

ML Projects
머신러닝과 딥러닝은 AI라는 이름으로 최근 10년간 수 많은 도메인에서 가능성을 증명했다. 많은 기업들이 이에 영감을 받아 AI를 이용한 무수히 많은 프로젝트를 했지만 결과는 미미했다. “10개 기업에 AI 프로젝트를 시작한다면 그 중 9개는 컨셉검증(POC)만 하다 끝난다”는 얘기까지 나오기 시작했다.
왜 많은 ML Project들이 실패했을까? 지속적으로 잘 동작하는 ML 서비스를 만들기 위해서는 ML 모델링 뿐만 아니라 다양한 워크플로우가 유기적으로 작동해야 하는데, 이에 대한 충분한 이해와 고려가 없다면 아무리 좋은 ML Model(Code)를 가지고 있더라도 좋은 서비스를 만들기 어렵다.
게다가 ML을 이용한 프로젝트들은 데이터, 개발환경, 컴퓨팅 자원(GPU)등 관리해주어야 하는 요소도 많기 때문에, 복잡성이 일반적인 소프트웨어 프로젝트보다 빠른 속도로 증가한다.
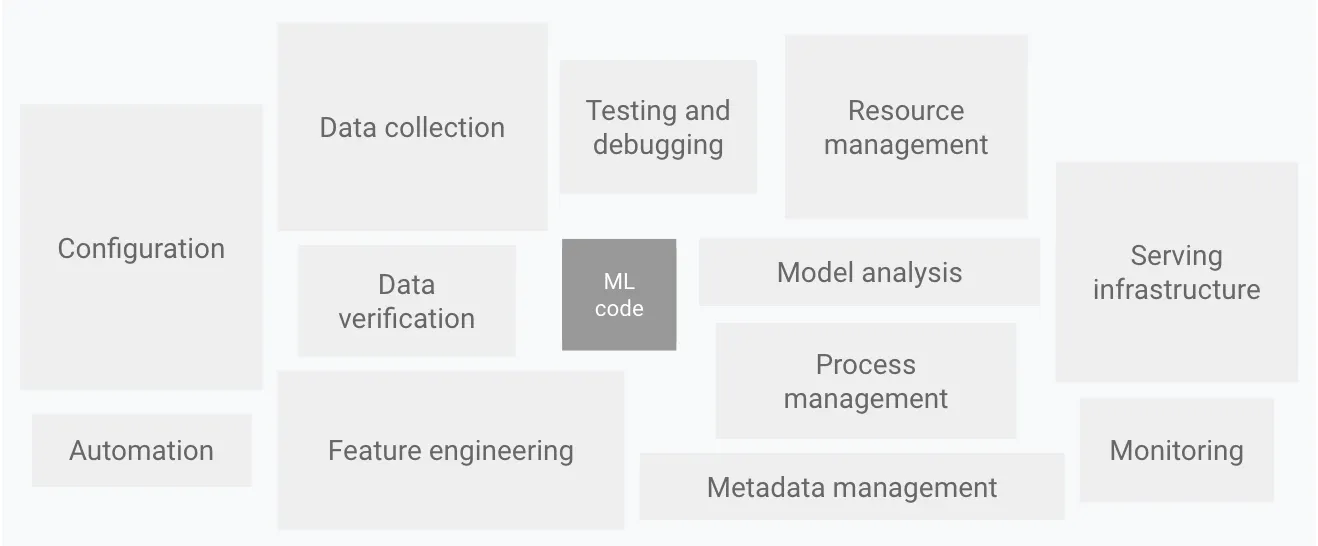
“Hidden Technical Debt in Machine Learning Systems(2015)”
구글은 2015년에 이 문제를 지적하면서 시스템의 다른 요소에도 집중하는 패러다임을 간략하게 제시했는데, 여기서 부터 출발한 개념이 MLOps이다.
What is MLOps?
