
예상 독자
•
CS224w의 1~8강 을 수강했거나, GNN & WL-Kernel 에 대해 알고있음
•
기본적인 NeuralNet & Pooling 에 대해 알고있음
핵심 내용
•
GNN의 표현 능력 은 어떻게 정의되는가?
•
GCN과 GraphSAGE의 한계는 무엇인가?
•
GIN 이란 무엇인가?
9. Theory of Graph Neural Networks
최근 강의에서 우리는 Graph Neural Networks(이하 GNN)를 주로 다루고 있다. 이번 강의는 GNN의 표현능력과 범위에 대해 다룬다. (전체적으로 강의 내용 흐름이 이리갔다 저리갔다 하지만, 나중에 하나로 통함)
9.1 How Expressive are Graph Neural Networks
(Recap) GNN의 아이디어는 (1) Node의 Local Neighborhood로부터 (2) NeuralNet으로 정보를 Aggregation해 Embedding을 만드는 것이다.
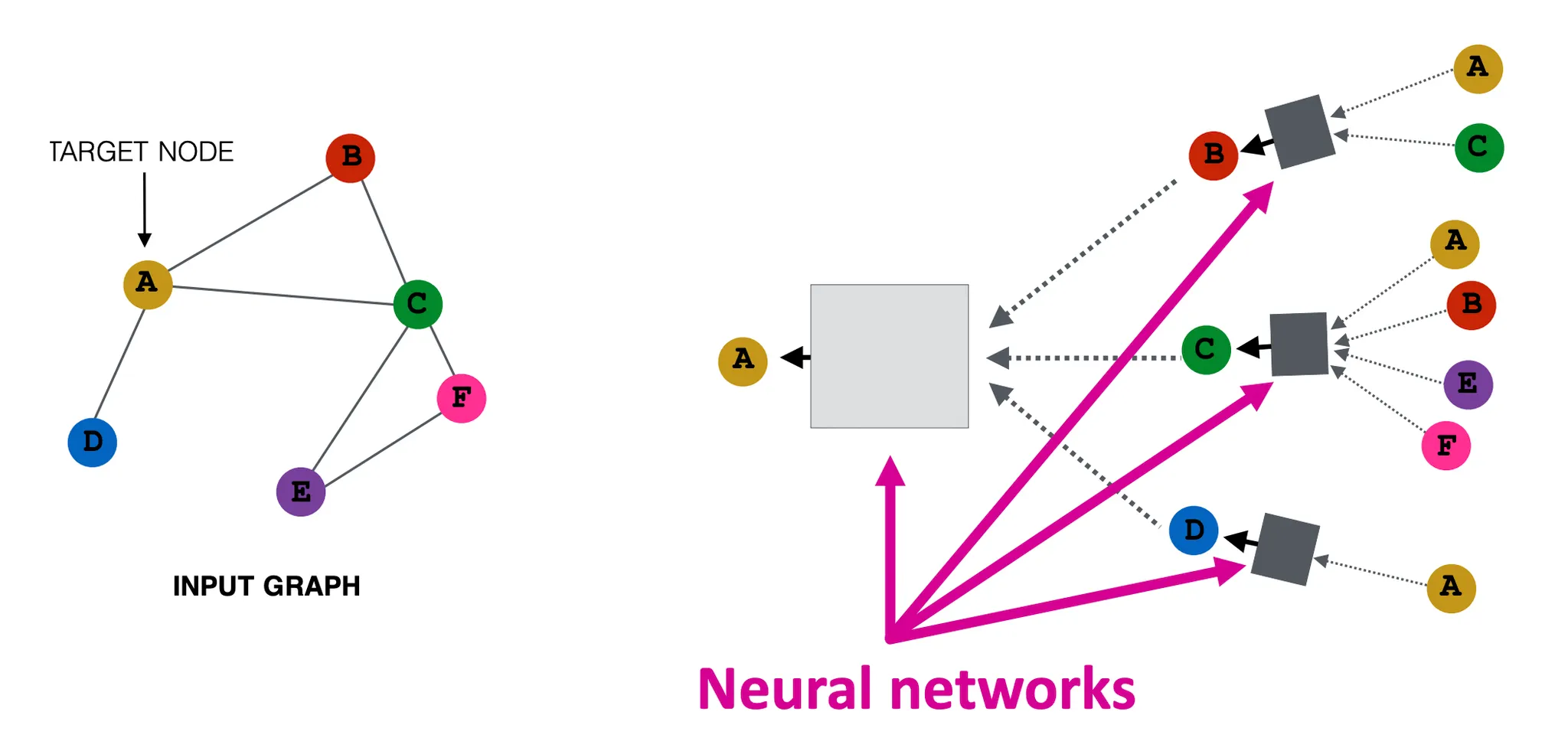
Theory of GNNs
(1) GNN을 기반으로한 여러 모델들이 강력한 성능을 계속해서 입증하고 있는데. (2) GNN들의 강력한 표현능력은 어디서 오는걸까? 구체적으로 말하면 GNN은 Node, Graph Structure를 어떻게 구별하는 걸까? (3) 어떻게 하면 그 표현력을 극대화 할 수 있을까?
