
Keyword
Semantic Segmantation, Dense Prediction
SuperPixel
Abstract
Convolution은 계층적 Feature를 만들어내는 강력한 Visual Model이다. FCN은 Covolution으로만 Pixel to Pixel / End to End 훈련을 시켜 Semantic Segmentation에서 SOTA 이상의 성능을 달성한다.
Introduction

FCN
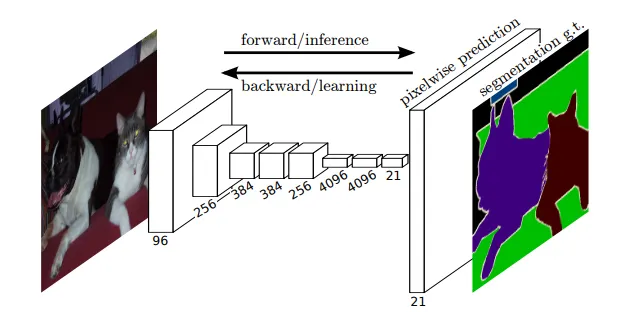
FCN은 (1) Pixel-Wise Prediction을 (2) Supervised Pre-train하는 구조이다. 기존 Backbone을 FCN구조로 바꾸면 임의 크기 입력에서 Dense Output을 예측한다. 이때 Network의 Upsampling Layer가 Pixel-Wise Output 예측을 가능케 한다. 이 방식은 연산 자체도 효율적이며, 복잡한 전처리 후처리(Ex: Super-Pixel ..)를 적용할 필요가 없다.
Semantic Segmentation
Semantic Segmentation은 Semantics와 Location을 둘다 수행해야 한다. 즉 Global한 정보와 Local 정보가 둘 다 있으면 좋다.
일반적으로 CNN은 Local-To-Global Pyramid 형태로 피쳐를 인코딩한다. FCN은 Skip Connection을 이용해 Local한 피쳐와 Global한 피쳐를 합쳐서 사용한다.
Conclusion
1.
FCN은 정보가 풍부한 모델이며, Classficiation ConvNets의 특정 하위 분류이다.
2.
Classification ConvNets를 FCN으로 확장하고
3.
Multi-Resolution Layer를 혼합하는 구조를 추가하면
4.
Semantic Segmantation에서 (기존 연구 대비) 성능과 연산 효율이 드라마틱하게 개선된다.
Figures

Summary
Adapting Classifiers for Dense Prediction
FCN이 발표될 당시 기존 Classification Backbone(AlexNet 등..)은 마지막에 Fully-Connected Layer가 붙어있었다. 이런 구조는 Convolution으로 얻어낸 (1) Spatial Coordinate Feature를 날리는 동시에 (2) 모델로 하여금 고정된 Input-Size를 갖게 만드는 단점이 있었다. (Fully-Connected로 들어가는 Flatten된 Feature의 크기가 일정해야하므로)
이런 단점이 Classificiation Backbone을 Dense-Prediction에 바로 사용하기 어렵게 만들었다. 그러나 잘 생각해 보면, 마지막 Fully-Connected는 Input 영역을 전부 커버하는(1x1) Convolution과 동일하다고 볼수도 있다. 이 아이디어를 응용해 마지막 Fully-Connected를 Convonlution으로 바꾸면 어떤 Input Size든 받을 수 있는 Network를 만들수 있다.
Upsampling
ConvNets을 거치며 Image에서 FeatureMap 형태로 변환되는데, Resoultion은 점점 작아지고 Channel은 점점 커진다. Dense Prediction을 하기 위해선, 작아진 Resolution을 키워주어야 한다.
이를 Upsampling 이라고 부른다. FCN에서는 Interpolation과 Deconvolution(Transposed) 두 가지 방법을 제시하는데, End-to-End 관점에서 학습이 가능하며, 효율적인 Decovolution을 사용한다.
