
Abstract
User Representation으로 Single Latent Vector를 쓰는것은 유저의 다양한 관심사를 모델링하기 어렵다. PinnerSAGE는 Hierarchical Clustering을 통해 대표적인 행동들을 추출해 풍부한 표현을 만들어 낸다.
Introduction
User Representation을 만들어 낼때 가장 어려운 부분은 “어떻게 유저의 다양한 측면을 인코딩할 수 있는가” 이다. 하나의 Vector로는 다양한 측면을 표현하기 어렵기에, 대부분 Multiple Embedding을 사용하는 방법으로 이를 해결한다. PinnerSAGE는 Pinterest에 배포된 Multiple Embedding 방법이다. Hierarchical Clustering과 Medoid를 통해 효율적으로 Multi Embedding을 뽑아낸다.
Model
 Design Choices
Design Choices
1. Item Embedding 고정 : User와 Item을 같은 Space에 뿌리면 문제가 생길 수 있다.
2. Embedding 갯수 무제한 : 제한을 두면 고품질 Embedding 뽑는데 방해됨
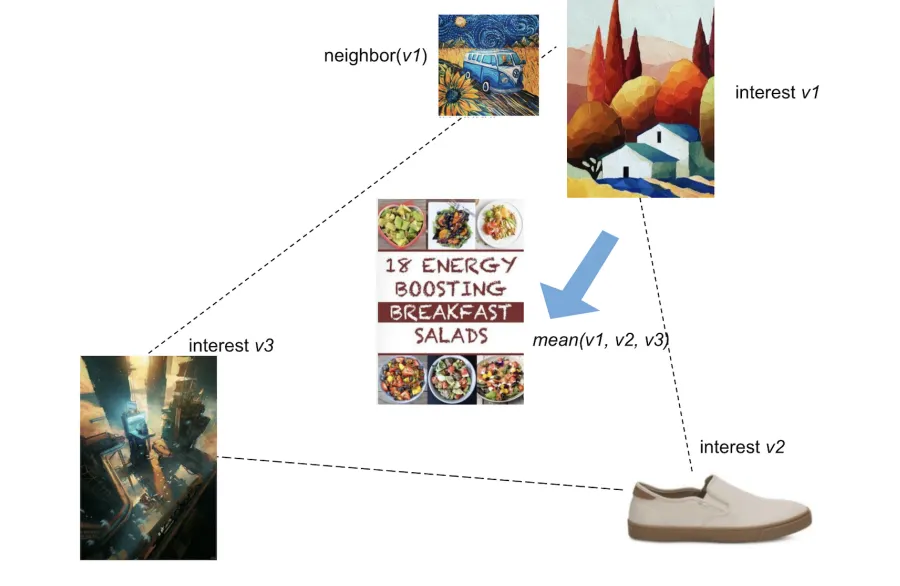
3. Medoid Clustering : 특정 Item을 Cluster 대표값으로 사용한다 (Robust & Efficient)
4. Medoid Sampling : Production에선 3개의 Medoid만 Retrieval을 위해 Sampling한다.