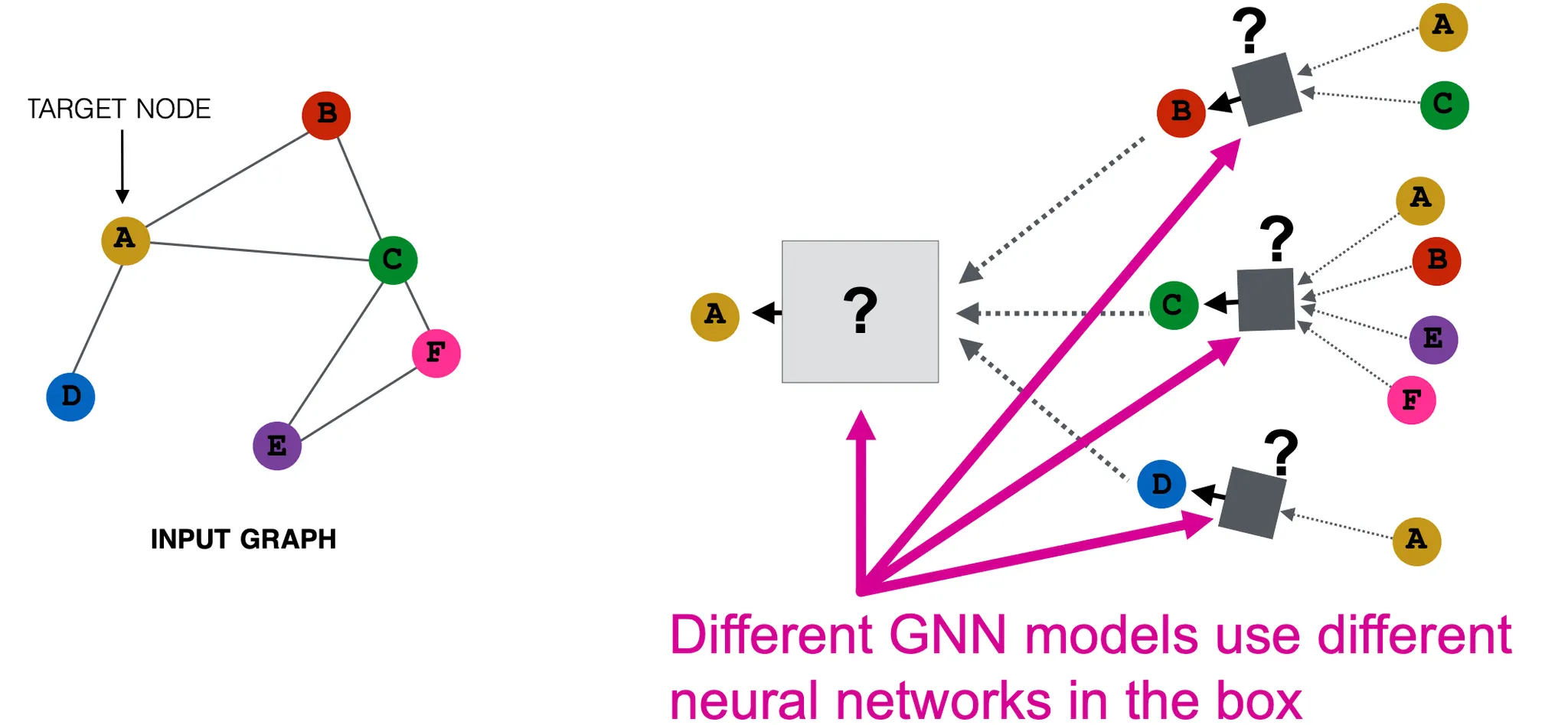
BackGround : Many GNN Models
GNN을 기반으로한 모델은 여러가지가 있으며, 각각은 다른 Propagation, Aggregation, Transfomation 방법론을 가지고 있다. 그러므로 각각의 표현력도 다르며 이를 잘 이해하고 선택하는 것이 중요하다

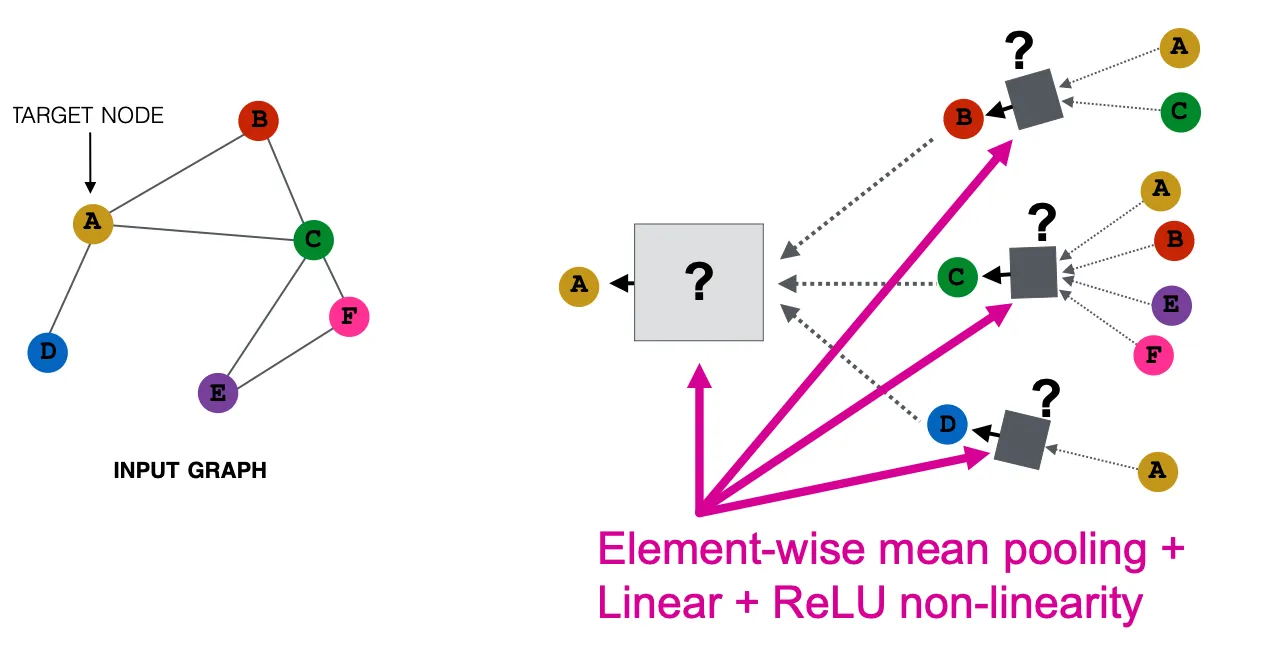
GCN(Mean-Pooling)
Element-Wise Mean Pooling으로 Aggregation 한뒤, Linear + Relu를 적용한다.
