

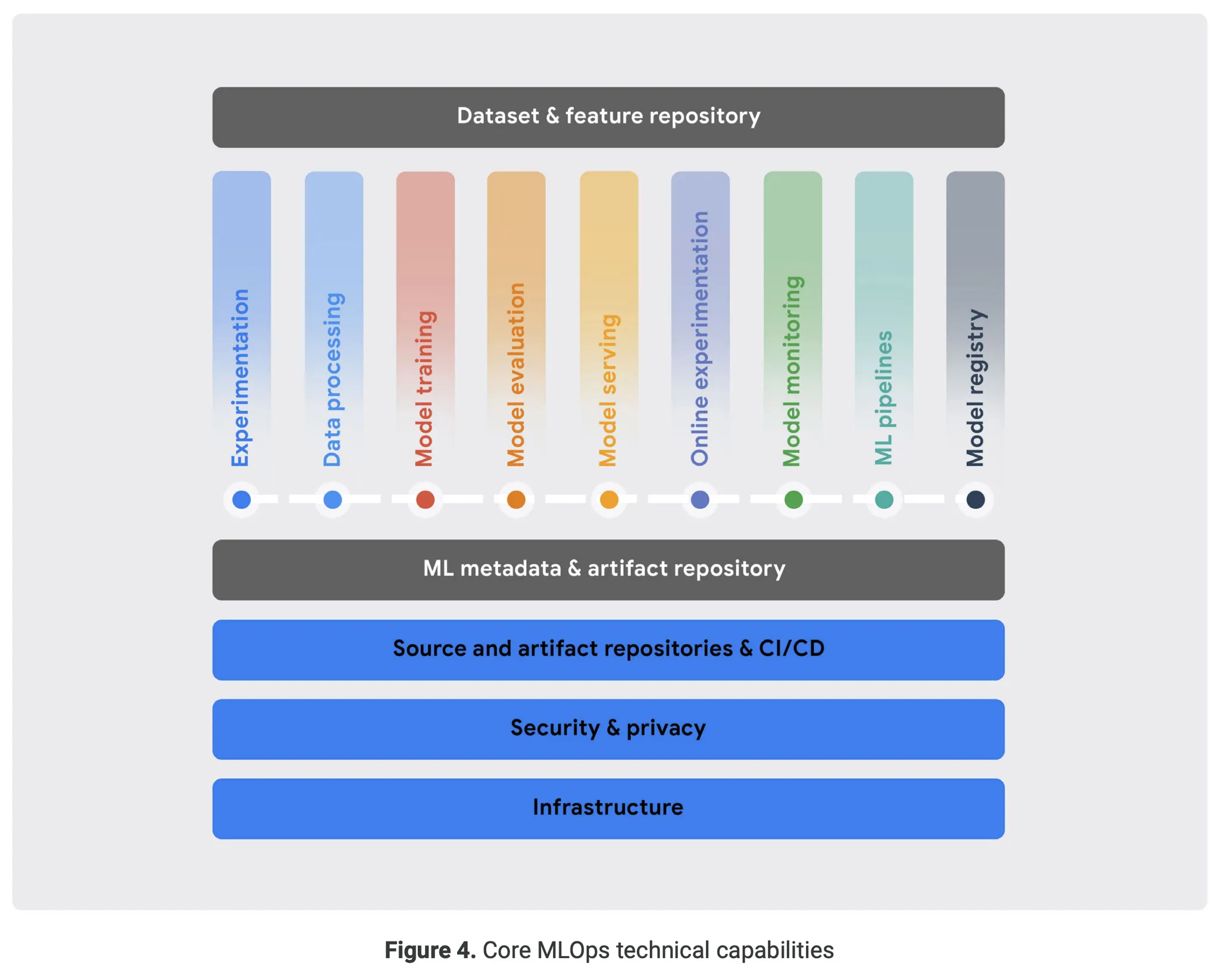
위 표는 구글이 2021년 발표한 MLOps의 핵심 Component들이다. 각 Component의 역할은 다음과 같다.
Dataset and Feature Repository
ML Data Asset을 통합적으로 일컫는 개념이며 전처리와 Feature Engineering을 지원하는 컴포넌트이다. Data Asset은 Raw Data가 될 수도 있고 Feature가 될 수도 있다. 아래의 기능을 제공한다.
