
0. Abstract
Challenges in adapting Transformer to Vision Task
1.
Visual 객체들은 Variantions이 크고 Text의 Word에 비해 Image의 Pixel Resolution이 매우 크다.
2.
이 문제를 해결하기 위해 Shifted Window를 사용한, 계층적(Hierachical) Transfomer를 제시한다.
Shifted Window
1.
이미지 상에서 겹치지 않는 Local Window를 정의하고, 그 안에서만 Self-Attention을 한다
2.
Window간 Connection을 허용한다.
결과 : (1) Image Size에 따라 Linear하게만 Cost가 늘어난다. (2) Global Interaction도 챙긴다.
Hierachical Architecture
Visual 객체들의 Variant한 Scale에 잘 대응할 수 있다.
이런 접근법을 이용해 광범위한 Vision Task에서 좋은 성능을 얻었다.
Image Classication에서 어느정도 좋은 성능 (86.4 top-1 accuracy on ImageNet-1K)
Object Detection, Semantic Segmentation 같은 Dense Prediction에선 SOTA
1. Introduction
Computer Vision, CNN
Transformer, NLP
Transferring to Computer Vision
Visual Task에서 Transformer가 NLP에서 만큼의 성능이 나오지 않는 이유는 다음으로 보인다.

Scale
NLP : Basic Element로서 Word Token을 사용하며, Scale이 Fix 되어있다.
Vision : Basic Element로서 사용할 객체가 고정되어 있지 않으며, Scale이 매우 다양하다
⇒ 현존 Transformer들은 Token의 Scale이 Fix되어 있으며, Vision Application에 부적합하다.
Resolution
Image의 Pixel Resolution이, Text의 Word Resolution보다 압도적으로 큰데, 특정 Vision Task는 Pixel Level에서 부터의 Dense Prediction이 필요하다. Self-Attention의 계산 복잡도는 이미지 크기에 대해 Qudratic하게 증가하므로, 이런 Task에 적합하지 않다.
General Purpose Transformer Backbone
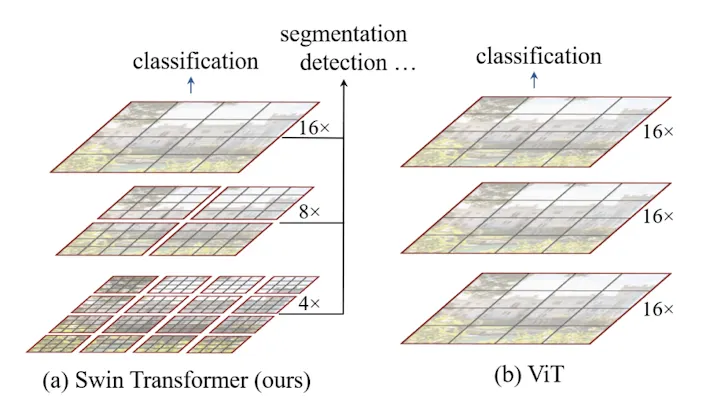
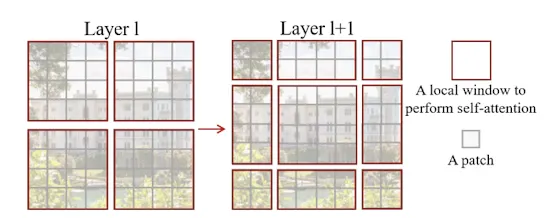
[Patch : 회색 테두리] [Window : 빨간 테두리]
Swin은 위의 문제에 집중해 Visual Task에 General 하게 사용가능한 Transformer Backbone을 만들었다.
Approach for Scale Problem : Hierachical Feature Map
모델이 깊어지면, 작은 Patch들을 통합해 나감으로서 계층적 Feature Map을 만든다.
Approach for Resolution Problem : Local Attention
Image Partition에 대해 겹치지 않는 Window를 만들고, 그에 대해서만 Self-Attention을 수행한다.
이때 Window별 Patch의 수는 고정이 되어있으므로, 이미지 크기에 대한 선형적인 계산 복잡도를 가진다.
Swin : Shifted Window
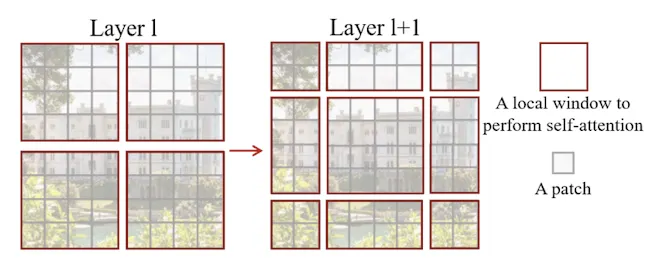
Swin은 연속되는 Self-Attention Layer 사이에서 Window를 이동시키는것을 일컫는다. Window가 이동함으로서 이전 Layer와의 연결성이 생기며, 이는 Model Power를 강화시킨다. Shifted Window 방법론은 모든 Query Patch가 같은 Key Set를 공유하므로, Sliding에 비해 Latency에서 강점을 가진다.