GraphSAGE(Max-Pooling)
Element-Wise Max Pooling으로 Aggregation한뒤, MLP를 적용한다.
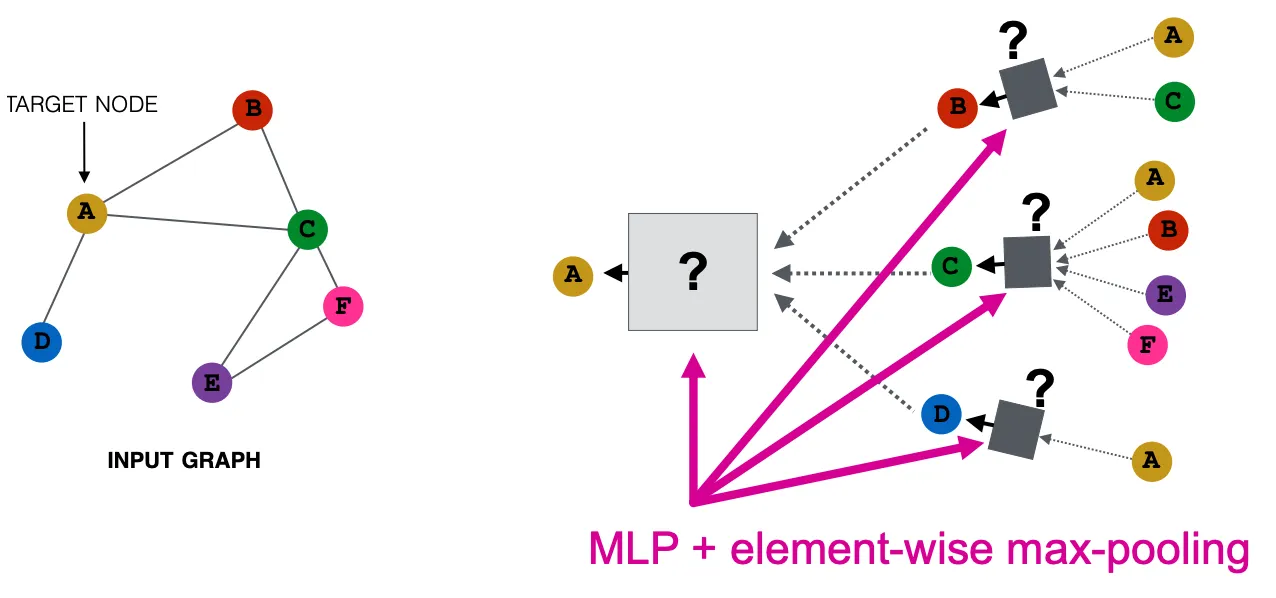
위의 예시와 같이 GCN은 Mean Pooling이고, GraphSAGE는 Max Pooling이다. 이러한 구조가 무슨 결과를 만들어 내는지는 이후에 다시 설명한다.
Local Neighborhood Structure
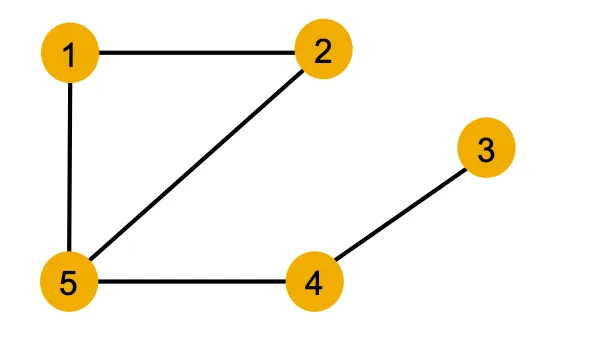
색깔은 Node Feature를 나타낸다. 같은 색깔이면 같은 Feature를 갖고있다고 간주한다. (숫자는 Node ID)
위는 모든 Node가 같은 Feature를 갖고있는 Graph의 예시이다. 만약 이런 Graph가 있다면 Node를 어떻게 구분할까? 직관적으로 모든 Feature가 동일하니 Local Neighborhood 구조를 이용하면 될 것 같다. 그리고 이 방식이 GNN이 사용하는 방식이다.