Segmentation Architecture
ILSVRC에서 훈련된 Clssifier를 FCN으로 변환하고, Deconv를 이용해 Upsampling한 구조를 사용했다. PASCAL-VOC Dataset에 대해 Pixelwise Loss로 훈련하고 Test했다. 이렇게만 해도, 별도의 추가 조정없이도 당대의 Semantic Segmentation SOTA의 Metric를 상회하는 결과를 보여주었다. (FCN-32s)
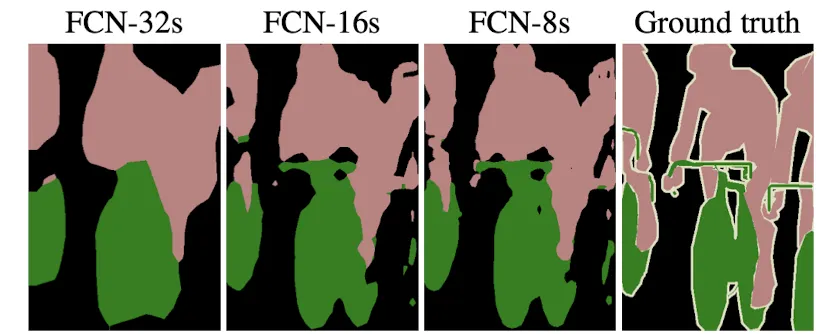
Metric 자체는 강력했지만, 막상 결과물을 보면 Output이 매우 Coarse한 문제가 있다. 이는 생각해보면 당연한 문제이다. Deeper-Layer Feature를 단일로 Deconvolution 한다면, 갖고있는 정보가 전부 Global-Level이므로 경계를 완벽히 나눌 수 없는 것이다.
일반적인 Backbone의 경우 입력 Image의 Resolution과 마지막 Feature Map의 Resolution이 32배 차이가난다. 따라서 위의 구조를 32 Pixel stride라고 정의하고 FCN-32s라고 명명한다.
Skip and Combine
FCN은 Lower-Layer의 정보와 Deeper Layer의 정보를 합쳐 위의 문제를 해결한다. 이 둘을 합침으로서 정보가 훨씬 풍부해지며, Global한 관점에서 Local Prediciton이 가능해진다.
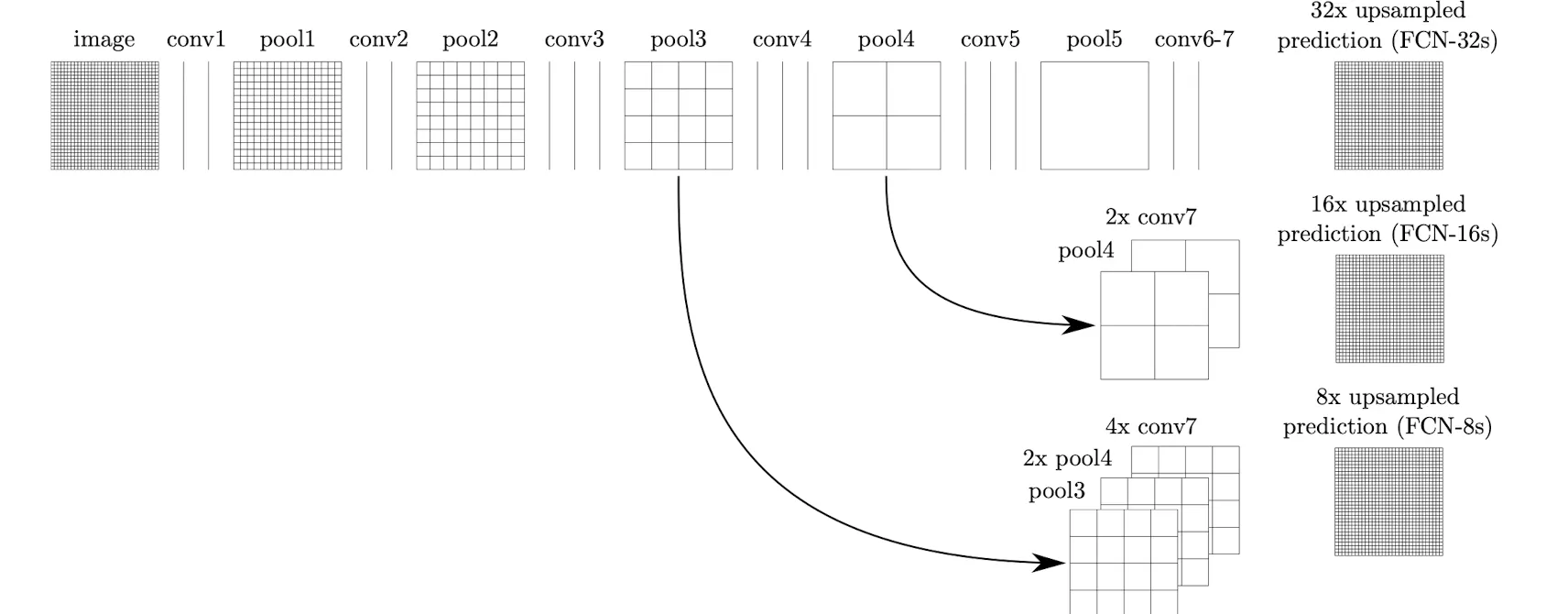
