 미치는 영향에 대한 실험입니다.
•
ResNet50, HRNet 을 이용해 을 추출했으며 ImageNet Pre-Train 상태입니다.
•
Final Feature Map Resoultion이 커질수록 Metric이 향상되는 모습을 보입니다.
[Non-Local Interaction 정량적 평가]

[ 정량적 평가 ](표2)
•
3DPW 무작위 5000장을 추출해 Self-Attention Score를 시각화한 표입니다.
•
전반적으로 Lower-Arm, Lower-Leg의 Score가 높은 양상을 보입니다.
•
이는 IK와 같은 선행 연구 관점에서 봤을때 타당한 양상입니다.
[Non-Local Interaction 정성적 평가]

[ 정성적 평가 ](표1)
•
Joint와 Mesh간 Interaction이 학습에 어떻게 영향을 끼치는지 Attention 시각화를 통해 확인해 봤습니다.
•
(행1) 우측 몸통이 가려졌음에도, 머리,왼쪽 손목(Non-Local)의 Interaction을 통해 결과를 잘 예측합니다.
•
(행2) 오른손목을 추론할 때, 다른 이미지와 달리 오른발과 Interaction합니다 (이미지 특성 반영)
•
(행4) 몸이 반쯤 접혀있는 어려운 포즈인데도, 머리 - 손 - 발 Interaction을 통해 결과를 잘 예측합니다.
[Generalization to 3D Hand in-the-wild]

•
METRO 는 Mesh Reconsturction에 대해 굉장히 유연하고, Robust한 구조입니다.
•
•
METRO를 Scratch로 훈련시켜 1등을 차지했습니다.
5. Conclusion
1.
단순하지만 강력한 Mesh Transformer Framework METRO 를 제안합니다.
2.
Non-Local Interaction을 배우기 위해 Masked Vertex Modeling 방법을 제안합니다.
3.
METRO 의 강력한 성능은 Input에 Depedent해 고정된 Mesh Topology와 관계없이, Non-Local Interaction 할 수 있음에 기인합니다.
4.
METRO 는 FreiHAND Competition와 같이, 다양한 Domain의 Reconsturction 으로 확장될 수 있음을 보였습니다.