1.
관심있는 Node를 1번 Node라고 가정하고, 이웃 구조를 이용해 Node를 구분해 보자
1-Hop Degree를 이용하면 3, 5번 Node는 이웃 구조가 다르므로 구분이 가능하다.

2.
2-Hop Degree까지 늘리면 4번 Node까지 구분이 가능하다.
문제는 2번 Node이다. 대칭구조이기에 단순히 Degree를 세는 방법으로는 둘 간의 구분이 불가능하다.
이 부분은 한계라고 볼 수 있다.
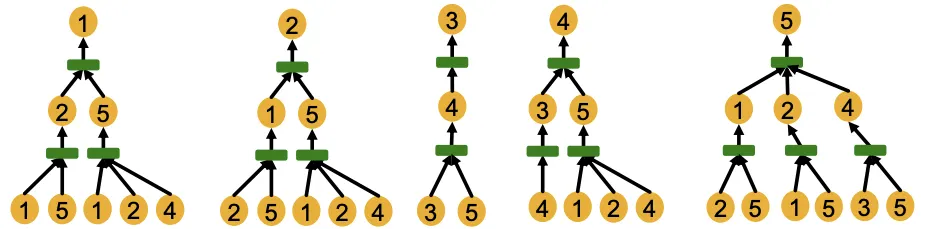
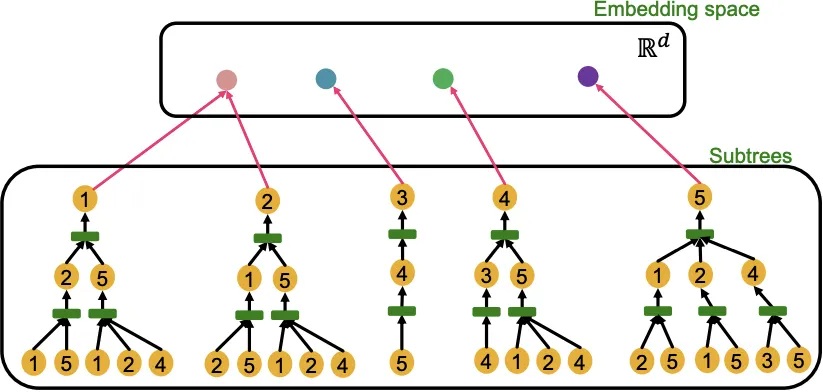
Computational Graph
위에서 계속 보았듯이, GNN은 각 Layer에서 이웃의 Embedding을 Aggregate한다. 즉 GNN의 Node Embedding은 이웃구조로 부터 정의된 Computational Graph로 부터 생성된다.
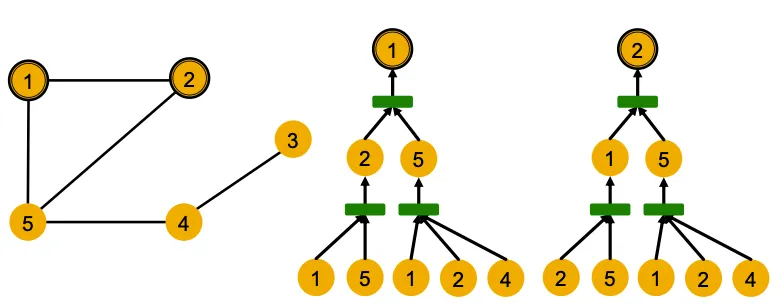
위의 그림은 예시의 1,2번 Node에 대하여 2-Layer GNN Computational Graph를 시각화한 것이다. GNN은 Node ID 정보를 사용하지 않으며, 동일한 Feature를 가진 Graph가 같은 모양으로 연결되어 있으니 같은 Embedding을 갖게 될 것이라는걸 알 수 있다.
이 예시를 통해 알 수 있는 사실은, Node Feature가 모두 동일한 상황에서 GNN은 같은 Computational Graph를 가진 Node에 대해 같은 Embedding을 만들어낼 것이라는 사실이다.
다시 말하면 (1) GNN의 Embedding은 Computational Graph로 부터 결정되고, (2) Computational Graph는 각 Node의 Rooted Subtree Structure에 의해 결정된다.
그리고 표현능력이 강력한 GNN은 위의 가정(이론)을 잘 만족한다. 즉 다른 Subtree를 다른 Node Embedding으로 매핑한다. (1,2번 노드는 한계로 인정하고, 나머지 노드들에 대하여 잘 구분할 수 있다)
Injective Function
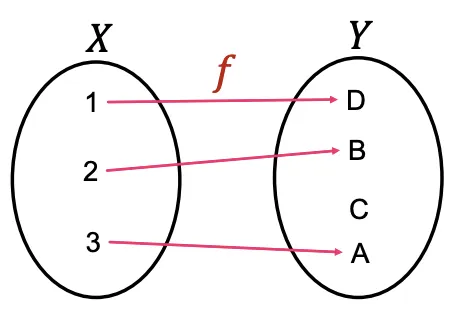
함수가 다른 입력에 대하여 다른 출력으로 매핑한다면 (일대일대응) 그것을 Injective하다고 부른다.
표현력이 좋은 GNN은 Subtree를 Embedding으로 Injective하게 매핑하며, 같은 Depth를 가진 Subtrees 라면 Root Node뿐만 아니라 각 Depth에서도 Neighborhood Structure에 따라 다른 Embedding을 갖도록 한다. 즉 Aggregation 함수가 Injective하면 강력한 GNN이다.