(여기서 Upsampling은 Interpolation으로 초기화된 Learnable Deconv Layer를 이용한다)
FCN-16s
1.
pool4에 1x1 Conv를 이용해 Class 갯수만큼 Channel을 만든다. (14,14,class)
2.
conv7에 1x1 Conv + Deconv를 이용해 2배 Resolution으로 Upsampling한다 (14,14,class)
3.
두 FeatureMap을 더한뒤 16배의 Resolution으로 Upsampling한다 (224,224,class)
FCN-8s
1.
pool3에 1x1 Conv를 이용해 Class 갯수만큼 Channel을 만든다. (28,28,class)
2.
pool4에 1x1 Conv를 이용해 Class 갯수만큼 Channel을 만든다. (14,14,class)
3.
conv7에 1x1 Conv + Deconv를 이용해 2배 Resolution으로 Upsampling한다 (14,14,class)
4.
pool4 결과물과 conv7 결과물을 더한뒤 2배 Resolution으로 Upsampling한다. (28,28,class)
5.
4번 결과물과 pool3 결과물을 더한뒤 8배 Resolution으로 Upsampling한다. (224,224,class)
Experiment
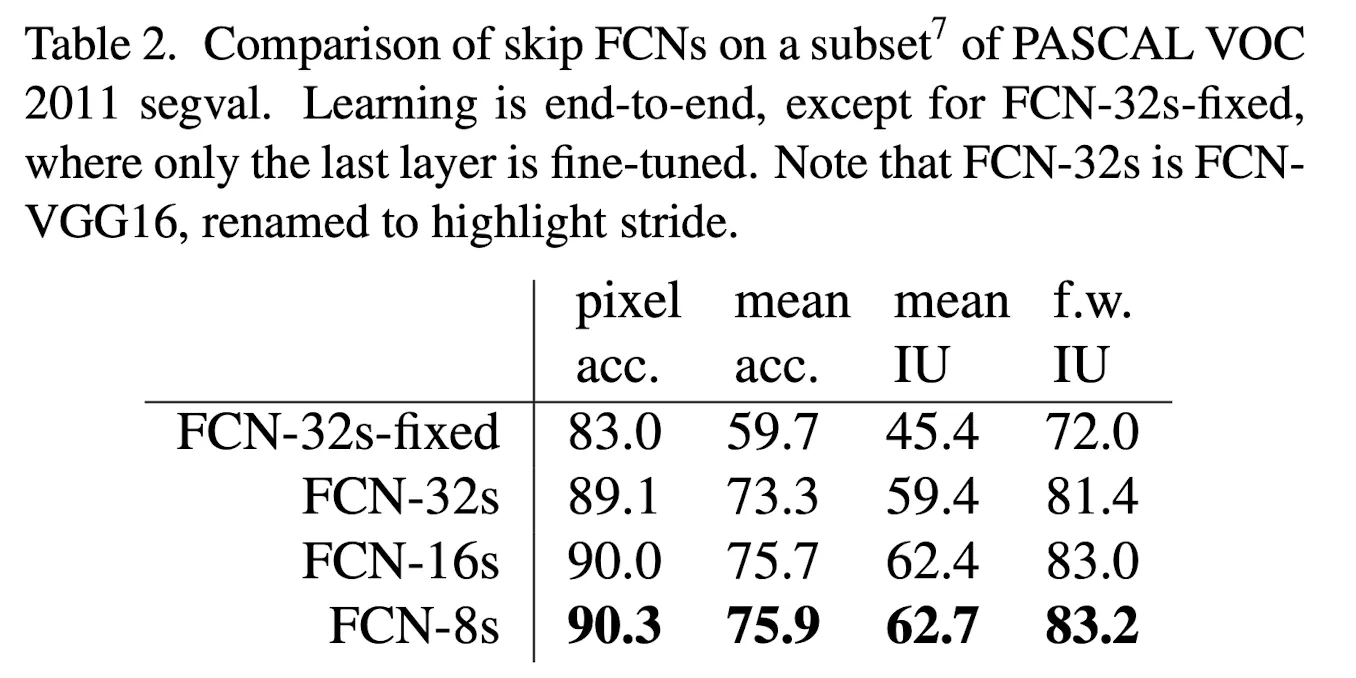
Skip and Combine의 효과
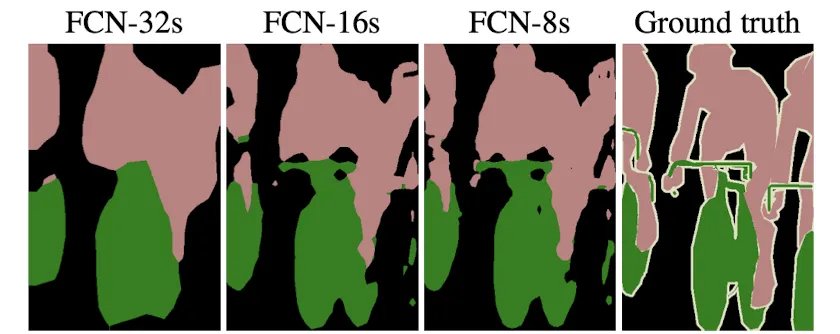
•
다양한 Scale의 FeatureMap을 사용해 단계적으로 Upsampling을 할수록 성능이 향상된다.
다음 질문에 답해보세요.