5. Two-pronged Approach : 장단기 Interaction을 고려하기 위해 두 타입의 Medoid를 만듦
PinnerSAGE
1. 최근 90일의 Interaction을 가져와서 Ward Clustering함
•
Ward Clustering : 초기엔 각 Data Point가 각 Cluster → Step을 돌면서 거리 Threshold에 따라 통폐합
2. Medoid를 통해 각 Cluster의 Representation을 추출함
•
Medoid : Cluster 내부의 다른 Data Point와의 L2 거리가 최소인 Data Point
3. 각 Cluster의 Importance Score를 얻어냄
•
: 시간에 따라 Importance 감쇠 (=Pin)
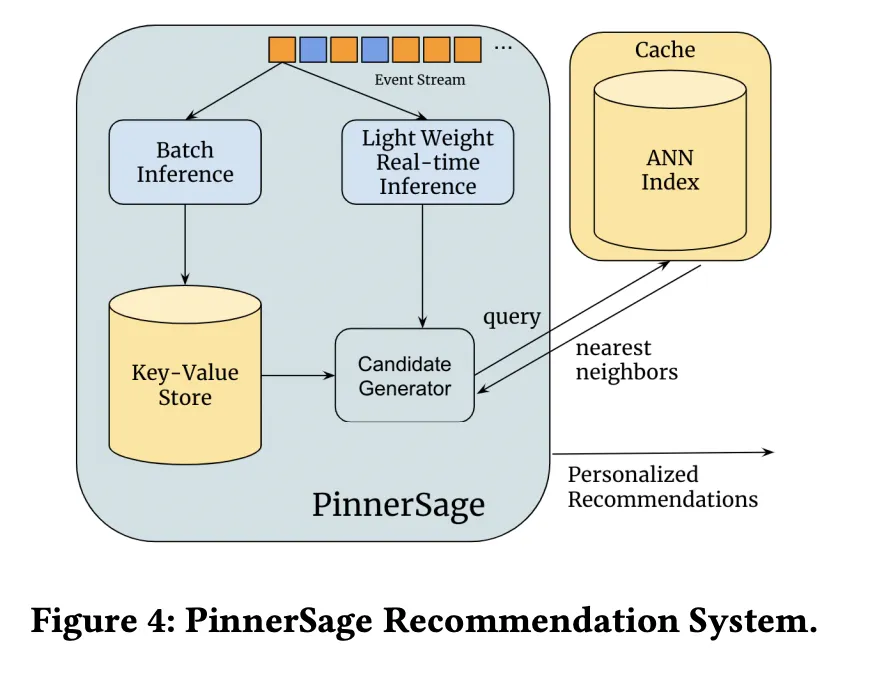
Serving
Daily Batch Inference
•
90일치 데이터로 Cluster 만드는 작업을 매일 Batch Job으로 수행
Online Inference
•
아직 Batch Job이 이루어지지 못한 액션을 유저별로 최근 20개씩 가지고와서 Cluster를 만듦
Figures
Conclusion
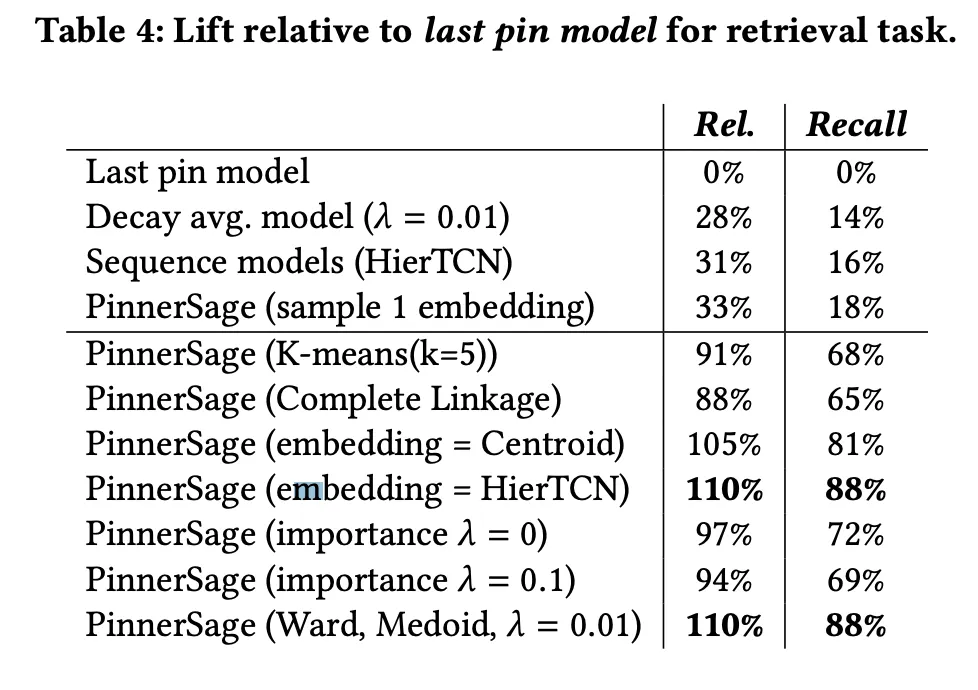
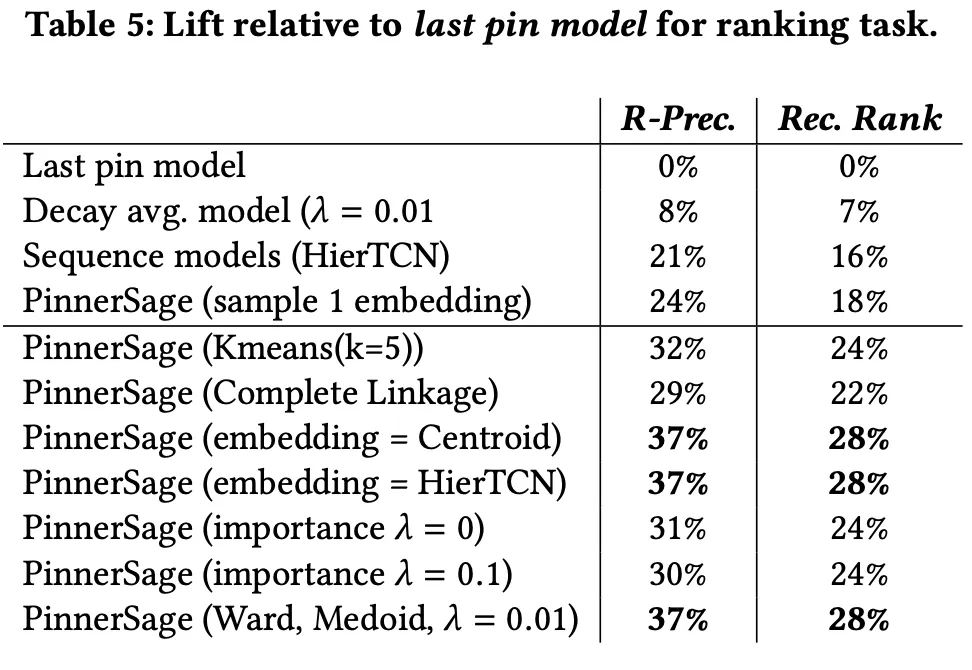
PinnerSAGE는 Mulit-Embedidng을 통해 User에 대한 풍부한 Representation을 뽑는 효율적인 방식을 제안했다. Offline 실험에선 굉장한 성능 향상을 보였고, Online A/B Test에서도 높은 수치의 지표 향상을 보였다.