•
데이터에 대한 공유, 검색, 재사용, 버전관리
•
정형, 비정형 데이터 처리
•
스트리밍, Online Inference에 대한 Real-Time 처리
Experimentation
EDA, 프로토타입 모델링, 학습코드 작성을 지원하는 컴포넌트이다. 아래의 기능을 제공한다.
•
Notebook 환경 지원
•
Git 같은 툴로 버전 관리
•
Data, Hyper-Parameters, Metric을 기록해 실험을 추적, 비교, 재현
•
Data와 Model에 대한 분석과 시각화
Data Processing
모델 개발, 학습, 서빙 단계에서 대량의 데이터를 변환하고 준비시키는 컴포넌트이다. 아래의 기능을 제공한다.
•
광범위한 데이터 흐름 연결
•
다양한 구조와 형태의 데이터를 Encoder - Decoder 형태로 처리
•
정형, 비정형 데이터에 대한 다양한 처리
•
Batch, Stream 데이터 처리를 통해 학습과 서빙에 데이터 공급
Model Training
모델 학습을 효율적으로 실행시키는 컴포넌트이다. 아래의 핵심 기능을 제공한다.
•
일반적인 ML Framework, Custom Runtime 환경을 지원
•
Multi GPU / Worker를 이용한 대규모의 분산 학습을 지원
•
HyperParameter Tuning, 최적화를 지원
•
(이상적) AutoML도 지원
Model Evaluation
실험, 서빙단계에서 모델의 효과를 확인하는 컴포넌트이다. 아래의 핵심 기능을 제공한다.
•
Evaluation Dataset에 대한 Scoring
•
여러 Continous Training 에 따른 성능 추적
•
모델 Metric 시각화 및 비교
Model Serving
Production 환경에 모델을 배포하고 서빙하는 컴포넌트이다. 아래의 핵심 기능을 제공한다.
•
Online 환경의 Near-Real-Time 서빙, Offline 환경의 High-Throughput Batch 서빙
•
상용 ML Serving Framework와의 통합
•
복잡한 형태의 Inference 연산 지원
•
변동이 큰 Traffic를 처리하기 위한 Auto-Scaling
•
Request와 Response에 대한 Logging
Online Experimentation
새롭게 훈련된 모델이 Production에서 어느정도의 성능을 보일지 미리 테스트 해보는 컴포넌트이다.
배포할 모델을 결정하기 위해 Model Registry와 통합되어 있어야 하며, 아래의 기능을 제공한다.
•
Canary, Shadow 배포, A/B Test, Multi-Armed Bandit Test
Model Monitoring
모델이 Production에서 제대로 작동하는지 모니터링 하는 컴포넌트이다. 아래 기능을 제공한다.
•
Latency, Resource Utilization과 같은 효율 Metric을 측정
•
Data Skews(Ex: data, concept drift)탐지
•
Model Evaluation과 통합되어 지속적으로 배포된 모델의 성능 모니터링
ML Pipeline
복잡한 ML 훈련과 추론 작업을 구성,제어,자동화하는 컴포넌트이다. 아래 기능을 제공한다.
•
여러 트리거에 따른 Pipeline 실행
•
Metadata Tracking 컴포넌트와 함께 Pipeline의 입력값과 결과물을 기록할 수 있어야 한다.
•
ML Task를 위한 Built-In Component와 Custom Component를 실행시킬 수 있어야 한다.
Model Registry
중앙 Repository에서 ML 모델의 생명 주기를 관리하는 컴포넌트이다. 아래 기능을 제공한다.
•
학습, 배포된 모델을 등록, 추적, 버저닝할 수 있어야한다.
•
배포를 위해 Runtime Depedency들과 Metadata를 저장하고 있어야 한다.
ML Metadata and Artifact Tracking
MLOps Lifecycle에서 각 단계마다 다양한 종류의 산출물(Artifact)가 생성되는데, 이것들을 정보(Metadata)와 함께 관리하는 컴포넌트이다. 아래 핵심 기능을 제공한다.
•
ML Artifact의 히스토리를 추적할 수 있어야 한다.
•
실험 Parameter Config를 추적하고 공유할 수 있어야 한다.
•
다른 MLOps 기능과의 통합이 가능해야한다.
MLOps System은 위의 Components를 유기적으로 동작시킴으로서 구현할 수 있다. Kubeflow같은 대규모 오케스트레이션 시스템을 이용해 통째로 구현하는 방법도 있지만, (경험상)팀의 니즈와 MLOps 이해도에 맞게 필요한 부분부터 단계별로 구축해나가는 것이 도입과 전환이 쉽다.