What did the author(s) try to accomplish?
1.
기존 Classifier용도로 훈련된 Backbone을 Dense Prediction에 튜닝하는 방법론을 제시했다.
2.
Semantic Segmentation 수행을 위해, Local & Global 정보를 다 가져오는 방법론을 제시했다.
What were the key elements of the approach?
1.
기존 Classifier용도로 훈련된 Backbone을 Dense Prediction에 튜닝하는 방법론을 제시했다.
•
Backbone의 Fully-Connected를 1x1 Conv로 바꾸어 주었다.
•
이를 통해 가변크기 입력에도 작동하는 Backbone이 되었으며, Spatial 정보도 살려주었다.
2.
Semantic Segmentation 수행을 위해, Local & Global 정보를 다 가져오는 방법론을 제시했다.
•
Skip & Combine을 이용해, 얕은 층의 Feature와 깊은층의 Feature를 합쳐서 사용했다.
•
Deconv를 이용해 Resolution을 맞춰주고, Sum해 주는 방법을 이용해 합쳤다.
What can you use yourself?
•
대부분의 Dense Prediction Task 논문이 FCN를 레퍼런스로 사용하고 있기에, Segmentation Task의 논문을 읽기 위해 도움이 될 것 같다.
What other references do you want to follow?
1.
Deconv관련 이해가 더 필요하다.
참고한 글: