


0. Introduction
모델링 관련 업무를 하다보면, 모델을 짜고 Loss를 설계하는데 걸리는 시간보다 데이터 관련 파이프라인을 짜는데에 더 긴 시간이 걸리는 경우가 많다. 그만큼 복잡하고 고된 작업이며 데이터 종류에 따라 전처리 방법도 다 다르다. 데이터의 규모가 커지면 전처리 파이프라인을 어떻게 짰느냐에 따라 훈련에 걸리는 시간이 천차만별이기도 하다.
tensorflow 를 사용한다면 tf.data API를 이용해 이런 파이프라인을 효율적으로 구축할 수 있다. 실제로 GPU 최적화된 Distributed Learning 같은 기능을 사용하려면 tf.data API 사용은 거의 필수적이다.
tf.data는 Element들의 Sequence인 tf.data.Dataset 을 사용한다. (Element를 이미지 처리 파이프라인을 예로 들어 설명하면, Element는 Train Record 한 줄, 즉 이미지와 레이블 한 쌍을 의미한다)
Dataset을 만드는 과정은 크게 두 과정으로 나눌 수 있다.
1.
Memory나 File에 저장된 Data source로 Dataset을 빌드하기
2.
Dataset을 변환해서 알맞은 전처리 하기
1. Basic Mechanics

Build Dataset
Data Source로부터 Dataset을 빌드하려면 (1) Memory에 데이터가 있거나 (2) FIle(TFRecord 권장)로 저장된 Data가 있으면 된다. 기본적인 Load 방법은 다음과 같다. (아래에서 더 자세히 설명한다.)
1.
Memory에 있는 경우 아래의 method를 이용해 Dataset을 만들 수 있다.
a.
tf.data.Dataset.from_tensors()
b.
tf.data.Dataset.from_tensor_slices() : 첫 번째 차원을 따라 슬라이싱 된다.
2.
TFRecord는 다음과 같은 method를 이용해 Dataset을 만들 수 있다.. tf.data.TFRecordDataset()
Data Transformation
Dataset Object의 method를 call하면 새로운 Dataset이 Return되는데, 이를 통해 Transformation을 수행할 수 있다. (1) Element 단위로 Transformation을 수행하고 싶으면 map() method를 이용하면 되고,
(2) Multi-Element 단위로 Transfomation을 수행하려면 batch() method를 이용하면 된다.
Dataset Structure
Dataset은 Elements의 Sequence를 만들어 내는데, 각 Element는 tf.TypeSpec으로 표현되는 요소가 될 수 있으며 Tensor, SparseTensor, RaggedTensor, Tensor, Dataset 타입이 그 예시이다.
Element의 Structure를 표현하기 위해 tuple, dict, NamedTuple, OrderedDict를 사용할 수 있다. 특이한점은 List를 사용할 수 없으며, 쓰고싶으면 tuple로 바꿔야한다는 점이다.
Dataset.element_spec property를 통해 Element Component를 확인할 수 있으며, 이 property는 Nested tf.TypeSpec을 Return한다.
2. Read Input Data (From Data Source)
Numpy Arrays (Common)
Memory에 Array를 다 올릴 수 있다면, tf.data.Dataset.from_tensor_slices() 를 이용해 간단하게 Dataset를 만들 수 있다.
•
주의할 점 : 이 방식으로 Dataset을 구성하면 TF Graph안에 constant로 데이터가 들어가게 된다. 작은 Dataset에 대해선 잘 작동하겠지만 여러번 Copy를 반복해서 Memory 낭비가 크다.
images, labels = train
images = images/255
dataset = tf.data.Dataset.from_tensor_slices((images, labels))
Python
복사
Python Generators
고려해야 하는 점은 다음과 같다.
1.
이때 입력은 Iterator가 아니라 Callable을 넣어주어야 하며
2.
Graph를 만들어 줘야해서 dtype을 지정해 주어야 한다.
3.
많은 tf연산이 unknown shape에 대해 연산을 못하므로, output_shapes를 지정해주는것이 권장된다.
•
주의할 점 : Generator를 이용하는 방법은 편리하지만, 확장성이 제한적이다. 특히 Generator를 생성한 Process 내부에서 실행시켜야 하며, GIL의 영향도 받는다
ds_counter = tf.data.Dataset.from_generator(count, args=[25], output_types=tf.int32, output_shapes = (), )
Python
복사
TFRecord Data
TFRecord는 많은 TF Application에서 Train Data를 처리하는데 사용하고 있는 Binary Format이다. TFRecord는 tf.data.TFRecordDataset()를 이용해 Dataset으로 변환시킬 수 있다. 대부분의 프로젝트에서 TFRecord의 Record를 tf.train.Example를 Serialize 해서 사용한다. 따라서 decode하는 절차가 필요하다.
dataset = tf.data.TFRecordDataset(filenames = [fsns_test_file])
raw_example = next(iter(dataset))
parsed = tf.train.Example.FromString(raw_example.numpy())
Python
복사
Text Data
tf.data.TextLineDataset()은 하나 이상의 Text 파일에서 Line단위로 텍스트를 추출하는 좋은 방법이다.
•
주의할 점 : TextLineDataset은 모든 Line에 대해 동작함으로 Header나 Comment가 들어가있는 Dataset에선 부적합할 수 있다. 이런 데이터는 skip()이나 filter()method로 제거할 수 있다.
CSV Data
CSV는 Tabular Data를 Text로 저장하는 일반적인 Format이다. Array처럼 메모리에 다 올릴 수 있으면 tf.data.Dataset.from_tensor_slices()를 이용할 수 있다. 더 큰 CSV는 Disk에서 불러오는 방법이 필수적이다. experimental.make_csv_dataset() 함수를 이용해 File Set을 읽을 수 있으며, tabular Data를 처리하기 위한 다양한 Method를 제공한다. 자세한 내용
Sets of files
여러 File로 분할된 Set도 tf.data.Dataset.from_list_files()와 tf.io.read_file을 이용해 Dataset으로 만들 수 있다.
3. Data Transformation
Batching Dataset
Simple Batching
Dataset을 쉽게 Batch 처리하는 방법은 Dataset.batch() method를 이용하는 것이다. 이 때 각 Component에 대하여 모든 Element는 정확히 똑같은 Shape을 가지고 있어야 하며, 결과물은 각 Element를 첫 번째 차원에 대하여 Stack한 것과 같다.
•
주의 사항 : Batching Dataset의 Shape이 None으로 나올때가 있는데 이는 데이터 갯수가 Batch size로 나누어 떨어지지 않을때 발생한다. drop_remainder 인수로 남은부분을 버림으로서 해결해줄 수 있다.
inc_dataset = tf.data.Dataset.range(100)
dec_dataset = tf.data.Dataset.range(0, -100, -1)
dataset = tf.data.Dataset.zip((inc_dataset, dec_dataset))
batched_dataset = dataset.batch(4)
for batch in batched_dataset.take(4):
print([arr.numpy() for arr in batch])
batched_dataset
batched_dataset = dataset.batch(7, drop_remainder=True)
batched_dataset
Python
복사
Batching with Padding
위의 예시는 모든 Tensor가 같은 Shape을 가져야 한다. 하지만 Sequence Model을 포함한 많은 모델이 Input의 Shape(Size)가 가변적이다. 이를 다루기 위해 Dataset.padded_batch() method를 사용할 수 있다. padded_shapes 인수로 차원을 지정해주면, 그에 맞게 패딩된 결과물이 Batch 된다. metohd의 다양한 인자를 이용해 차원별로 다른 Padding을 해줄 수 도 있으며, 0 대신 다른 값으로도 가능하다.
dataset = tf.data.Dataset.range(100)
dataset = dataset.map(lambda x: tf.fill([tf.cast(x, tf.int32)], x))
dataset = dataset.padded_batch(4, padded_shapes=(None,))
for batch in dataset.take(2):
print(batch.numpy())
print()
Python
복사
Training Workflow (Repeat & Shuffle)
Dataset을 여러 Epoch에 대해 반복하려면 Dataset.repeat() Method를 사용하면 된다. count 인수를 비워두면 끝없이 반복된다. 주의할 점은 repeat()은 Epoch의 시작과 끝에 대해 전달받지 않으므로, Epoch에 대한 분리가 필요할 경우 repeat전에 Batch를 넣어 주어야 한다.
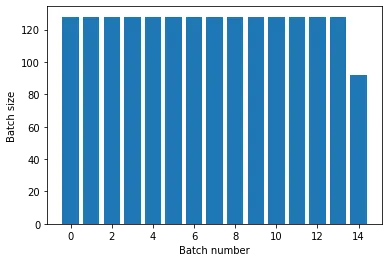
repate().batch()
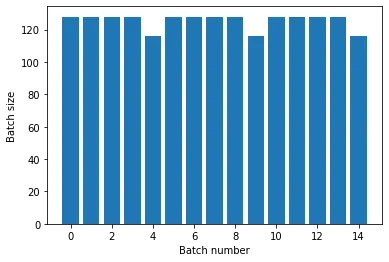
batch().repeat()
Dataset을 섞으려면 Dataset.shuffle() method를 사용하면 된다. shuffle()는 특정 buffer안에서 Uniformly Random하게 샘플링하는 식으로 동작하는데, 이때 인수로 정해줄 수 있는 buffer_size가 Dataset Size보다 작으면 데이터셋이 완벽하게 섞이지 않을 수 있다.
예를들어 10,000 개의 Element가 있는 Dataset에 대하여 buffer_size를 1,000으로 shuffle하면 첫 1000개의 Element에서 하나를 선택하고, 그 다음은 1~1001개의 Element에서 선택하고 이런 식으로 동작한다. 너무 큰 Dataset에 대해 그것만큼 큰 buffer_size를 설정하면 Memory문제가 생길 수 있다. 이럴떈 여러 파일에 걸친 Dataset.interleave()를 이용하는 것을 권장한다.
batch(), repeat()와 마찬가지로 순서가 중요하다. 예를들어
1.
shuffle().repeat() : Epoch내의 모든 Element를 뽑고나서 다음 Epoch으로 이동한다.
2.
repeat().shuffle() : Epoch의 경계가 섞인 상태로 buffer가 채워진다.
PreProcessing Data (Map)
Dataset을 전처리 하기 위해 Dataset.map()을 사용할 수 있다. map()은 단일 Element Tensor를 가져와 다른 Tensor를 반환한다. 이때 성능상의 이유로 map 내부 연산은 TF Ops를 사용하는게 권장되는데, 가끔은 외부 Python Library를 사용해야할 때가 있다. 이때는 map안에서 tf.py_function() 연산으로 래핑하면 된다. 이때 shape와 dtype을 꼭 명시해주어야 한다.
import scipy.ndimage as ndimage
def show(image, label):
plt.figure()
plt.imshow(image)
plt.title(label.numpy().decode('utf-8'))
plt.axis('off')
def random_rotate_image(image):
image = ndimage.rotate(image, np.random.uniform(-30, 30), reshape=False)
return image
def tf_random_rotate_image(image, label):
im_shape = image.shape
[image,] = tf.py_function(random_rotate_image, [image], [tf.float32])
image.set_shape(im_shape)
return image, label
rot_ds = images_ds.map(tf_random_rotate_image)
for image, label in rot_ds.take(2):
show(image, label)
Python
복사