9.2 Designing the Most Powerful Graph Neural Networks
(Recap) GNN의 표현능력은 Neighbor Aggregation Function에 의해 결정된다. Neighbor Aggregation Function이 Neighbor Structure에 따라 Injective하게 Embedding을 Mapping하면 강력한 표현능력을 가졌다고 말할 수 있다.
Neighbor Aggregation
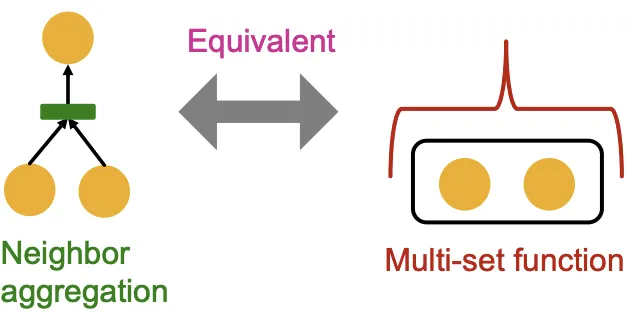

Neighbor Aggregation은 중복되는 원소가 있는 집합(Set)에 대한 함수로 정의될 수 있다. 여태 사용한 예시가 말단(Leaf)의 모든 원소가 동일하므로 좋은 예시가 될 수 있다. 예시를 그대로 이어가 아래의 내용도 Feature를 색깔로 나타내어 설명한다.
Injective한 Aggregation을 하려면 입력의 모든 특성을 Embedding에 반영해야 할 것이다. 그러려면 Aggregation Function이 원소의 등장 횟수, 색상별 등장 비율등을 종합적으로 고려할 수 있어야한다. 위에서 본 GNN 모델들이 이렇게 작동하는지 확인해보자.
GCN (Mean Pooling)
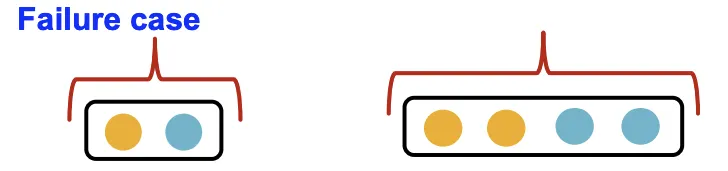

GCN은 Element-Wise Mean으로 정보를 합치고 Linear Function & Relu로 정보를 인코딩한다. 이 구조는 같은 색상 비율을 가진 Multi-Set을 구분할 수 없다는 한계가 있다. 단순한 예시를 들어서 설명하면, Color가 Feature고 이를 One-Hot Encoding으로 표현한다고 가정해보자.
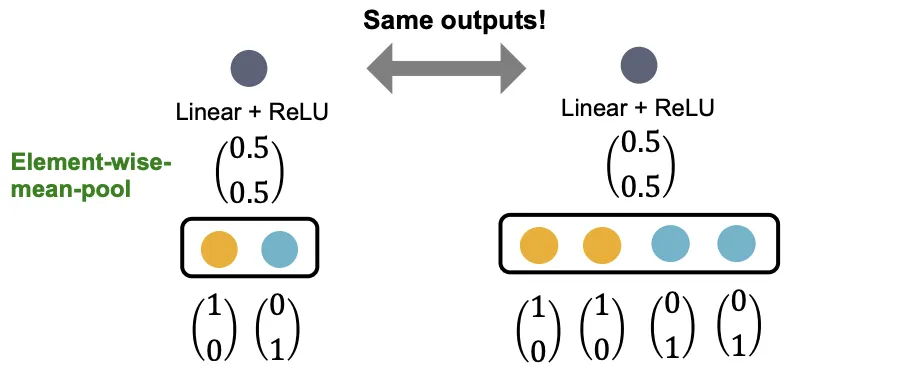
Element-Wise Mean은 색상별 원소의 비율이 동일하면 같은 결과를 뱉는다. Linear는 가중치를 공유하므로 Pooling 결과가 같으면 Linear + Relu 결과도 같다. 일대일 대응이 깨지는 순간이다.
GraphSAGE (Max Pooling)
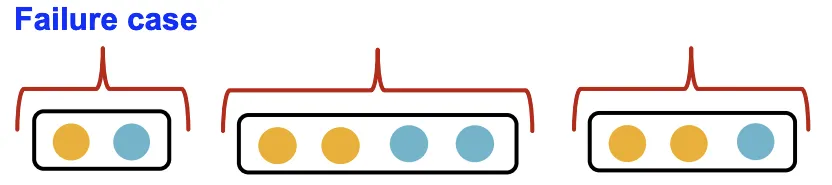
GraphSAGE는 각 원소에 대해 MLP를 사용하고 Element-Wise Max로 정보를 합친다. 이 구조는 등장 색상의 종류가 같은 같은 Mulit-Set을 구분할 수 없다는 한계가 있다.