Swin은 Object Detection, Semantic Segmentation등의 Dense Task에서 강력한 성능을 보였으며, ViT, DeiT, ResNe(X)T과 비교해, 더 강력한 성능과 유사한 Latency를 보여주었다.
2. Related Works
-
3. Method
3.1 Overall Architecture
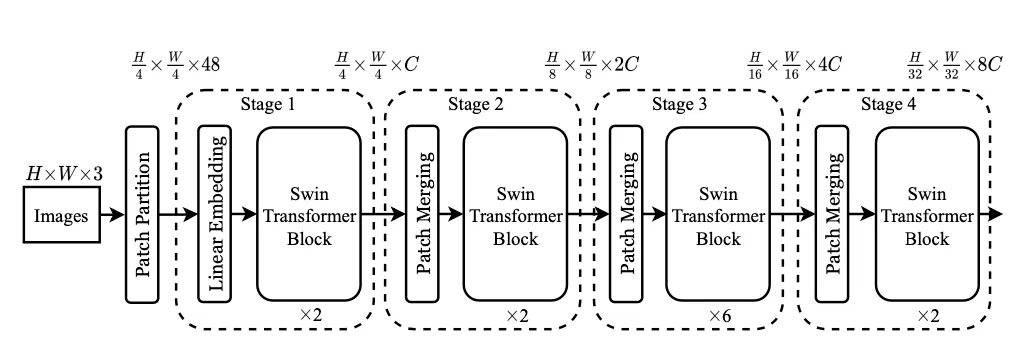
Tiny Version ( Swin - T )
1.
RGB Image를 겹치지 않는 Patch로 분리한다. (Patch Partition)
2.
Patch를 차원으로 Linear Embedding 한뒤 Swin Transformer Block에 통과시킨다 (Stage 1)
3.
2칸 간격 Patch끼리 Concat 하고() 로 Linear Projection한다. (Patch Merging)
(Patch의 갯수는 1/2 로 줄어들고 Receptive Field는 넓어진다)
4.
Transformer Block에 2번 통과시킨다(Stage 2)
5.
Stage3,4도 3,4번과 동일한 방식으로 진행한다.
Resolution = {stage1 : H/4, stage2 : H/8, stage3: H/16, stage4: H/32}
3.2 Shifted Window Based Self-Attention
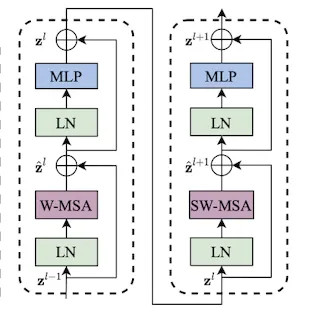
[Two Successive Swin Transformer Block]
ViT에서 MSA만 Shifted Window 기반 모듈로 대체한 구조이다.
A. Self-Attention in non-overlapped windows
Swin에서 MSA는 Window 단위로 이루어진다. Window는 이미지에서 겹치지 않는 영역으로 분할된다.
Patch가 , Window는 Patch 로 이루어져 있다고 가정하면 복잡도는 아래과 같다.
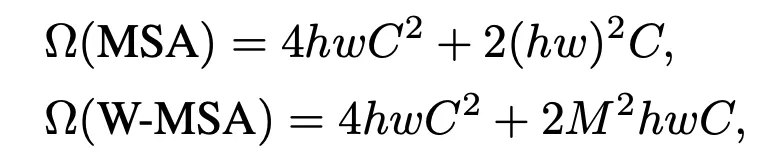
에 대해 MSA는 Qudratic한 복잡도를 가지고, W-MSA는 Linear한 복잡도를 가진다.
B. Shifted window partioning in successive blocks
W-MSA만으로는 Cross-Window Connection이 부족해, Shifted-Window Partioning을 사용한다.

1.
Swin Transformer Block은 2개의 연속된 MSA → MLP Layer로 이루어져 있다.
2.
첫번째 MSA는 W-MSA Block으로 Top-Left부터 시작해 Window를 나눈다.
3.
두번째 MSA는 SW-MSA Block으로, 이전 Window를 만큼 이동시켜 사용한다.(Shifted)
Problems of shifted window configuration
Shifted Window Partioning 을 그냥 사용하면 다음과 같은 문제점이 생긴다.
1.
Window 개수가 늘어난다 : 에서 갯수로 바뀐다.
2.
보다 작은 Window가 생긴다.
이 문제를 Naive하게 해결하는 방법은 작은 Window에 Pad & Mask하는 것인데, 쓸모없는 연산이 늘어난다.
Efficient batch computation for shifted configuration
위의 Shifted Window 문제를 해결하기 위해, Padding 대신 Cyclic-Shift & Mask를 사용한다.
Window를 Shift하면 기존에 인접하지 않았던 FeatureMap이 같은 Window안에 존재하게 되는데
인접하지 않았던 영역에 대해서는 Mask를 적용해 Attention 연산에서 제외한다.
이를 통해 Window의 크기와 갯수가 고정되며, 쓸데없는 연산이 줄어 Padding대비 Low-Latency를 갖게된다.