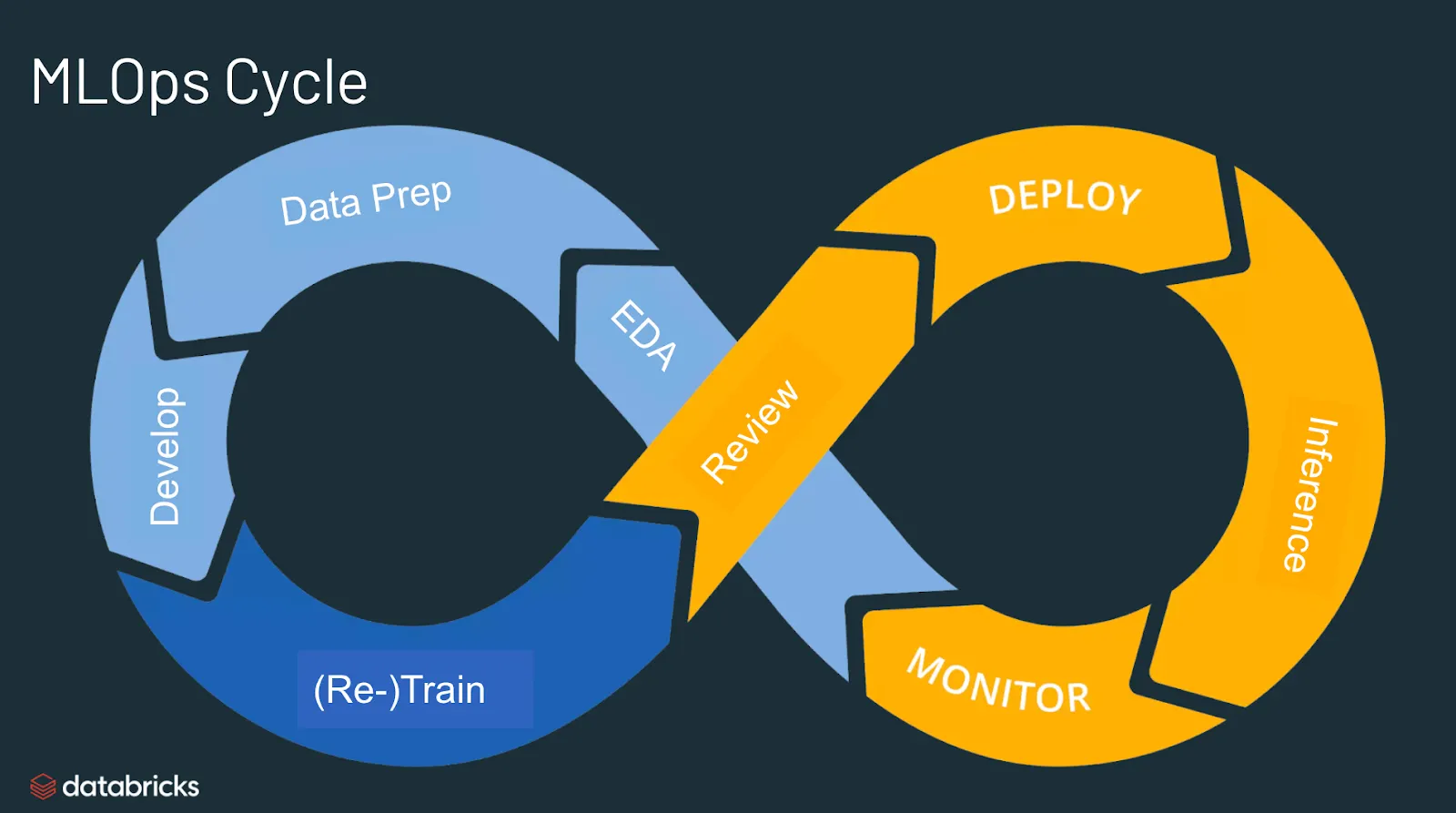
databricks glossary
MLOps는 ML + Operation의 합성어로 Machine Learning(실험연구)와 Opertation(배포운영)을 통합, 관리하는 것을 목표로 하는 엔지니어링 철학이다. MLOps가 구체적으로 추구하는 바가 무엇일까? MLOps 개념이 도입되지 않은 프로세스를 보며 알아보자.
Level 0: Manual process
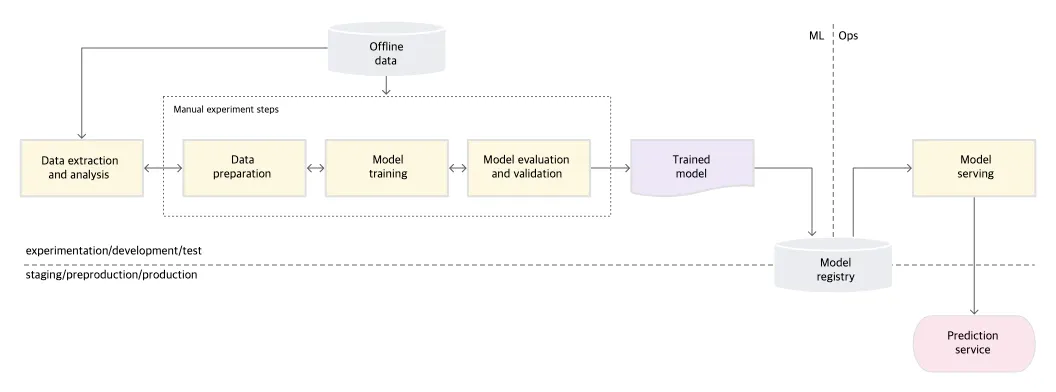
MLOps 개념이 없는 모든 단계가 수작업인 프로세스이다. Google Cloud에선 이 단계를 Level 0로 정의하고 있다. 연구자는 데이터를 Offline으로 가져와, 각자의 환경 (특히 재현이 어려운 Jupyter Notebook)에서 분석, 전처리, 모델링을 수행한다. 연구자가 쓸만한 모델을 만들면, 엔지니어는 모델을 전달 받아 인프라(환경) 세팅 및 API로 배포하는 역할을 맡는다. 이 프로세스에선 일반적으로 연구자와 엔지니어가 분리되어 있으며, 모델 배포가 자주 일어나지 않는다는 특징이 있다. Level 0 는 초기 ML 팀에서 아주 흔한 형태인데, 얼마 못 가 현실의 문제에 바로 부딪힌다. 일반적인 문제 시나리오는 다음과 같다.
Bad cases
1.
연구자가 자신의 환경에서 자신만의 코드로 모델을 만들어 서비스에 배포를 요청한다.
2.
엔지니어의 환경에서는 전달받은 모델이 동작하지 않거나, 성능 재현이 되지 않는다.
3.
서로 Sync를 맞추어 나가며, 우여곡절 끝에 배포를 해낸다.
+ Bad Case(1) 배포를 할 때 마다 전 영역(데이터, 모델, 서빙)에서 Flow와 Code의 복잡도가 증가한다.
+ Bad Case(2) 배포를 하고나니 서비스 환경에서 직전 모델보다 성능이 좋지 않다.
+ Bad Case(3) 배포 한 번에 많은 시간과 노력이 들어 작업자들은 배포를 꺼리게 된다.
4.
배포 간격이 점점 길어지고 변화에 적절히 대응하지 못해 모델이 실패한다.
What is MLOps for?
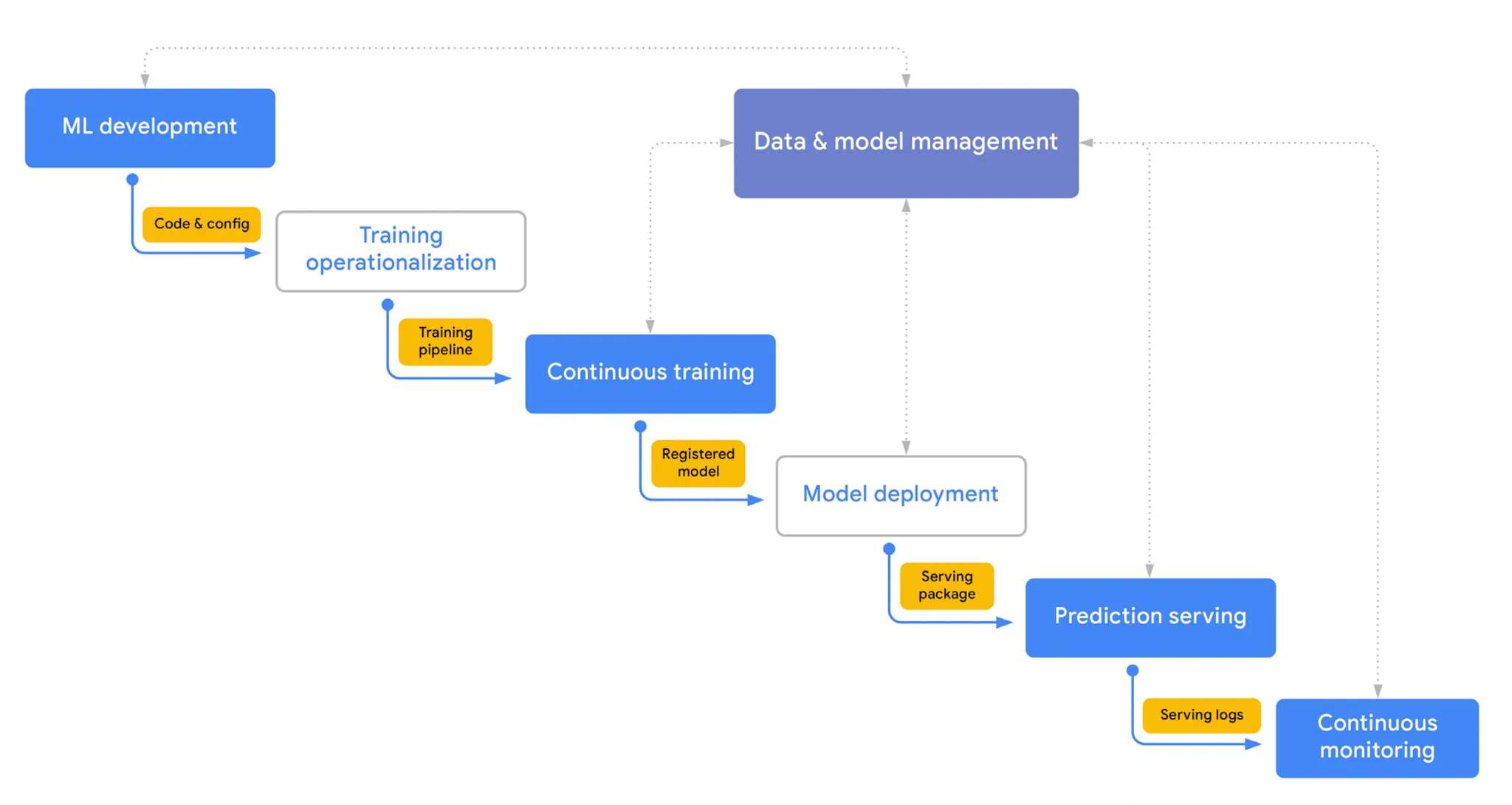
MLOps는 위와 같은 문제를 해결하기 위한 엔지니어링 철학이다. ML과 Ops간의 간극을 줄이고 데이터 추출부터 모델 배포, 모니터링, 재학습 까지 하나의 연속적인 순환 과정(Lifecycle)으로 바라본다. 이를 통해 손쉽게 실험하고, 빠르게 배포하고, 안정적으로 운영되는 유기적 ML 시스템을 만들 수 있다.
Componets of MLOps
Model-Centric에서 Data-Centric으로 AI의 패러다임이 옮겨가고 있는 상황에서, 현실세계의 변화에 민첩하게 대응할 수 있는 MLOps는 ML Production의 필수적인 요소가 되어가고 있다. 그렇다면 구체적으로 MLOps System을 구현하기 위해선 어떤 요소가 필요할까? MLOps를 이루고 있는 핵심요소(Component)를 다음 글을 통해 알아본다.
참고한 글 :