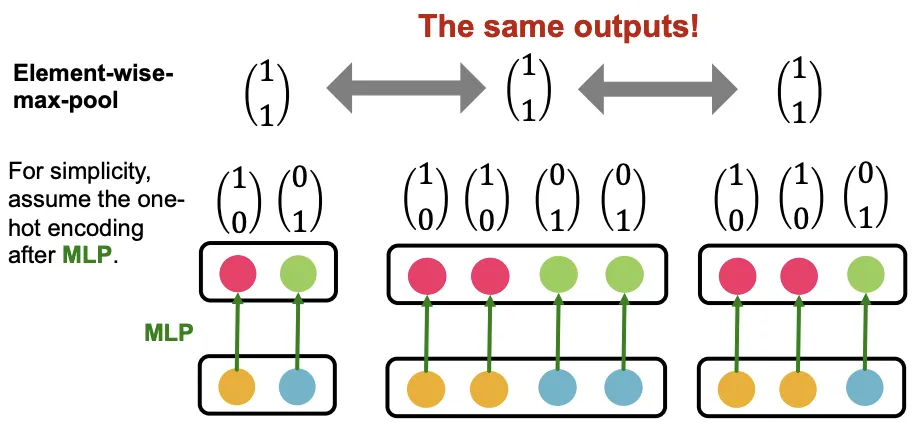
Element-Wise Max는 사용한 색깔 종류가 같으면 같은 결과를 뱉는다. MLP도 가중치를 공유하므로, 같은 색상의 입력이라면 MLP 결과값이 같을 것이고, Max는 그 중 큰 값만 가져오니 빈도에 상관없이 색상이 등장만 한다면 MLP + Max Pooling 결과가 같아진다. 일대일 대응이 깨지는 순간이다.
중간 Summary
1.
GNN의 표현능력은 Injective Neighbor Aggregation Function에 달려있다.
2.
Neighbor Aggregation Function은 중복원소가 가능한 Mulit-Set에 대한 함수이다.
3.
GCN과 GraphSAGE는 기본적인 Multi-Set에서도 Injective함이 깨진다.
4.
GCN과 GraphSAGE는 가장 강력한 GNN이 아니다.
5.
어떻게 하면 Injective함을 지켜 강력한 GNN을 만들 수 있을까?
Injective Multi-Set Function

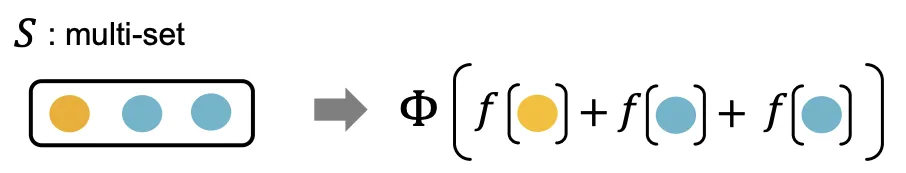
Injective Multi-Set Function은 다음과 같이 표현될 수 있다.
1.
Mulit-Set 에 대하여
2.
각 원소가 Non-Linear Function 를 거친 결과값을 합산한뒤(Sum)
3.
다른 Non-Linear Function 를 거치는 함수다.
Proof Intuition
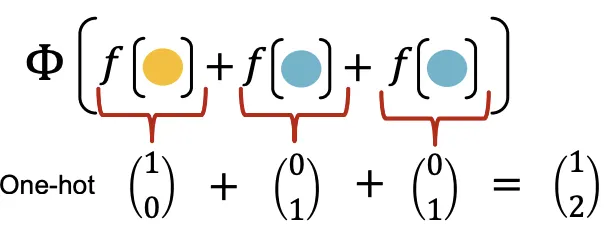
는 Color를 일종의 One-Hot으로 표현하고 Sum 연산을 통해 정보를 보존하면서 원소들을 합산한다. 이렇게 하면 정보의 손실 없이 Non-Linear 함수의 입력을 Encoding할 수 있다. 즉 Injective한 함수가 된다.
이때의 가정은 가 One-Hot처럼 Class와 빈도를 나타낼 수 있는 Representation으로 매핑한다는 것이다. 즉 실제로는 가 이 역할을 수행하지 못하면 Injective함이 바로 깨진다.
Approximation Theorem
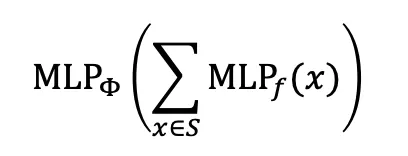
Injective함을 만들어주는 를 어떻게 모델링 할 수 있을까? Universal Approximation Theorem에 따르면 충분히 큰 Hidden Dimension과 Non-Linearlity 함수가 있다면 1-Hidden-Layer NeuralNet으로 어떤 연속함수든 근사할 수 있다. 그러므로 MLP를 이용해 를 잘 근사한다면, Injective한 Multi-Set Function을 만들 수 있다. (실제로 해보면 는 100~500 차원정도면 충분하다)
Most Expressive GNN : Graph Isomorphism Network (GIN)
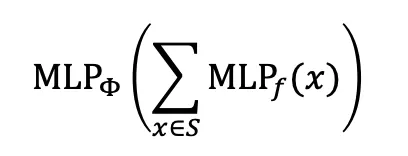
Approximation Theorem을 이용해 Injective Function을 근사하게 되면, MLP → Sum → MLP 구조의 함수가 만들어진다. 이것을 GIN이라고 부른다. GIN은 GCN, GraphSAGE와 달리 이론적으로 실패하는 Case가 없다. 즉 GIN이 Message-Passing GNN중 가장 강력한 표현능력을 가진 모델이라고 볼 수 있다.