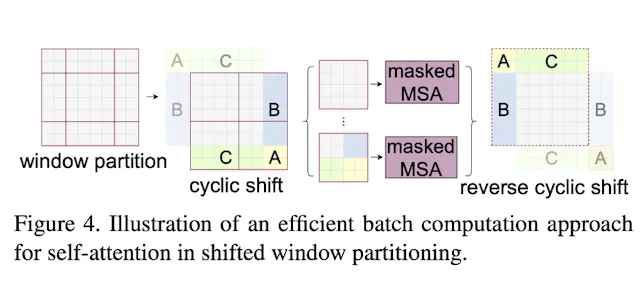
Cyclic Shift 란?
Relative position bias

( 는 Window 내부 Patch의 갯수)
초기에 Positional Encoding이 들어가는 일반적인 Transformer와 다르게 Swin은 Attention에서 각 Head마다 Relative Position Bias를 적용시켰다. Relative Position은 축마다 [-M+1, M-1] 범위에 존재하므로 이 Index를 이용한 Learnable Matrix를 형태로 만들어 사용했다.
Absolute Position도 사용해보았으나 미세하게 성능을 떨어트려 사용하지 않았다.
Architecture Variants
크기에 따라 Swin-T(x0.25), Swin-S(x0.5), Swin-B, Swin-L(x2.) 로 나누었다.
(T와 S는 각각 ResNet50, 101과 Cost가 비슷하다)
Window Size 은 7, Head dimension은 32, MLP Expansion은 4로 고정이며,
Config는 다음과 같다.

4. Experiments
BenchMark
Classfication : ImageNet
Object Detection : COCO + Cascade Mask R-CNN
Semantic Segmentation : ADE20K + UperNet
Ablation Study
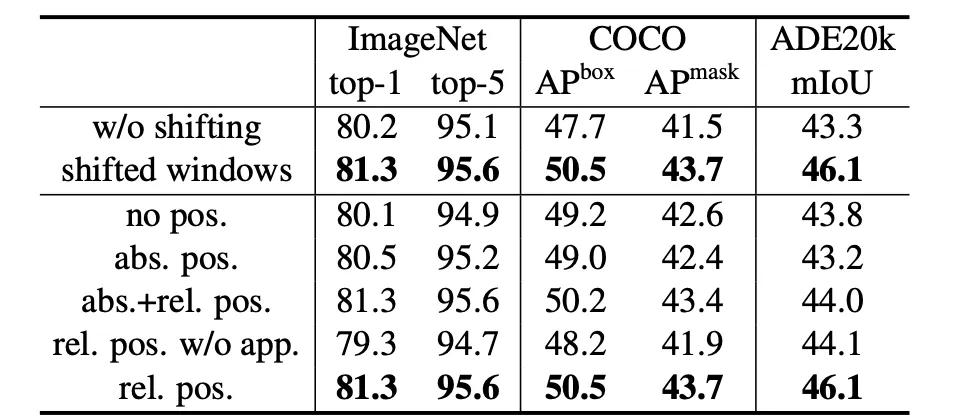
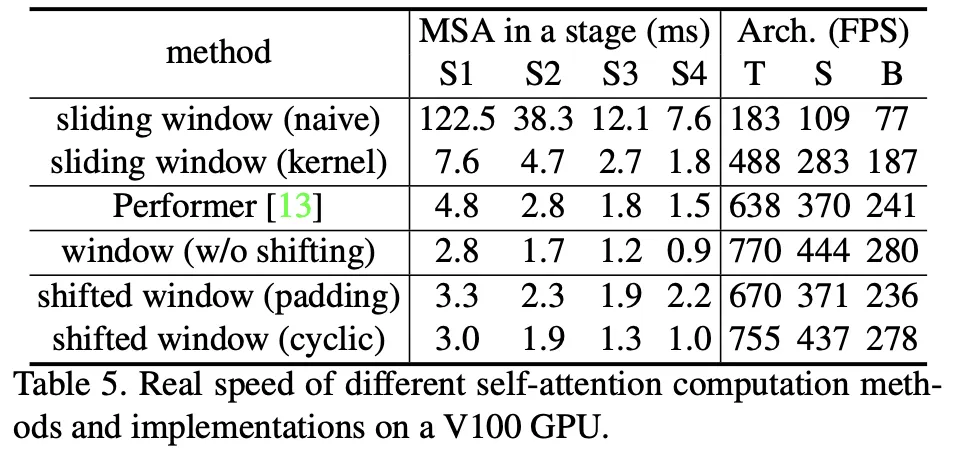
A. Shifted Windows
Shifted-Window를 사용했을때, 유의한 성능 향상을 보이며, Latency는 조금 증가한다.
B. Relative Position Bias
Relative Position Bias가 추가됐을때 가장 성능이 좋다. 흥미로운 점은 Absolute Position Embedding을 넣으면 안넣은 것 보다 Classficiation 성능이 개선되지만, Dense Task에선 성능이 떨어진다는 것이다.