여태 GIN의 Aggregation Function에 대해 알아봤으니, 모델의 전체적인 설계에 대해 알아보자. GIN은 WL Graph Kernel과 깊게 연관이 되어있으며, WL Graph Kernel의 Neural-Net 버전이라고 봐도 무방하다.
1.
Node 로 이루어진 Graph 가 주어지면
2.
각 Node 에 Initial Color 를 할당하고
3.
Iterative하게 이웃의 정보를 집계하고 HASH해 Node Color를 Refinement하는 알고리즘이다.
4.
Iter 횟수 에 따라 hop 이웃의 정보를 모을 수 있다.
Recall : Color Refinement
1.
동일한 Initial Color를 모든 Node에 할당한다.
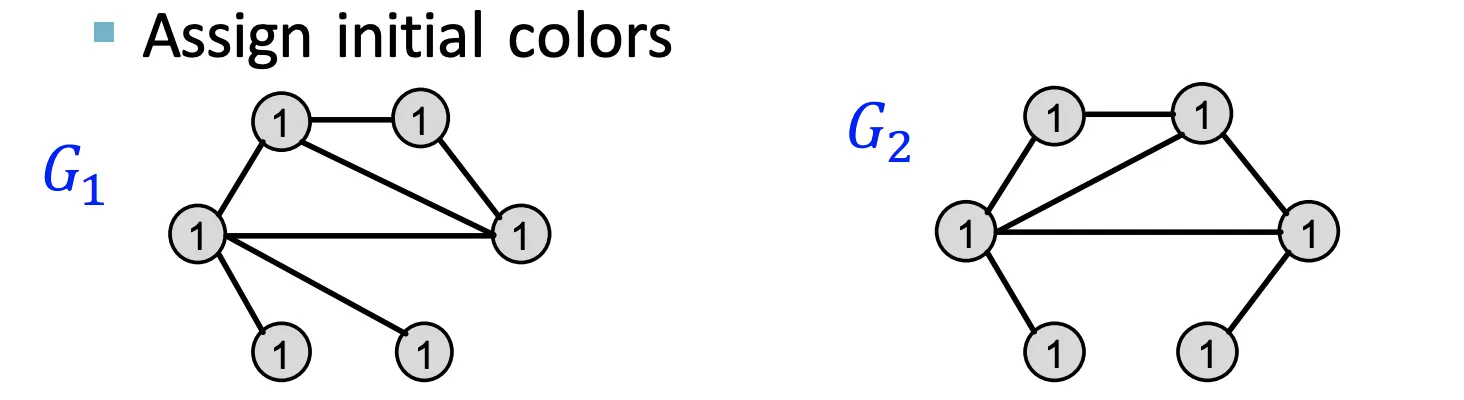
2.
이웃하는 색상에 대해 Aggregate한다.
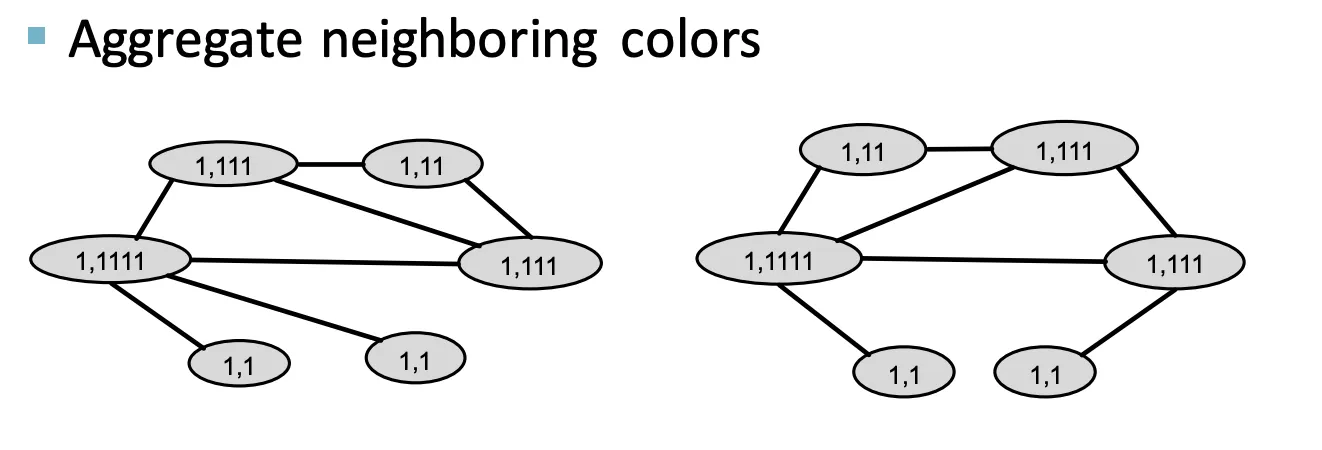
3.
Aggregate된 Color를 HASH한다. (Injective)
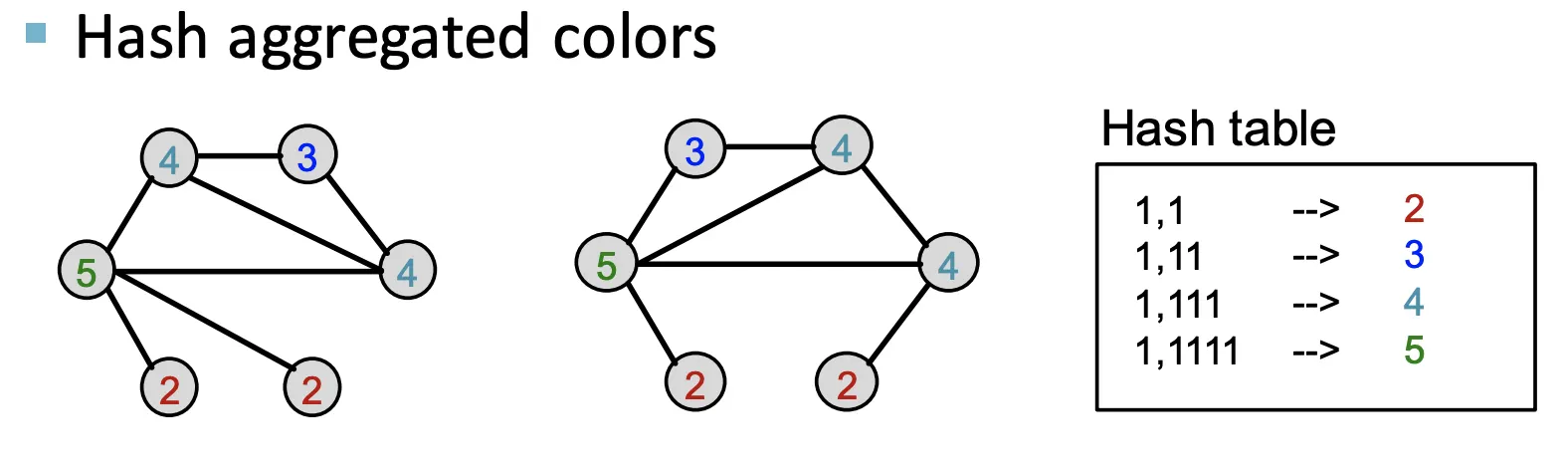
4.
2~3을 반복한다
The Complete GIN Model
GIN은 NeuralNet을 이용해 Injective HASH Fucntion을 구현한 것과 같다.
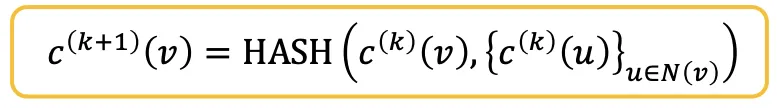
WL-Kernel의 Color Refinement Function
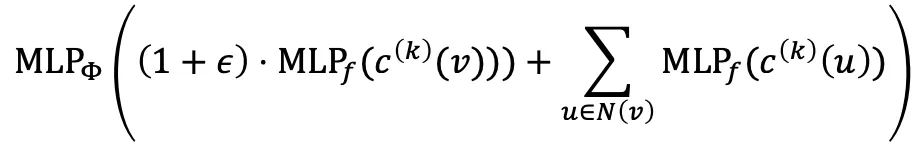
GIN / epsilon은 Learnable Scalar이다.
만약 Initial Color 가 One-Hot이라고 가정하면 Summation Ops의 결과물은 Injective하다.
따라서 가 Injective하면 일대일 대응이 보장된다. 그리고 GIN은 Multi-Layer이므로, 는 다음 Layer의 와도 같다.따라서 는 One-Hot과 같이 정보를 잘 보존하는 방식으로 학습되어야 한다.

난해한 내용 요약 (WL Kernel GIN)
GIN)
1.
Node 로 이루어진 Graph 가 주어지면
2.
각 Node 에 Initial Color 를 할당한다.
3.
각 Node Vector는 GIN Conv에 의해 Update되는데, MLP이므로 미분가능한 HASH 함수이다.
4.
GIN의 Iter 횟수 에 따라 hop 이웃의 정보를 모을 수 있다.
•
WL Kernel과 다른점은 3번에서 GIN Conv를 사용한다는 점 뿐이므로, WL-Kernel의 미분가능한 NeuralNet 버전이 GIN이라고 이해할 수 있다.
Power of GIN
WL Kernel의 HASH함수 대신 NeuralNet을 사용하면서 생기는 장점은 다음과 같다.
(1) Node Embedding이 곧 Hidden Dimension이므로 일반적으로 One-Hot에 비해 효율적이다.
(2) Update Function의 Parameter들을 DownStream Task에 사용할 수 있다.
(3) 그럼에도 WL Kernel과 완전히 동일한 성능을 보인다.
(WL Kernel은 Real-World의 Graph 대부분을 구분할 수 있을 정도로 강력한 성능이
이론적, 경험적으로 입증되었다.)
Summary of the Lecture
1.
Neural Net을 이용해 Injective Multi-Set Function을 모델링하는 방법에 대해 알아보았다.
2.
이를 통해 GIN이라는 모델에 도달했고, GIN은 가장 강력한 표현능력을 지닌 GNN 모델이다.
3.
핵심 요소는 Mean이나 Max대신 Element-Wise Sum을 이용하는 것이다.
관련 이미지
4.
GIN은 WL Kernel과 깊게 연관되어있으며 두 방법론 모두, 현실의 그래프 대부분을 구분할 수 있다.
Improving GNNs’ Power (복선)
이번 강의 내용을 바탕으로 GNN의 표현능력을 더 개선시킬 여지를 찾을 수 있다. 이후 강의는 그 문제들을 해결함으로서 GIN보다 더 강력한 GNN을 만드는 것에대해 다룬다.